算法-KMP串匹配
字符串匹配
http://www.cnblogs.com/jingmoxukong/p/4343770.html
模式匹配是数据结构中字符串的一种基本运算,给定一个子串,要求在某个字符串中找出与该子串相同的所有子串,这就是模式匹配。
假设P是给定的子串,T是待查找的字符串,要求从T中找出与P相同的所有子串,这个问题成为模式匹配问题。P称为模式,T称为目标。如果T中存在一个或多个模式为P的子串,就给出该子串在T中的位置,称为匹配成功;否则匹配失败。
KMP 算法
http://kb.cnblogs.com/page/176818/
字符串匹配是计算机的基本任务之一。
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。
----- 我的理解 ----
此算法的思想是, 当出现模式匹配未完全时候, 利用已经匹配的部分模式中的字符串(蕴含的)信息, 尽量将模式匹配的开始位置向右边移动。
----- 已经匹配的部分模式中字符串蕴含的信息 ----
一般将这个信息叫部分匹配表, 所谓部分, 就是未完全匹配模式字符串的含义, 未匹配命中, 只匹配了模式串的前面一部分子串。
正如上面所说,部分匹配串, 就是 模式串的一个前缀,
如果此部分匹配串中, 如果存在 一个子串, 此子串既是部分模式串的 前缀, 同时也是 部分模式串的 后缀, 同时这个子串是 同类子串中最长的一个, 则称 此子串为 此部分匹配串的 最大前缀。
当模式匹配过程发生字符匹配失败, 则将 模式字符串 对应主串起始位置(A), 移动到 模式字符串中已经部分匹配子串中 最大前缀的对应的后缀开始 位置(B), 并从失败的位置(C)继续开始比对。
主串中从A到B的位置(不包括B), 对于模式字符串, 已经不需要再进行比较, 因为 这些位置, 按照最大前缀的定义,不能满足部分匹配串的 最大前缀的, 更何谈匹配整个模式串!
主串中从B到C的位置(不包括C), 对于模式字符串, 对于B位置, B-C正好对应 部分匹配字符串的 最大前缀, 所以也不需要 进行匹配。
-------- 阮一峰 实例化解释 部分匹配表的生成 --------------
下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
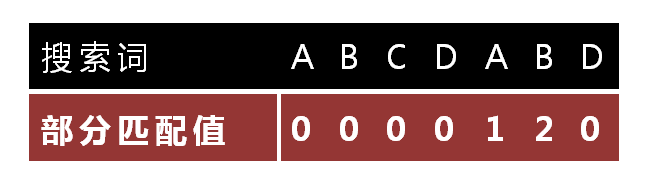
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
----- 理解 ------
如果按照这种实例所示, 采用列举比对, 计算最大前缀, 则会导致很耗时, 属于穷举法。
模式字符串 为 s[1, n]
对于部分匹配子串 s[1, m], 其中 m = [1, n]
for i=m-1,1,-1 do
if compare(s[1, i], s[m-i+1,m]) == 0 then
// find max prefix len
end
end
最坏时间为 n*n
------- 使用归纳法计算 部分匹配表 则更加有效率。--------
假设 s[1, q] 的 最大前缀为 k == f(q), 则 s[1, k] == s[q-k+1, q]
则 对于 s[1, q+1], 我们来求 其最大前缀f(q+1)
if s[q+1] == s[k+1] then
f(q+1) = f(q) + 1 = k + 1
else
//s[1, k] 是不行了, 继续从s[1, k]中找到其最大前缀, 用此最大前缀后的字符与s[q+1]比较
if s[q+1] == s[f(k)+1] then
f(q+1) = f(k) + 1 = f(f(q)) + 1
else
// s[1, f(k)] 也不行了, 。。。。
end
end
C代码实现
https://github.com/fanqingsong/code-snippet/blob/master/C/kmp_string_matcher/kmp_string_matcher.c
E_BOOL_TYPE string_is_head_of_string(char* headStr, char* string, int* pfailPos) { char* pHeadStr = NULL; char* pString = NULL; char chHead = 0; char chString = 0; int index = 0; if (!headStr || !string) { MyPrintf("arg is null"); return FALSE; } pHeadStr = headStr; pString = string; while( TRUE ) { chHead = *pHeadStr; chString = *pString; // headStr is over, now result is true if ( chHead == 0 ) { return TRUE; } // string is over firstly, return false if ( chString == 0 ) { *pfailPos = index; return FALSE; } // headStr is not a head of string if ( chHead != chString ) { *pfailPos = index; return FALSE; } pHeadStr++; pString++; index++; } } void calcPrefixlenByIndex(char* substr, int substrPrefix[], int iNum) { int PrefixLen = 0; MyPrintf("iNum = %d", iNum); if ( iNum == 0 ) { substrPrefix[iNum] = 0; MyPrintf("iNum = %d substrPrefix[iNum]=%d", iNum, substrPrefix[iNum]); return; } // calc [0, iNum-1] string prefix len, saving to substrPrefix[iNum-1] calcPrefixlenByIndex(substr, substrPrefix, iNum-1); // according to [0, iNum-1] string prefix, we deduce [0, iNum] string prefix PrefixLen = substrPrefix[iNum-1]; do { // if the char after the [0, iNum-1] string prefix is EQUAL to the char at substr[iNum], // then the the [0, iNum] string prefix len = the [0, iNum-1] string prefix len + 1 // PrefixLen+1-1 notation mean index from 0, while PrefixLen+1 mean index from 1 if ( substr[PrefixLen+1-1] == substr[iNum] ) { substrPrefix[iNum] = PrefixLen + 1; break; } // else calc from the prefix of the [0, iNum-1] string prefix else { PrefixLen = substrPrefix[PrefixLen]; } }while ( PrefixLen > 0 ); MyPrintf("iNum = %d substrPrefix[iNum]=%d", iNum, substrPrefix[iNum]); } void compute_string_prefix(char* substr, int substrPrefix[], int maxPrefixEleNum) { int substrlen = 0; substrlen = strlen(substr); if (substrlen > maxPrefixEleNum) { return; } calcPrefixlenByIndex(substr, substrPrefix, substrlen-1); } #define MAX_PREFIX_ELE_NUM 1024 int kmp_matcher(char* string, char* substr) { char* cursor = NULL; int index = 0; int subLen = 0; int stringLen = 0; int maxPos = 0; int substrPrefix[MAX_PREFIX_ELE_NUM] = {0}; int failPos = 0; int partialMatchedPos = 0; int maxPrefixLen = 0; // pointer to the inner postion of cursor and substr char* pCursor = NULL; char* pSubstr = NULL; if (!string || !substr) { MyPrintf("arg is null"); } subLen = strlen(substr); stringLen = strlen(string); maxPos = stringLen - subLen + 1; // substrPrefix is string prefix of substr // scope : 1-substrlen // the index i element is the max prefix length of substr[1, i] compute_string_prefix(substr, substrPrefix, MAX_PREFIX_ELE_NUM); index = 0; maxPrefixLen = 0; while ( index < maxPos ) { cursor = string + index; pCursor = cursor + maxPrefixLen; pSubstr = substr + maxPrefixLen; if ( string_is_head_of_string(pSubstr, pCursor, &failPos) ) { return index; } else { // failPos scope: 0-substrlen-1 // failPos is substr comparing char postion that do not match cursor string // then substr[0, partialMatchedPos] is the matched part partialMatchedPos = maxPrefixLen + failPos - 1; // substr[0] is not matched if ( failPos == 0 ) { // string compare from next position index ++; // next comparation have not to consider prefix maxPrefixLen = 0; } else { // the max prefix length of partial matched string, ie substr[0, partialMatchedPos] maxPrefixLen = substrPrefix[partialMatchedPos]; index += partialMatchedPos - maxPrefixLen; } } } return -1; }