Spark SQL编程指南(Python)
前言
Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询。它的核心是一个特殊类型的Spark RDD:SchemaRDD。
SchemaRDD类似于传统关系型数据库的一张表,由两部分组成:
Rows:数据行对象
Schema:数据行模式:列名、列数据类型、列可否为空等
Schema可以通过四种方式被创建:
(1)Existing RDD
(2)Parquet File
(3)JSON Dataset
(4)By running Hive SQL
考虑到Parquet File尚未在平台开始使用,因此暂时仅讨论其它三项。
注意:
Spark SQL is currently an alpha component.
SQLContext(HiveContext)
Spark SQL的入口点为SQLContext,SQLContext的初始化依赖于SparkContext,代码示例如下:
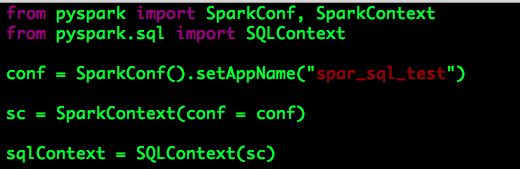
SQLContext目前仅仅使用一个简单的SQL解析器,功能有限,而且目前很多的数据仓库是建立在Hive之上的,因此Spark为我们提供了另一个选择:HiveContext。
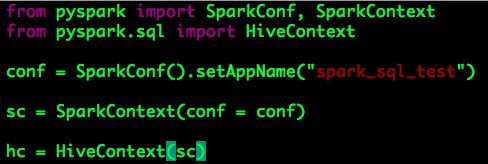
HiveContext使用相对比较完善的HiveQL解析器,可以使用HiveUDF,可以访问现有Hive数据仓库中的数据,且适配SQLContext的所有数据源,推荐使用。
HiveContext初始化过程相似,如下:
数据源
Spark SQL(SchemaRDD)的数据源可以简单理解为就是普通的Spark RDD,所有可以应用于Spark RDD的操作均可以应用于SchemaRDD;此外,SchemaRDD还可以“注册”为一张临时表,然后通过SQL(Hive SQL)分析其中的数据(实际就是Spark RDD关联的数据)。
SchemaRDD
SchemaRDD的数据源实际就是Spark RDD,但是Spark RDD与SchemaRDD还是有区别的,Spark RDD相对于SchemaRDD而言缺失“Schema”,因此Spark提供两种方式完成Spark RDD到SchemaRDD的转换,实际就是为Spark RDD应用“Schema”。
(1)使用反射推断Schema
如果一个Spark RDD的数据类型为Row,则Spark可以通过反射推断出该Spark RDD的Schema,并将其转换为一个SchemaRDD。
Spark使用反射推断某个Spark RDD的Schema时,仅仅使用这个Spark RDD的第一条数据(Row),因此必须保证这条数据的完整性。
Row的构建过程需要一个键值对列表,
Row(id = 1, name = "a", age = 28)
这个键值对列表已经明确定义出数据行的列名、列值,推断仅作用于列类型。
代码示例
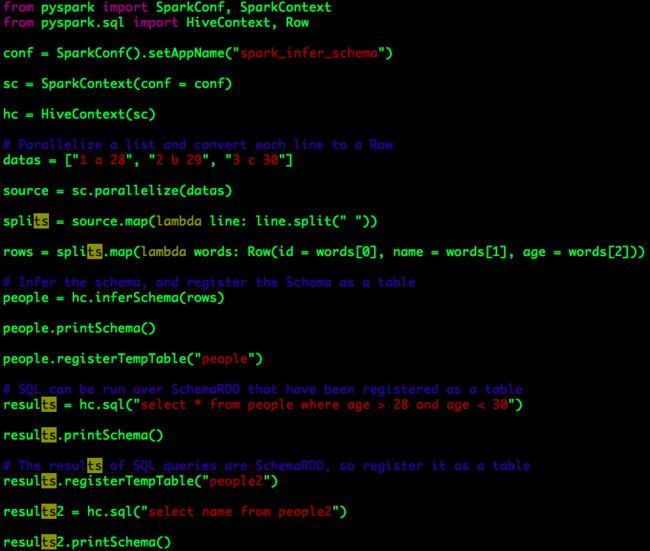

处理逻辑可以分为以下几步:
a. 创建一个字符串列表datas,用于模拟数据源;
b. 对datas执行“parallelize”操作,将其转换为Spark RDD source,数据类型为字符串;
c. 将Spark RDD source中的每一条数据进行切片(split)后转换为Spark RDD rows,数据类型为Row;
至此Spark RDD rows已经具备转换为SchemaRDD的条件:它的数据类型为Row。
d. 使用HiveContext推断rows的Schema,将其转换为SchemaRDD people;
通过people.printSchema(),我们可以查看推断Schema的结果:

e. 将SchemaRDD people注册为一张临时表“people”;
f. 执行SQL查询语句:select * from people where age > 28 and age < 30,并将查询结果保存至Spark RDD results,通过results.printSchema()的输出结果:

可以看出Spark RDD results实际也是SchemaRDD,因此我们可以继续将其注册为一张临时表;
g. 将SchemaRDD results注册为一张临时表“people”,并执行SQL查询语句:select name from people2,并将查询结果保存至Spark RDD results2,通过f我们可以知道results2实际也是SchemaRDD,results2.printSchema()的输出结果:
SchemaRDD results2的数据类型为Row,受到查询语句(select name)的影响,其仅包含一列数据,列名为name。
h. SchemaRDD也可以执行所有Spark RDD的操作,这里我们通过map将results2中的name值转换为大写形式,最终的输出结果:
上述示例说明以下三点:
a. 我们可以将一个数据类型为Row的Spark RDD转换为一个SchemaRDD;
b. SchemaRDD可以注册为一张临时表执行SQL查询语句,其查询结果也是一个SchemaRDD;
c. SchemaRDD可以执行所有Spark RDD的操作。
(2)通过编码指定Schema
使用反射推断Schema的方式要求我们必须能够构建一个数据类型为Row的Spark RDD,然后再将其转换为SchemaRDD;某些情况下我们可能需要更为灵活的方式控制SchemaRDD构建过程,这正是通过编码指定Schema的意义所在。
通过编码指定Schema分为三步:
a. 构建一个数据类型为tuple或list的Spark RDD;
b. 构建Schema,需要匹配a中的tuple或list;
c.将b中的Schema应用于a中的Spark RDD。
代码示例
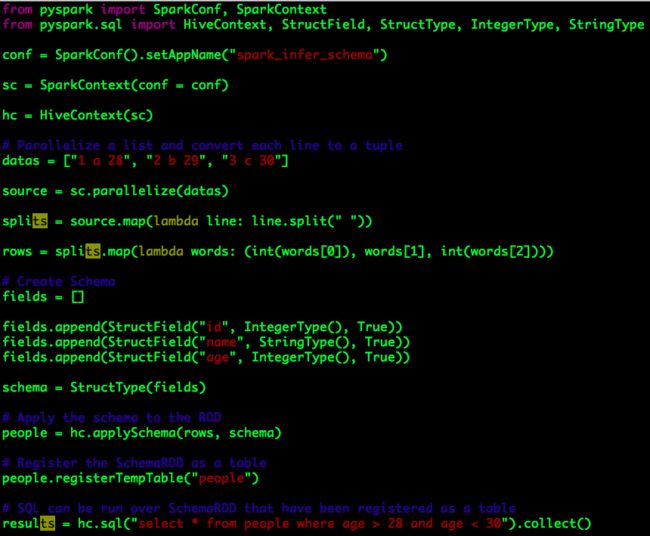

代码处理逻辑正好对应着上述三步,最终的输出结果:
其中需要注意id、age的数据类型被声明为IntegerType,因此数据源(字符串)中的数据需要做强制类型转换处理。
JSON Datasets
Spark能够自动推断出Json数据集的“数据模式”(Schema),并将它加载为一个SchemaRDD实例。这种“自动”的行为是通过下述两种方法实现的:
jsonFile:从一个文件目录中加载数据,这个目录中的文件的每一行均为一个JSON字符串(如果JSON字符串“跨行”,则可能导致解析错误);
jsonRDD:从一个已经存在的RDD中加载数据,这个RDD中的每一个元素均为一个JSON字符串;
代码示例

可以得出以下两点:
a. 如果数据输入是JSON字符串的文本文件,我们可以直接使用jsonFile构建Spark RDD,实际就是SchemaRDD;
b. 如果某个Spark RDD的数据类型是字符串,且字符串均是JSON格式的字符串形式,则可以使用jsonRDD将其转换为一个SchemaRDD。
Hive Tables
Hive Tables已经是“表”,因此我们无需创建或转换,直接使用SQL查询即可。
官方代码示例

Hive UDF(Register Function)
Spark SQL使用HiveContext时可以支持Hive UDF,这里的UFD包含Hive本身内建的UDF,也包括我们自己扩展的UDF(实测Spark-1.2.0-cdh5.3.2版本下无法正常使用自己扩展的UDF(Permanent Function),已通过扩展源码修复)。
这里重点介绍Spark SQL的Register Function,也就是说可以动态创建函数用于SQL查询,其实际作用类似于Hive UDF。
代码示例
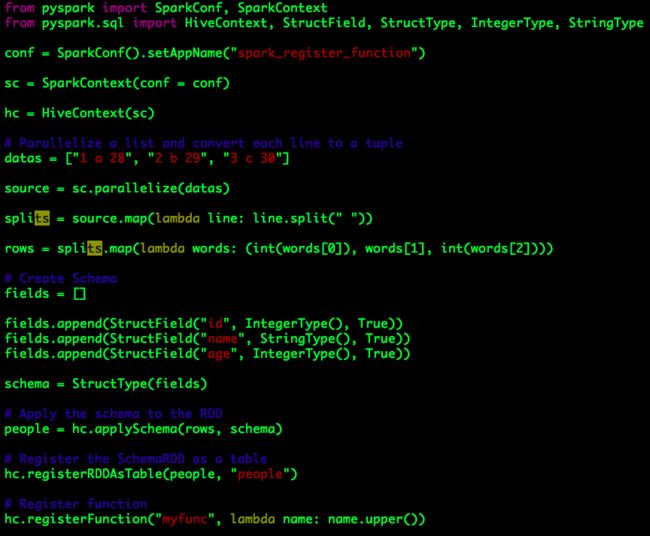

代码的处理逻辑与前大体类似,即首先通过编码创建SchemaRDD people,然后将其注册为一张表(注意这里使用了另一种方式:HiveContext registerRDDAsTable),最后执行查询语句并打印结果。
特别的是查询语句中使用到了一个名为“myfunc”的自定义SQL函数,而这个函数并不是预先存在的(如Hive UDF),它是在我们应用的运行期间被动态创建并注册的,注册过程使用到了HiveContext registerFunction。
对于Python而言,自定义函数的创建过程实际可分为两步:
(1)定义Python Function;
(2)将(1)中定义好的Python Function注册为SQL函数,注册时的命名可与Function的名称不同。
也可以使用Lambda表达式将定义Function与注册过程同时完成,如上述示例。
我们自定义的SQL函数可以与Hive UDF共同使用,如下示例:
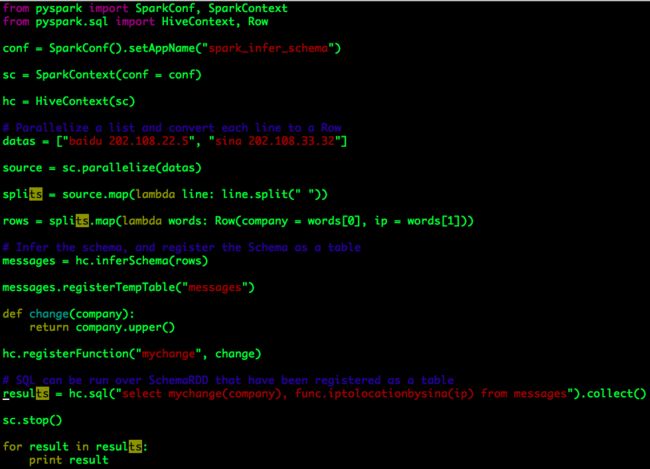
其中func.iptolocationbysina是Hive UDF(Permanent Function),mychange是自定义SQL函数。
从上面的两个示例可以看出,自定义SQL函数远比Hive UDF灵活。Hive UDF的创建过程比较复杂,需要使用Java语言完成编码并部署为jar,且在使用函数之前需要以temporaty function或permanent function的形式存在,每一次Hive UDF的更新都需要重新编码并更新jar;而自定义SQL函数是运行期间动态创建的,而使用Python编码时Function的创建及更新非常简便,推荐使用。
总结
Spark SQL为我们提供了强大的数据分析能力,主要体现在以下三个方面:
(1)Spark RDD可以通过反射推断Schema或编码指定Schema的方式转换为SchemaRDD,将SchemaRDD创建为“数据表”之后,允许我们以SQL语句的形式分析数据,节约大量编码工作量;
(2)Spark SQL允许我们在应用运行期间根据需求动态创建自定义SQL函数,扩充SQL的数据处理能力;
(3)SchemaRDD可以执行所有Spark RDD的操作,如果SQL无法表述我们的计算逻辑时,我们可以通过Spark RDD丰富的API完成。