scikit-learn学习 - 决策树
1.10. Decision Trees
决策树(Decision Trees ,DTs)是一种无监督的学习方法,用于分类和回归。它对数据中蕴含的决策规则建模,以预测目标变量的值。
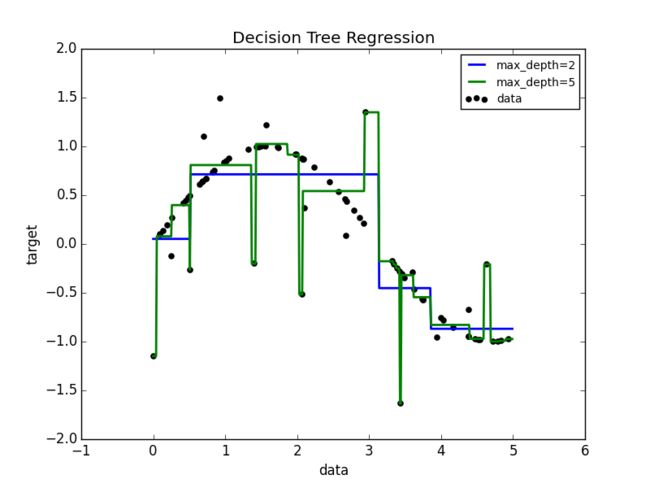
某些情况,例如下面的例子,决策树通过学习模拟一个包含一系列是否判断的正弦曲线。树越深,决策树的规则和拟合越复杂。
决策树的一些优点:
- 易于理解和解释。数可以可视化。
- 几乎不需要数据预处理。其他方法经常需要数据标准化,创建虚拟变量和删除缺失值。决策树还不支持缺失值。
- 使用树的花费(例如预测数据)是训练数据点(data points)数量的对数。
- 可以同时处理数值变量和分类变量。其他方法大都适用于分析一种变量的集合。
- 可以处理多值输出变量问题。
- 使用白盒模型。如果一个情况被观察到,使用逻辑判断容易表示这种规则。相反,如果是黑盒模型(例如人工神经网络),结果会非常难解释。
- 可以使用统计检验检验模型。这样做被认为是提高模型的可行度。
- 即使对真实模型来说,假设无效的情况下,也可以较好的适用。
决策树的一些缺点:
- 决策树学习可能创建一个过于复杂的树,并不能很好的预测数据。也就是过拟合。修剪机制(现在不支持),设置一个叶子节点需要的最小样本数量,或者数的最大深度,可以避免过拟合。
- 决策树可能是不稳定的,因为即使非常小的变异,可能会产生一颗完全不同的树。这个问题通过decision trees with an ensemble来缓解。
- 学习一颗最优的决策树是一个NP-完全问题under several aspects of optimality and even for simple concepts。因此,传统决策树算法基于启发式算法,例如贪婪算法,即每个节点创建最优决策。这些算法不能产生一个全家最优的决策树。对样本和特征随机抽样可以降低整体效果偏差。
- 概念难以学习,因为决策树没有很好的解释他们,例如,XOR, parity or multiplexer problems.
- 如果某些分类占优势,决策树将会创建一棵有偏差的树。因此,建议在训练之前,先抽样使样本均衡。
1.10.1. Classification
DecisionTreeClassifier 能够对数据进行多分类的类。
和其他分类器一样,DecisionTreeClassifier 有两个向量输入:X,稀疏或密集,大小为[n_sample,n_fearure],存放训练样本; Y,值为整型,大小为[n_sample],存放训练样本的分类标签:
>>> from sklearn import tree >>> X = [[0, 0], [1, 1]] >>> Y = [0, 1] >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, Y)
拟合后,模型可以用来预测分类:
>>> clf.predict([[2., 2.]])
array([1])
另外,每个分类的概率可以被预测,即某个叶子中,该分类样本的占比。
>>> clf.predict_proba([[2., 2.]])
array([[ 0., 1.]])
DecisionTreeClassifier 能同事应用于二分类(标签为[-1,1])和多分类(标签为[0,1,K-1])。
用数据集 lris ,可以构造下面的树:
>>> from sklearn.datasets import load_iris >>> from sklearn import tree >>> iris = load_iris() >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(iris.data, iris.target)
训练完成后,我们可以用 export_graphviz 将树导出为 Graphviz 格式。下面是导出 iris 数据集训练树的例子。
>>> from sklearn.externals.six import StringIO >>> with open("iris.dot", 'w') as f: ... f = tree.export_graphviz(clf, out_file=f)
然后用 Graphviz的 dot 工具创建PDF文件(或者其他支持的文件格式):dot -Tpdf iris.dot -o iris.pdf.
>>> import os >>> os.unlink('iris.dot')
或者,如果安装了pydot 模块,可以直接用Python创建PDF文件(或者其他支持文件):
>>> from sklearn.externals.six import StringIO >>> import pydot >>> dot_data = StringIO() >>> tree.export_graphviz(clf, out_file=dot_data) >>> graph = pydot.graph_from_dot_data(dot_data.getvalue()) >>> graph.write_pdf("iris.pdf")
export_graphviz 也支持很多美观选项,包括根据节点的分类(或者拟合的值)着色和根据需要描述变量和分类。 IPython notebooks can also render these plots inline using the Image() function:
>>> from IPython.display import Image >>> dot_data = StringIO() >>> tree.export_graphviz(clf, out_file=dot_data, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True) >>> graph = pydot.graph_from_dot_data(dot_data.getvalue()) >>> Image(graph.create_png())
拟合之后,模型可以用来样本分类:
>>> clf.predict(iris.data[:1, :])
array([0])
或者,每个分类的概率能被预测,即某个叶子中,该分类样本的占比。
>>> clf.predict_proba(iris.data[:1, :])
array([[ 1., 0., 0.]])
Examples:
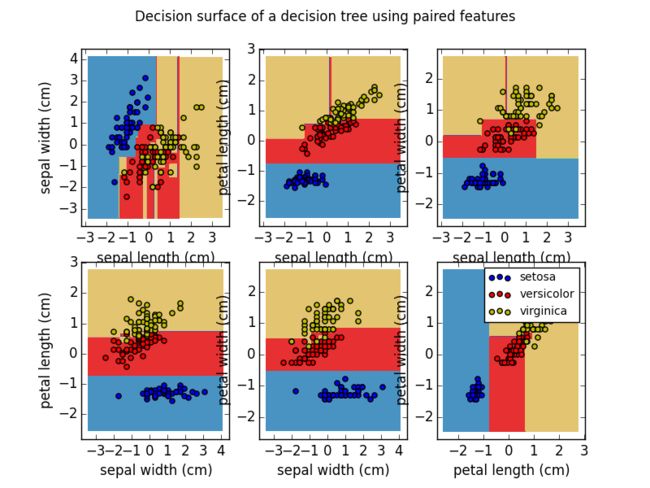
- Plot the decision surface of a decision tree on the iris dataset
1.10.2. Regression
决策树也可用来解决回归问题,使用 DecisionTreeRegressor 类。
和分类一样,拟合方法也需要两个向量参数,X 和 y,不同的是这里y是浮点型数据,而不是整型:
>>> from sklearn import tree >>> X = [[0, 0], [2, 2]] >>> y = [0.5, 2.5] >>> clf = tree.DecisionTreeRegressor() >>> clf = clf.fit(X, y) >>> clf.predict([[1, 1]]) array([ 0.5])
Examples:
- Decision Tree Regression
1.10.3. Multi-output problems
多输出问题是预测多个输出的监督学习过程,也就是说,y是大小为[n_sample, n_output]的二维向量。
当输出变量之间不相关是,一个非常简单的解决办法是
啊啊啊啊