Innodb 锁系列2 事务锁
上一篇介绍了Innodb的同步机制锁:Innodb锁系列1
这一篇介绍一下Innodb的事务锁,只所以称为事务锁,是因为Innodb为实现事务的ACID特性,而添加的表锁或者行级锁。
这一部分分两篇来介绍,先来介绍下事务锁相关的数据结构
事务锁数据结构
1. 锁模式
/* Basic lock modes */ enum lock_mode { LOCK_IS = 0, /* intention shared */ LOCK_IX, /* intention exclusive */ LOCK_S, /* shared */ LOCK_X, /* exclusive */ LOCK_AUTO_INC, /* locks the auto-inc counter of a table in an exclusive mode */ LOCK_NONE, /* this is used elsewhere to note consistent read */ LOCK_NUM = LOCK_NONE/* number of lock modes */ };
锁的模式包括两大类,共享锁(S)和互斥锁(X),s/x锁可以加在表上或者行记录上,
比如:
session1:alter table: table类型的X锁
session2:select * from table where id =1 for update: record类型的X锁
因为session1和session2互斥,为了实现在table表上阻塞,所以session2增加了表锁(IS),这样session2无法获取IS锁而阻塞。
LOCK_AUTO_INC:自增锁,为了保证在多行插入的时候,自增键值是连续的。
2. 表锁和记录锁数据结构
--表锁 struct lock_table_struct { dict_table_t* table; /*!< database table in dictionary cache */ UT_LIST_NODE_T(lock_t) locks; /*!< list of locks on the same table */ };
--行锁 struct lock_rec_struct { ulint space; /*!< space id */ ulint page_no; /*!< page number */ ulint n_bits; /*!< number of bits in the lock bitmap; NOTE: the lock bitmap is placed immediately after the lock struct */ };
--锁记录
struct lock_struct { trx_t* trx; /*!< transaction owning the lock */ UT_LIST_NODE_T(lock_t) trx_locks; /*!< list of the locks of the transaction */ ulint type_mode; /*!< lock type, mode, LOCK_GAP or LOCK_REC_NOT_GAP, LOCK_INSERT_INTENTION, wait flag, ORed */ hash_node_t hash; /*!< hash chain node for a record lock */ dict_index_t* index; /*!< index for a record lock */ union { lock_table_t tab_lock;/*!< table lock */ lock_rec_t rec_lock;/*!< record lock */ } un_member; /*!< lock details */ };
表锁:使用表的数据字典进行标示,并保持一个链表,记录table上的所有锁记录。
记录锁:记录锁使用space+page_no唯一进行标示一个page页,n_bits标示这个页的记录,1表示加锁。
锁记录:lock_t表示一个锁记录,事务锁永远都和trx关联,trx_locks表示这个事务的所有锁记录。
3. 全局结构
/** The lock system struct */ struct lock_sys_struct{ hash_table_t* rec_hash; /*!< hash table of the record locks */ ulint rec_num; }; /** The lock system */ extern lock_sys_t* lock_sys;
Innodb建立了一个全局的hash表,所有事务添加的锁,都记录在全局的事务表中,并使用record的space+page_no进行hash bucket的计算。入下图所示:
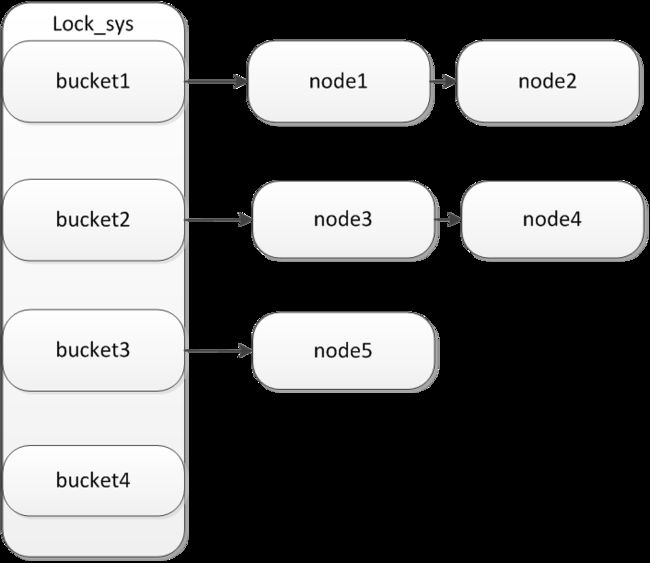
对于不同的space+page_no,通过hash key计算,映射到不同的bucket上,对于比如两条不同的update语句更新同一条记录的时候,不同的session,分别创建lock_t并加入到node1和node2中。这样就实现了所有的事务锁维护在hash+link的结构中。
不同的bucket互不影响,所有的wait,signal都通过相同的bucket下的链表来实现。
我们可以看一个函数就比较清楚了:
通过扫描hash结构+link结构来计算当前系统上有多少lock_t.
lock_get_n_rec_locks(void) { lock_t* lock; ulint n_locks = 0; ulint i; ut_ad(mutex_own(&kernel_mutex)); for (i = 0; i < hash_get_n_cells(lock_sys->rec_hash); i++) { lock = HASH_GET_FIRST(lock_sys->rec_hash, i); while (lock) { n_locks++; lock = HASH_GET_NEXT(hash, lock); } } return(n_locks); }
注:所有的lock_t统计信息,以及锁的相容性测试对象,wait和signal的操作,都是通过这个全局结构进行实现的。
4. 锁的gap模式
#define LOCK_ORDINARY 0
#define LOCK_GAP 512
#define LOCK_REC_NOT_GAP 1024
行级锁实现的gap模式:
1. record lock:记录锁,根据索引记录锁主单行记录
2. gap lock:gap锁,锁住一个记录的区间
3. next-gap lock:包含了记录锁和gap锁
锁的gap模式主要为了实现以下:
1. 丢失更新:对于多事务更新相同的记录,需要记录锁保证事务间的互斥,防止丢失更新。
2. 可重复读:在read repeatable的事务隔离级别下,需要锁住记录的gap,来保证可重复读。
5. 隐式锁和显式锁
对于cluster index的记录锁而言,如select * from table where id=1 for update而言,会显示的在id=1的聚簇索引上添加行级锁。
如果是update语句,除了在cluster_index上添加锁以为,还需要在二级索引上添加锁。
但cluster index添加的是显示的锁,而二级索引使用隐式锁。
隐式锁: 是一种延迟的加锁方式,毕竟加锁是有开销的,所以使用一种乐观的方式,因为主键索引记录上有trx_id,如果判断主键记录上的trx_id是活动的事务,那么才加显示的锁。
这样,最大化的减少记录加锁的机会。
下一篇介绍具体的加锁过程: