HBase 手动 flush 机制梳理
对应 HBase 版本0.94.1,对照了开源的版本和工作使用的某发行版
问题:在 HBase shell 里面输入 flush 'table_or_region_name'之后,发生了什么?具体的实现是怎么样的?对于现有的某个表,我如何在做操作之前估算 flush 执行的时间?
1. HBase shell 入口
HBase shell 使用 ruby 实现,在 putty 敲hbase shell,调用的是${HBASE_HOME}/bin/hbase这个 bash 脚本,根据shell这个参数,触发调用 ruby 代码,相关的部分如下:
if [ "$COMMAND" = "shell" ] ; then if [ "$JRUBY_HOME" != "" ] ; then CLASSPATH="$JRUBY_HOME/lib/jruby.jar:$CLASSPATH" HBASE_OPTS="$HBASE_OPTS -Djruby.home=$JRUBY_HOME -Djruby.lib=$JRUBY_HOME/lib" fi CLASS="org.jruby.Main -X+O ${JRUBY_OPTS} ${HBASE_HOME}/bin/hirb.rb"
在 hirb.rb 里面,引入相关的包(${HBASE_HOME}/lib/ruby目录下),然后启动一个运行的 CLI 环境。
进入正题了。
在 hbase shell 里面,所有执行的命令,都在${HBASE_HOME}/lib/ruby/shell/commands目录下,有对应的${COMMAND}.rb的对应文件。
找到 flush.rb,核心代码如下:
def command(table_or_region_name) format_simple_command do admin.flush(table_or_region_name) end end
这里调用了 admin.rb 这个文件里面的方法:
@admin = org.apache.hadoop.hbase.client.HBaseAdmin.new(configuration) def flush(table_or_region_name) @admin.flush(table_or_region_name) end
到这里,就找到了 Java 程序的入口,调用了 HBaseAdmin.flush(table_or_region_name)这个方法。
后续几部分的类图如下:
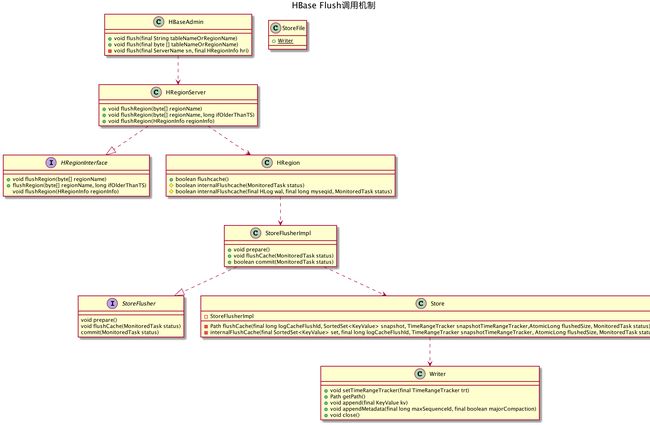
2. HBaseAdmin 包装
HBaseAdmin 类下面包含了三个 flush 方法:
public void flush(String tableNameOrRegionName) throws IOException, InterruptedException {} public void flush(byte[] tableNameOrRegionName) throws IOException, InterruptedException {} private void flush(ServerName sn, HRegionInfo hri) throws IOException {}
- 第一个,作为入口,将 String 参数转化为 byte[],交给第二个
- 第二个,主要的工作方法,按输入参数是 region 名、分区表、不分区表,分别进行处理
- 第三个,单独针对 region 进行 flush
第一个略过。
第二个,逻辑清晰:
- 如果是参数为 Region,就调用第三个 flush 处理
- 如果不是分区表,就获取该表包含的所有 Region,挨个调用第三个 flush 处理,
- 如果地分区表,处理方式与其他的不同,调用了一个分区表公共处理方法 execPartitionTableAction 订制实现了匿名类 PartitionTableActionCallableFactory,进行单独处理。
注意
- 对于没有预分区的表,简单地在一个 for 循环里面,串行处理
- 对于分区表,execPartitionTableAction中使用了并发数据结构 Future,对分区是并行处理
第三个,对每个 Region 进行 flush,实际上是第二个 flush 中所有 case 最终的归宿。
在第三个 flush 中,实现代码如下:
HRegionInterface rs = this.connection.getHRegionConnection(sn.getHostname(), sn.getPort()); rs.flushRegion(hri);
HRegionInterface 是一个抽象接口,flushRegion 是一个抽象方法。在0.94.1这个版本下,只有 HRegionServer 实现了 HRegionInterface 接口,所以要在 HRegionServer 里面找到具体的代码实现。
3. HRegionServer 包装
在 HRegionServer 类里面,包含了三个 flush 的实现:
public void flushRegion(byte[] regionName) throws IllegalArgumentException, IOException {} public void flushRegion(byte[] regionName, long ifOlderThanTS) throws IllegalArgumentException, IOException {} @QosPriority (priority=100) public void flushRegion(HRegionInfo regionInfo) throws NotServingRegionException, IOException {}
- 第一个,简单地传入 regionName,确定 Region 在线,然后调用
region.flushcache() - 第二个,传入 regionName 和 超时时间戳 ifOlderThanTS ,确定 Region 在线,且未超时的情况下,将数据 flush 出去
- 第三个,@QosPriority (priority=100)标记,使用了自定义声明,给该方法赋值 rpc 调用的优先级;方法体
checkOpen()检查 RegionServer 在线后,调用region.flushcache()
接下来,查看看下 HRegion 类下面flushcache()的实现。
4. HRegion 实现
flushcache只是个入口方法,会做一些 flush 之前的准备工作,包括:建立任务状态监控、判断 Coprocessor、处理未 WAL 的 put 、写加锁等。之后,调用内部方法internalFlushcache开始flush。
在 internalFlushcache 方法实现中,做了 MVCC 的一些工作,最终,调用了StoreFlusher的flushCache方法实现。
internalFlushcache 为了保证数据一致性做了很多的检查、校验、加锁,目前功力不够,先标记下,进入下一层。
看下 StoreFlusher 的实现。
5. StoreFlusher 实现
StoreFlusher 是个接口,在0.94.1这个版本里面,只有 Store.StoreFlusherImpl 一个实现类。
在 StoreFlusher 接口里面可以看到,flush 操作执行的过程中包含3个部分:
- prepare,这是个短操作,创建 snapshot,这个过程中会暂停写操作
- flushCache,flush 执行的过程中,是不会阻塞该 store 上的任何操作(读写)
- commit,将 flush 出的文件添加到 store 目录下,清除 memstore 快照,短操作,会足暂停 scan
6. StoreFlusherImpl 实现
StoreFlusherImpl 是 Store 类的内部私有类,前面提到的 StoreFlusher 的3个方法,由 StoreFlusherImpl实现后,prepare 是自己实现,flushCache和 commit 都是调用外部 Store类的方法来完成。
6.1 prepare
public void prepare() { memstore.snapshot(); this.snapshot = memstore.getSnapshot(); this.snapshotTimeRangeTracker = memstore.getSnapshotTimeRangeTracker(); }
调用了 MemStore 的方法,做快照。
6.2 flushCache
从 StoreFlusherImpl 调用 Store 类的flushCache方法,包装了internalFlushCache方法来实现。
逻辑比较清晰:
- 启动一个 StoreScanner,根据时间戳和ScanType 参数,找出需要被 Flush 的行
- 启动一个StoreFile Writer,把读出来的数据,写入到一个 StoreFile 中,并将该 StoreFile 的路径返回,供后续 commit 阶段使用
6.3 commit
StoreFlusherImpl 类的 commit 方法首先调用外部 Store类的commitFile方法,主要做的事情有两件:
- 将 flushCache 生成的 StoreFile 移动到 Store所在目录下
- 更新 Store 的相关统计参数
然后会调用外部 Store类的updateStorefiles更新 Store 类的 storefile,更新文件后,需要调用needsCompaction(),查看下是否因为本次 flush 执行造成的文件变化会触发 Compaction。如果触发 Compaction,会启动 Compaction 相关的一套机制继续执行,后续再单独介绍。
至此,手动 flush 操作背后的实现,初步梳理完毕。前面只是一个调用路径的梳理,后面继续丰富和补充。