Scala for the Impatient要点记录 - Part 2
Caution
在事实上解读Scala规范(Scala Language Reference 2.11.x)之前,这里不保证内容的正确性。
Content
- 11 操作符
- 12 高阶函数
- 13 集合
- 14 模式匹配和样例类
- 15 注解
- 16 XML处理
11 操作符
要点
- 标识符由字母、数字或运算符构成
- 一元和二元操作符其实是方法调用
- 操作符优先级取决于地一个字符,而结合性取决于最后一个字符
- apply和update方法在对expr(args)表达式求值时被调用
- 提取器从输入中提取元组或值的序列
11.1 标识符
变量、函数、类等的名称统称为标识符。
Scala中标识符除与Java一样使用Unicode字符外,还可以使用任意序列的操作符字符;
(1) 除字母、数字、下划线、括号()[]{}或分隔符.,;'`"之外的ASCII字符,即
! # % & * + - / : < = > ? @ \ ^ | ~(2) Unicode中的数学符号,或Unicode的Sm和So类别中的其他符号。
可以使用反引号(`),包含几乎任何字符序列:
val `val` = 1211.2 中置操作符
中置(infix)表达式: a 标识符 b
11.3 一元操作符
后置(postfix)表达式: a 标识符
+, -, ~, ~可以作为前置(prefix)操作符。
11.4 赋值操作符
赋值操作符的使用形式:a 操作符= b。
11.5 优先级
优先级由操作符的首字符确定(除赋值操作符外):
最高优先级:除以下字符外的操作符字符
* / %
+ -
:
< >
! =
&
^
|
非操作符
最低优先级:赋值操作符出现在同一行字符所产生的操作符优先级相同。
后置操作符的优先级低于中置操作符。
为怜悯那些不擅长使用圆括号的特殊嗜好者,尽量记这些糟糕的令人发指的规则。
11.6 结合性
在Scala中,所有操作符都是左结合的,除了:
以:结尾的操作符号;赋值操作符。
构造列表的::操作符是右结合的。右结合的二元操作符是其第二个参数的方法。
11.7 apply和update方法
Scala允许将f(arg1, arg2, ...)形式的函数调用语法扩展到应用于函数之外的值。
f不是函数或方法、且不在赋值语句的等号左侧时,等同于f.apply(arg1, arg2, ...);出现在赋值语句的等号左侧时(f(arg1, arg2, ...) = value),等同于f.update(arg1, arg2, ..., value)。
apply方法常被放在伴生对象中,用来构造对象而不是显式的使用new。
11.8 提取器
提取器是一个带有unapply方法的对象,可以将其视为伴生对象apply的反向操作:接受一个对象,从中提取值。
可以在变量定义或模式匹配使用提取器:
var Fraction(a, b) = Fraction(3, 4) * Fraction(2, 5)
case Fraction(a, b) => ...注意unapply方法返回的是一个Option:
object Fraction {
def apply(n : Int, d : Int) = new Fraction(n, d)
def unapply(input : Fraction) =
if (input.den == 0) None else Some((input.num, input.den))
}每一个样例类都自动获得apply和unapply方法。
11.9 带单个参数或无参数的提取器
在Scala中,没有只带一个元素的元组。如果unapply方法要提取单值,则应该返回一个目标类型的Option。
提取器可以只是测试其输入而不将其值提取出来,则unapply方法返回Boolean。
11.10 unapplySeq方法
object UnapplySeqs extends App {
val result = "AAA BBB CCC" match {
case SimpleName(first, last) => 1
case SimpleName(first, middle, last) => 2
case _ => 3
}
println(result)
val result2 = "AAA BBB CCC" match {
case Name(first, last) => 1
case Name(first, middle, last) => 2
case _ => 3
}
println(result2)
}
class Name(first : String, last : String) {
def this(input : String*) {
this(input(0), input(1))
}
}
object Name {
def apply(first : String, last : String) = new Name(first, last)
def apply(name : String*) = new Name(name(0), name(1))
// def unapply(input : String) = {
// val pos = input.indexOf(" ")
// if (pos == -1) None
// else Some((input.substring(0, pos), input.substring(pos + 1)))
// }
// FUCKING: it cannot play with `unapply`
def unapplySeq(input : String) : Option[Seq[String]] =
if (input.trim == "") None else Some(input.trim.split("\\s+"))
}
object SimpleName {
def unapplySeq(input : String) : Option[Seq[String]] =
if (input.trim == "") None else Some(input.trim.split("\\s+"))
}12 高阶函数
要点
- 在Scala中函数是头等公民,就和数字一样。
- 可以创建匿名函数,通常还会将它们传递给其他函数。
- 函数参数可以给出需要稍后执行的行为。
- 许多集合方法都可以接受函数参数,将函数应用到集合中的值。
- 有很多语法上的简写(语法糖)便于以简短且易读的方式表达函数参数。
- 可以创建操作代码块的函数,它们看上去就像是内建的控制语句。
12.1 作为值的函数
在Scala中,函数是头等公民,就跟数字一样。
可以在变量中存放函数:val fun = math.ceil _。_将ceil方法转换为函数,因在Scala中无法直接操作方法,而只能直接操作函数。
fun是一个包含函数的变量,可以以普通的函数调用语法调用:fun(4.0);也可以将fun作为参数传递给另一个函数:Array(1,2,3).map(fun)。
12.2 匿名函数
在Scala中不需要给每一个函数命名,例如:
(x: Double) => 3 * x可以将该函数存放到变量中:
val triple = (x: Double) => 3 * x可以直接将匿名函数直接作为参数传递:
Array(1,2,3).map((x: Double) => 3 * x)
// 一些语法糖
Array(1,2,3).map{ (x: Double) => 3 * x }
Array(1,2,3) map { (x: Double) => 3 * x }12.3 带函数参数的函数
定义接受另一个函数作为参数的函数(高阶函数):
def valueAtOneQuater(f: (Double) => Double) = f(0.25)作为函数参数的函数类型是(Double) => Double,valueAtOneQuater的类型是((Double) => Double) => Double。
高阶函数也可以产生另一个函数,即函数作为返回值:
def mulBy(factor: Double) = (x: Double) => factor * x它的类型是:(Double) => ((Double) => Double)。
12.4 参数(类型)推断
当将一个匿名函数作为参数传递给另一个函数或方法时,Scala会尽可能的做类型推断。
下面是一些语法糖:
valueAtOneQuater((x: Double) => 3 * x)
valueAtOneQuater((x) => 3 * x)
valueAtOneQuater(x => 3 * x) //匿名函数只有一个参数时
valueAtOneQuater(3 * _) //参数在 => 右边只出现一次一些简写的坑:
val fun = 3 * _ //无法做类型推断
val fun = 3 * (_: Double) //OK
val fun: (Double) => Double = 3 * _ // OK12.5 一些有用的高阶函数
map
将函数应用到某个集合的所有元素,并返回结果。
(1 to 9).map(0.1 * _)foreach
与map很像,但不返回结果,只是简单的将函数应用到每个元素上。
(1 to 9).map("*" * _).foreach(println _)filter
返回所有匹配条件的元素的集合。
(1 to 9).filter(_ % 2 == 0)reduceLeft
接受一个二元的函数,将该函数应用到序列中的所有元素,从左到右。
(1 to 9).reduceLeft(_ * _)
// (... ((1 * 2) * 3) * ... 9)sortWith
接受一个二元函数,做排序(不是原位排序)。
"Mary has a little lamb".split(" ").sortWith(_.length < _.length)12.6 闭包
在Scala中,可以在任何作用域内定义函数:包、类、函数或方法中。在函数体内,可以访问相应作用域内的任何变量,这样,函数可以在变量不在处于作用域内时被调用。
def mulBy(factor: Double) = (x: Double) => factor * x
val triple = mulBy(3)
val half = mulBy(0.5)每个返回的函数都有自己的factor设置。这样的函数称为闭包(closure)。闭包由代码和代码用到的任何非局部变量定义构成。
12.7 SAM转换
单抽象方法(single abstract method)、单方法接口,Java对函数式的尝试。
样板代码:
var counter = 0
val button = new JButton("Increment")
button.addActionListener(new ActionListener{
override def actionPerformed(event: ActionEvent){
counter += 1
}
})Scala的解决方案:
button.addActionListener((event: ActionEvent) => counter += 1)
implicit def makeAction(action: (ActionEvent) => Unit) =
new ActionListener{
override def actionPerformed(event: ActionEvent){
action(event)
}
}12.8 柯里化
柯里化(currying)是指将接受两个参数的函数转变为接受一个参数的函数的过程,新函数返回一个以原函数的第二个参数作为参数的函数,
//原函数
def mul(x: Int, y: Int) = x * y
// currying
def mulOneAtATime(x: Int) = (y: Int) => x * y
// call
mulOneAtATime(6)(7)
//语法糖
def mulOneAtATime(x: Int)(y: Int) = x * y12.9 控制抽象
换名调用表示法
在Scala中,可以将一系列语句包装成不带参数和返回值的函数。
def runInThread(block: () => Unit) {
new Thread{
override run() { block() }
}.start()
}
// call
runInThread { () => println(); Thread.sleep(1000); println() }使用换名调用表示法,在调用中移除() =>:
def runInThread(block: => Unit) {
new Thread{
override run() { block }
}.start()
}
// call
runInThread { println(); Thread.sleep(1000); println() }自定义控制抽象
模拟实现while:
def until(condition: => Boolean)(block: => Unit){
if(!condition) {
block
unitl(condition)(block)
}
}
// call
var x = 10
until (x == 0) { x -= 1; println(x) }12.10 return表达式
通常,Scala中函数的返回值就是函数体的值。但可以用return从一个匿名函数中返回值给包含这个匿名函数的带名函数。
def indexOf(str: String, ch: Char): Int = {
var i = 0
until (i == str.length) {
if(str(i) == ch) return i
i += 1
}
return -1
}匿名函数{ if(str(i) == ch) return i; i += 1 }中return语句执行时,包含它的带名函数indexOf终止,返回其值。
在带名函数中使用return的话,需要显式给出其返回类型。
13 集合
要点
- 所有集合都扩展子Iterable特质
- 集合有三大类:序列(Seq)、集(Set)和映射(Map)
- 对于几乎所有集合类,Scala都同时提供了可变和不可变的版本
- Scala列表(List)要么是空,要么有一头(head)一尾(tail),其中尾部本身又是一个列表
- 集(Set)是无先后次序的集合
- 用LinkedHashSet来保留插入顺序,或者用SortedSet来按顺序进行迭代
+将元素添加到无先后次序的集合中;+:和:+向前或向后追加到序列(Seq);++将两个集合串接到一起;-和--移除元素- Iterable和Seq特质有数十个用于常见操作的方法
- 映射(Map)、折叠(fold)和拉链(zip)操作,用来将函数或操作应用到集合中的元素。
13.1 主要的集合特质
Iterable是指那些能生成用来访问集合(collection)中所有元素的Iterator的集合。
遍历集合的基本方式:
val collection = ... // an Iterable collection
val iterator = collection.iterator
while(iterator.hasNext)
val element = iter.next()
// do something on element
Scala集合集成层次中重要的特质:

Seq是一个有先后次序的之的序列,例如数组或列表。IndexedSeq允许通过整型的下标快速的访问任意元素。
Set是一组没有先后次序的值。SortedSet中元素以某种排过序的顺序被访问。
Map是一组键值对偶。SortedMap按键的顺序访问其中的实体。
每个Scala集合特质或类都有一个带有apply方法的伴生对象,可以用来创建该集合的实例。这样的设计称为统一创建原则。
13.2 可变和不可变集合
Scala同时支持可变的和不可变的集合。
不可变的集合从不改变,可以安全的共享其引用,是线程安全的。不可变集合的基本用法是基于老的集合创建新的集合。
以Map为例,有scala.collection.mutable.Map和scala.collection.immutable.Map,它们共有的超类型是scala.collection.Map。
Scala优先采用不可变集合。scala.collection包中的伴生对象产出不可变的集合。总被引入的scala包和Predef对象里有指向不可变特质的类型别名 List、Set和Map。Predef.Map与scala.collection.mutable.Map相同。
13.3 序列
不可变序列:
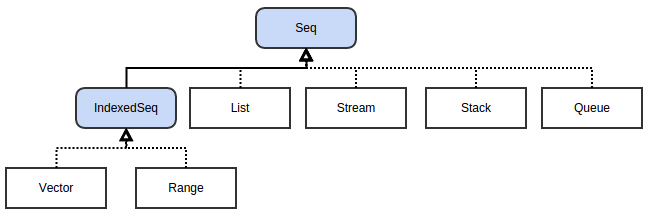
可变序列:

Vector是ArrayBuffer的不可变版本:一个带下标的序列,支持快速的随机访问。
Range表示一个整数序列,并不存储所有值,仅存储起始值、结束值和增量值。
13.4 列表
在Scala中,列表(List)要么是Nil(空表),要么是一个head元素加上一个tail,tail又是一个列表。
::操作符从给定的头和尾创建一个新的列表。该操作符是右结合的。
13.5 可变列表
CAUTION: 这些在Scala 2.11中均为deprecate。
可变的LinkedList和List相似,可以通过对起elem引用赋值来修改其头部、对next引用赋值来修改其尾部。
DoubleLinkedList比LinkedList多了一个prev引用。
想要将列表中的某个节点设置为最后一个节点时,应该将其next引用设置为LinkedList.empty,而不是Nill或null。
13.6 集
集(Set)是不重复元素的集合。默认情况下,集是以哈希集实现的。
链式哈希集(mutable.LinkedHashSet)可以记住元素被插入的顺序。
已排���集(immutable.SortedSet)支持按排序顺序访问元素。
位集(bit set)是集的一种实现,以字位序列的方式存放非负整数,Scala提供了BitSet。
集的一些常见操作:contains(元素包含判断)、subsetof(子集判断)、union(集并, 可写做|, ++)、intersec(集交, 可写做&)、diff(集差,可写做&~, --)。
13.7 用于添加或删除元素的操作符
请参考Scaladoc。
一般的,+用于将元素添加到无先后次序的集合,+:和:+将元素添加到有先后次序的集合的头部或尾部。
可变集合有+=操作符用于修改左侧的操作元。对于不可变集合,可以在var上使用+=或:+=操作符。
移除元素用-操作符,一次性添加多个元素使用++操作符。
13.8 常用方法
请参考Scaladoc。
13.9 将函数映射到集合
map方法可以将某个函数应用到集合中的每个元素并产生其结果的集合。
如果函数产出一个集合而不是单个值时,flatMap方法可以将所有值串接在一起。
collect方法用于偏函数(partial function),生成被定义的所有参数的函数值的集合。
foreach方法用于仅为应用函数的副作用而不关心函数值的场景。
13.10 化简、折叠和扫描
一些应用于集合中元素上的二元函数:reduce、fold和scan。
// 1 reduce
val list1 = List(1, 7, 2, 9).reduceLeft(_ - _)
println(list1)
val list2 = List(1, 7, 2, 9).reduceRight(_ - _)
println(list2)
// 2 fold
val list3 = List(1, 7, 2, 9).foldLeft(0)(_ - _)
println(list3)
// syntax sugar
println((0 /: List(1, 7, 2, 9))(_ - _))
val list4 = List(1, 7, 2, 9).foldRight(0)(_ - _)
println(list4)
// syntax sugar
println((List(1, 7, 2, 9) :\ 0)(_ - _))
// 3 scan
println((1 to 10).scanLeft(0)(_ + _))
println((1 to 10).scanRight(0)(_ + _))13.11 拉链操作
zip方法将两个集合组合成一个对偶的列表,可以很方便的在对偶上应用函数。
val prices = List(5.0, 20.0, 9.95)
val quantities = List(10, 2, 1)
val sum = ((quantities zip prices) map { pair => pair._1 * pair._2}).sum
println(sum)如果一个集合比另一个短,则结果中对偶的数量与较短的集合中元素数量相同。
zipAll方法可以指定较短列表的缺省值。zipWithIndex方法返回对偶的列表,其中对偶的第二个元素是每个元素的下标。
13.12 迭代器
可以使用iterator方法从集合获得一个迭代器。使用迭代器便利集合中元素的两个方法:
while(iterator.hasNext)
// do something on iterator.next
for(element <- iterator)
// do something on element这两个方法都会将迭代器移动到集合的末尾,在此之后迭代器就不能再被使用了。
Iterator类定义了一些与集合方法使用起来完全相同的方法,但注意这些方法会移动迭代器,可能会产生不能再次使用的副作用。
可以使用toArray、toIterable、toSeq、toSet或toMap等方法将迭代器相应的值拷贝到一个新的集合中。
13.13 流
对迭代器的next调用会带便迭代器的指向,流(stream)提供了一个不可变的替代品。流是一个尾部被懒计算的不可变列表。
def numsFrom(n: BigInt): Stream[BigInt] = n #:: numsFrom(n+1)#::操作符与列表的::操作符类似,但构建出来的是一个流。
流的方法是懒执行的。想一次性获得多个值,可以对流调用take后再调用force。
可以使用toStream从迭代器构造一个流。流可以缓存访问过的元素,从而允许重新访问这些元素。
13.14 懒视图
可以在集合上应用view方法,生成一个其方法总是被懒执行的集合。与流不同,该集合的第一个元素未被求值,同时不会缓存任何值。
与流一样,用force方法可以对懒视图强制求值。
懒集合对于处理需要以多种方式进行元素转换的大型集合很有益处,它避免了构建出大型中间集合的需要。
13.15 与Java集合的互操作
scala.collection.JavaConversions对象提供了用于在Scala和Java集合之间转换的一组方法。
可以从方法名称上猜测或查看Scaladoc。
这些转换生成的是包装器,可以使用目标接口访问原本的值。
13.16 线程安全的集合
Scala类库提供了一些特质,可以将这些特质混入集合中,让集合的操作变成同步的:SynchronizedBuffer、SynchronizedMap、SynchronizedPriorityQueue、SynchronizedQueue、SynchronizedSet、`SynchronizedStack。
val scores = new scala.collection.mutable.HashMap[String, Int] with scala.collection.mutable.SynchronizedMap[String, Int]注意这些特质实现均不可靠,已在Scala 2.11中deprecate。建议直接使用Java中的解决方案。
13.17 并行集合
对于一些自然可并行化的任务,对集合应用par方法生成当前集合的一个并行实现。该实现会尽可能的并行执行集合方法:
val list = List(1, 2, 3, 4, 5)
val newList = list.par.count { _ % 2 == 0 }
println(newList)
// parallel in for loop
// not in regular order
for(i <- (1 to 100).par) println(i)
val inSequenceSet = for(i <- (1 to 100).par) yield i + " "
println(inSequenceSet)par方法返回的并行集合的类型扩展自ParSeq、ParSet或ParMap特质的类型,所有这些特质都集成自ParIterable。这些并不是Iterable的子类型。
可以使用ser方法将并行集合转换为串行版本的集合。
14 模式匹配和样例类
要点
- match表示式是一个更好的switch,不会有意外掉入到下一个分支的问题。
- 如果没有模式能够匹配,会抛出MatchError。可以用case _模式来避免。
- 模式可以包含一个随意定义的条件,称为守卫。
- 可以对表达式的类型进行匹配;优先选择模式匹配而不是inInstanceOf/asInstanceOf。
- 可以匹配数组、元组和样例类的模式,然后将匹配到的不同部分绑定到变量。
- 在for表达式中,不能匹配的情况会被安静的跳过。
- 样例类是编译器会为之自动产生模式匹配所需要的方法的类。
- 样例类继承层次中的公共超类应该是sealed的。
- 用Option来存放对于可能存在也可能不存在的值,这比null更安全。
14.1 更好的switch
Scala中C风格的switch语句:
var sign = 0
val ch : Char = 'a'
ch match {
case '+' => sign = 1
case '-' => sign = -1
case _ => sign = 0
}与default等效的是case _模式。如果没有模式能够匹配,代码会抛出MatchError。
与switch语句不同,Scala模式匹配不会有'意外掉入到下一个分支的问题',即不需要在每个分支的末尾显式的使用break语句来退出switch。
match是表达式:
val sign2 = ch match {
case '+' => 1
case '-' => -1
case _ => 0
}可以在match表达式中使用任何类型。
14.2 守卫
在Scala中,可以给模式添加守卫:
var sign3 = 0
val ch2 = '3'
ch2 match {
case '+' => sign3 = 1
case '-' => sign3 = -1
case _ if Character.isDigit(ch2) => sign3 = Character.digit(ch2, 10)
case _ => sign3 = 0
}
println(sign3)守卫可以是任何Boolean条件。
模式总是从上向下进行匹配。
14.3 模式中的变量
如果case关键字后面跟有一个变量,则匹配的表达式会被赋值给该变量。
val str = "123abcd"
val sign4 = str(2) match {
case '+' => 1
case '-' => -1
case ch if Character.isDigit(ch) => Character.digit(ch, 10)
}14.4 类型模式
可以对表达式的类型进行匹配。当匹配类型时,必须给出一个变量名,否则会将对象本身来进行匹配。
// val obj : Any = Array(1, 2, 3)
val obj : Any = Map[String, String]("hello" -> "world")
val result = obj match {
case x : Int => x
case s : String => Integer.parseInt(s)
case _ : BigInt => Int.MaxValue
case m : Map[_, _] => 9999
case _ => 0
}14.5 匹配数组、列表和元组
// 1 array: Array
val array = Array(0, 1, 2, 3)
val arrayResult = array match {
case Array(0) => "0"
case Array(x, y) => x + " " + y
case Array(0, _*) => "0 ..."
case _ => "something else"
}
println(arrayResult)
// 2 list: List or `::`
val list = List(1, 2, 3)
val listResult = list match {
case 0 :: Nil => "0"
case x :: y :: Nil => x + " " + y
case 0 :: tail => "0 ..."
case _ => "something else"
}
println(listResult)
// 3 pair
val pair = (0, 2)
val pairResult = pair match {
case (0, _) => "0 ..."
case (y, 0) => y + " 0"
case _ => "neither is 0"
}
println(pairResult)这样的操作称为析构。
14.6 提取器
析构功能背后的机制是提取器:带有从对象中提取值的unapply或unapplySeq方法的对象。
Array伴生对象就是一个提取器,定义了一个unapplySeq方法,该方法以被执行匹配动作的表达式作为参数,而不是模式中像是参数的表达式。
如果正则表达式有分组,可以用提取器来匹配每个分组。这时,提取器不是一个伴生对象,而是一个正则表达式对象。
// case 1: array
val array = Array(0, 1, 2, 3)
val arrayResult = array match {
case Array(0) => "0"
case Array(x, y) => x + " " + y
case Array(0, _*) => "0 ..."
case _ => "something else"
}
println(arrayResult)
// case 2: regular expression
val pattern = "([0-9]+) ([a-z]+)".r
"99 bottles" match {
case pattern(num, item) => println("num=" + num + ", item=" + item)
case _ => // do nothing
}14.7 变量声明中的模式
可以在变量声明中使用模式:
val (x, y) = (1, 2)同样的语法也可以用于任何带有变量的模式:
val Array(first, second, _*) = Array(1, 2, 3)14.8 for表达式中的模式
可以在for推导式中使用带变量的模式。在for推导中,失败的匹配将安静的被忽略。也可以在for推导式中使用守卫。
import scala.collection.JavaConversions.propertiesAsScalaMap
for ((key, value) <- System.getProperties) {
println("key=" + key + ", value=" + value)
}
println("---")
// pass un-matched patterns quietly
for ((key, "") <- System.getProperties) {
println("key=" + key)
}
println("---")
// use guards
for ((key, value) <- System.getProperties if value == "") {
println("key=" + key + ", value=" + value)
}14.9 样例类
样例类是一种特殊的类,经过优化以被用于模式匹配。
也可以有针对单例的样例对象。样例类的实例使用(),样例对象不使用。
在声明样例类时,会自动发生:
(1) 构造器中的每个参数都成为val,除非显式的声明为var;
(2) 在伴生对象中提供apply方法;
(3) 提供unapply方法让模式匹配可以工作;
(4) 生成toString、equals、hashCode和copy方法,除非显式的给出这些方法的定义。
除这些自动发生的事情外,样例类与其他类完全一样。
// val amount : Amount = Dollar(123.456)
//val amount : Amount = Currency(123.456, "USD")
val amount : Amount = NothingAmount
val matchResult = amount match {
case Dollar(v) => "$" + v
case Currency(_, u) => "Oh yes, I got " + u
case NothingAmount => "nothing"
}
abstract class Amount
// case classes
case class Dollar(value : Double) extends Amount
case class Currency(value : Double, unit : String) extends Amount
// case objects
case object NothingAmount extends Amount14.10 copy方法和带名参数
样例类的copy方法创建一个与现有值相同的新对象。
可以在copy中用带名参数修改某些属性。
val amount = Currency(9.95, "USD")
val amount2 = amount.copy()
println(amount == amount2) // true
println(amount.equals(amount2)) //true
println(amount.eq(amount2)) //false
// change some properties when copy
val amount3 = amount.copy(value = 10)
println(amount3)
val amount4 = amount.copy(unit = "EUR")
println(amount4)
val amount5 = amount.copy(value = 10, unit = "EUR")
println(amount5)14.11 case语句中的中置表示法
如果unapply方法产生一个对偶,则可以在case语句中使用中置表示法:
amount match {case a Currency u => ...}
//等价于
case Currency(a, u)这个特性的本意是要匹配序列。如List对象要么是Nil,要么是样例类:::
case class ::[E] (head: E, tail: List[E]) extends List[E]
list match { case h :: t => ... }
// 等价于
case ::(h, t) // 会调用::.unapply(list)14.12 匹配嵌套结构
样例类可以用于匹配嵌套结构。可以用@表示法将嵌套的值绑定到变量。
abstract class Item
case class Article(description : String, price : Double) extends Item
// `Item*`
case class Bundle(description : String, discount : Double, items : Item*) extends Item
// construct nested object
val bundle = Bundle("Father's day special", 20.0,
Article("Scala", 39.95),
Bundle("Anchor Distillery Sampler", 10.0,
Article("Old", 79.95),
Article("New", 89.95)
))
bundle match {
// 1 match nested value
// case Bundle(_, _, Article(desc, _), _*) => println(desc)
// 2 @
case Bundle(_, _, article@Article(_, _), rest@_*) => println(article); println(rest)
}
def price(item : Item) : Double = item match {
case Article(_, price) => price
case Bundle(_, discount, items@_*) => items.map { price _ }.sum - discount
}
println(price(bundle))14.13 样例类是邪恶的吗
样例类适用于那种标记不会改变的结构,例如List;或者作为值类。
对于扩展其他样例类的样例类,toString、equals、hashCode、copy方法不会被自动生成,同时得到编译器警告(2.9中特性???)。
14.14 密封类
用样例类做模式匹配时,可能想让编译器帮助确保已经列出了所有可能选择,可以使用密封类。
密封类的所有子类必须在与该密封类相同的文件中定义。
// sealed case class
sealed abstract class Amount
// case classes
case class Dollar(value : Double) extends Amount
case class Currency(value : Double, unit : String) extends Amount
val amount : Amount = Dollar(9.95)
// warning: match may not be exhaustive. It would fail on the following input: Currency(_, _)
amount match {
case Dollar(v) => println(v)
}14.15 模拟枚举
sealed abstract class TrafficLightColor
case object Red extends TrafficLightColor
case object Yellow extends TrafficLightColor
case object Green extends TrafficLightColor
val color : TrafficLightColor = Red
color match {
case Red => println("stop")
case Yellow => println("hurry up")
case Green => println("go")
}14.16 Option类型
Option类型用样例类来表示可能存在、也可能不存在的值。样例子类Some包装了某个值,如Some("Alice");样例对象None表示没有值。
Option支持泛型。
Map类的get方法返回一个Option。
也可以将Option视为一个要么是空、要么带有单个元素的集合,并使用map、foreach、filter等方法。
14.17 偏函数
被包在花括号内的一组case语句是一个偏函数:一个不是对所有输入值均有定义的函数,是PartialFunction[A, B]类的一个实例,其中A是参数类型,B是返回类型。
PartialFunction[A, B]类有两个方法:apply从匹配到的模式计算函数值;isDefinedAt在输入至少匹配一个模式时返回true。
偏函数表达式必须位于编译器可以推断出返回类型的上下文中。
val func : PartialFunction[Char, Int] = {
case '+' =>
println(1); 1
case '-' =>
println(-1); -1
}
func('-') // call func.apply('-')
println(func.isDefinedAt('0')) // false
try {
func(0)
} catch {
case t : MatchError => println("match error")
}15 注解
要点
- 你可以为类、方法、字段、局部变量、参数、表达式、类型参数以及各种类型定义添加注解。
- 对于表达式和类型,注解跟在被注解的条目之后。
- 注解的形式有@Annotation、@Annotation(value)或@Annotation(name1=value1, ...)。
- @volatile、@transient、@strictfp和@native分别生成等效的Java修饰符。
- 用@throw来生成与Java兼容的throws规格说明。
- @tailrec注解让你校验某个递归函数使用了尾递归优化。
- assert函数利用了@elidable注解。可以选择从Scala程序中移除所有断言。
- 用@deprecated注解来标记已过时的特性。
15.1 什么是注解
注解是插入到代码中以便有工具可以对他们进行处理的标签。
可以对Scala类使用Java注解。也可以使用Scala注解,这些注解是Scala特有的。
在Scala中注解可以影响编译过程,例如@BeanProperty注解将触发getter/setter方法的生成。
15.2 什么可以被注解
@Entity class Credentials // 类
@Test def testSomeFeature(){} // 方法
@BeanProperty var username = _ //字段
def doSomething(@NotNull message: String){} // 参数
@BeanProperty @Id var username = _ // 同时添加多个参数
// 主构造器
class Credentials @Inject() (var username: String, var password: String)
// 表达式
(aMap.get(key) : @unchecked) match {...}
// 类型参数
class MyContainer[@specialized T]
// 类型
String @cps[Unit] // @cps带一个类型参数15.3 注解参数
Java注解可以有带名参数,大多数注解参数都有默认值。
Java注解的参数类型只能是:数值型的字面量、字符串、Java枚举、其他注解或前面类型的数组(但不能是数组的数组)。
Scala注解的参数可以是任何类型。
15.4 注解实现
注解必须扩展Annotation特质。
注解类可以选择扩展StaticAnnotation或ClassfileAnnotation。StaticAnnotation在编译单元中可见,而ClassfileAnnotation的意图是在类文件中生成Java注解元数据。
没有定义Scala注解的示例,直接自定义Java注解使用算了。
15.5 针对Java特性的注解
Scala类库提供了一组与Java互操作的注解。
object AnnotationForJava extends App {
@volatile var done = false
import scala.collection.mutable.HashMap
@transient var store = new HashMap[String, String]
// NOT WORKING
//@strictfp def calculate(x : Double) = x * 2
@native def win32SomeRubbish() : Array[String]
}
// NOT WORKING
//@cloneable class Employee
@remote class Employee
@SerialVersionUID(1L)
class Person extends Serializable {
@BeanProperty var name : String = _
}
class Book {
// for java checked exception
@throws(classOf[IOException]) def read(filename : String) {}
// to generate java `void process(String ... args)`
@varargs def process(args : String*) {}
}15.6 用于优化的注解
// 1 tail recursion
//@tailrec // WRONG ANNOTATION in compilation
def sum1(xs : Seq[Int]) : BigInt =
if (xs.isEmpty) 0 else xs.head + sum1(xs.tail)
// will use tail recursion optimalize
@tailrec
def sum2(xs : Seq[Int], partSum : BigInt) : BigInt =
if (xs.isEmpty) partSum else sum2(xs.tail, xs.head + partSum)
// 2 switch table: NOT WORKING
// val n = 10
// (n : @switch) match {
// case 0 => "ZERO"
// case 1 => "ONE"
// case _ => "?"
// }
// 3 elidable
@elidable(500) def dump(props : Map[String, String]) {}
@elidable(elidable.FINE) def dump2(props : Map[String, String]) {}
// 4 assert
def MakeMap(keys : Seq[String], values : Seq[String]) = {
assert(keys.length == values.length, "length does not match")
}
// 5 specialized
def allDifferent[T](x : T, y : T, z : T) = x != y && y != z && z != x
def allDifferent2[@specialized(Unit, Boolean, Byte, Short, Char, Int, Long, Float, Double) T](x : T, y : T, z : T) = x != y && y != z && z != x15.7 用于错误和警告的注解
@deprecated(message = "Use factorial(n: BigInt) instead")
def factorial(n : Int) : Int =
if (n == 0 || n == 1) 1 else n * factorial(n - 1)
// symbol: start with `'`
def draw(@deprecatedName('sz) size : Int, style : Int = 0) {}@implicitNotFound注解用于在某个隐式参数不存在的时候生成有意义的错误提示。
@unchecked注解用于在匹配不完整时取消警告信息。
@uncheckedVariance注解用于取消与型变相关的错误提示。
16 XML处理
要点
- XML字面量
<list>this</like>的类型为NodeSeq。 - 可以在XML字面量中内嵌Scala代码。
- Node的
child属性产出后代节点。 - Node的
attributes属性产出包含节点属性的MetaData对象。 \和\\操作符执行类XPath匹配。- 可以在case语句中使用XML字面量匹配节点模式。
- 使用带有
RewriteRule示例的RuleTransformer来变换某个节点的后代。 - XML对象使用Java的XML相关方法实现XML文件的加载和保存。
ConstructingParser是另一个可以使用的解析器,会保留注释和CDATA节点。
16.1 XML字面量
将$SCALA_HOME/scala-xml_2.11-1.0.4.jar加入classpath。
Scala对XML有内建的支持。可以定义XML字面量:
import scala.xml.Elem
val doc : Elem = <html><head><title>Hello</title></head><body>there</body></html>XML字面量也可以是一系列节点:
import scala.xml.NodeSeq
val items : NodeSeq = <li>Fred</li><li>Tom</li>16.2 XML节点
XML节点类型:

Node是所有XML节点类型的祖先,两个最重要的子类:Text、Elem。
Elem类描述的是XML元素,其label属性产出标签名称,child属性产生后代的序列。
val elem = <a href="http://scala-lang.org">The <em>Scala</em> language</a>
// 1 element
println(elem.label) //a
println(elem.child) //ArrayBuffer(The , <em>Scala</em>, language)节点序列的类型是NodeSeq,它是Seq[Node]的子类型,加入了对类XPath操作的支持。遍历NodeSeq:
for (node <- elem.child)
println(node)以编程的方式创建节点序列时,使用NodeBuffer,它是ArrayBuffer[Node]的子类。NodeBuffer是一个Seq[Node],可以被隐式的转换为NodeSeq;一旦完成转换,不应该再修改NodeBuffer,因为NodeSeq应该是不变的。
import scala.xml.NodeBuffer
import scala.xml.NodeSeq
val items = new NodeBuffer
items += <li>Fred</li>
items += <li>Tom</li>
val nodes : NodeSeq = items16.3 元素属性
要处理XML元素的属性键和值,使用attributes,该方法产出一个MetaData对象。可以使用()访问指定键的值:
val elem = <a href="http://scala-lang.org">The Scala language</a>
import scala.xml.MetaData
println(elem.attributes: MetaData)
import scala.xml.NodeSeq
val url : NodeSeq = elem.attributes("href")
println(url)
println(elem.attributes("href").text)
import scala.xml.Text
println(elem.attributes.get("href2").getOrElse(Text("NONE")))遍历所有属性:
// traversal all attributes
for (attribute <- elem.attributes)
println(attribute.key + "=" + attribute.value.text)
// or as a map
println(elem.attributes.asAttrMap)16.4 内嵌表达式
可以在XML字面量中包含Scala代码块,动态的计算出元素内容。
如果代码块产出的是一个节点序列,序列中的节点会被直接添加到XML中;所有其他值都会被放到一个Atom[T]中,这样你可以在XML树中存放任何值。
// 1 string literal
val items = Array("Alice", "Bob")
val xml = <ul><li>{ items(0) }</li><li>{ items(1) }</li></ul>
println(xml)
// 2 node sequence
import scala.xml.NodeSeq
val items2 : NodeSeq = <li>Fred</li><li>Tom</li>
val xml2 = <ul>{ items2 }</ul>
println(xml2)在内嵌的Scala代码中还可以继续包含XML字面量。
// 3 nested XML literal in expression
val xml3 = <ul>{ for (item <- items) yield <li>{ item }</li> }</ul>
println(xml3)
// headache???
val xml4 = <ul>{ for (item <- items) yield <li>{ item toUpperCase }</li> }</ul>
println(xml4)要想在XML字面量中包含花括号,连续写两个即可。
16.5 在属性中使用表达式
可以用Scala表达式来计算属性值。被引用的字符串当中的花括号不会被解析和求值。
内嵌的代码块也可以产出一个节点序列。
如果内嵌代码块返回null或None,该属性不会被设置。
def filename = "hello.html"
def makeURL(filename : String) = "http://www.spike.com/" + filename.toUpperCase()
val xml = <img src={ makeURL(filename) }/>
println(xml)
import scala.xml.Atom
val xml2 = <a id={ new Atom(1) }/>
println(xml2)
val description = "TODO"
val xml3 = <img alt={ if (description == "TODO") null else description }/>
println(xml3)
import scala.xml.Text
val xml4 = <img alt={ if (description == "TODO") None else Some(Text(description)) }/>
println(xml4)16.6 特殊节点类型
可以在XML字面量中使用CDATA标记。如果要在输出中带有CDATA,可以包含一个PCData节点。
可以在Unparsed节点中包含任意文本,这些文本会被原样保留。
可以将一个节点序列归组到单个组节点。遍历组节点时,他们会被自动解开。
// 1 CDATA
val js1 = <script><![CDATA[if (temp < 0) alert("Code!")]]></script>
// <script>if (temp < 0) alert("Code!")</script>
println(js1)
import scala.xml.PCData
val code = """if (temp < 0) alert("Code!")"""
val js2 = <script>{ PCData(code) }</script>
// <script><![CDATA[if (temp < 0) alert("Code!")]]></script>
println(js2)
// 2 unparsed
val n1 = <xml:unparsed><&></xml:unparsed>
println(n1)
import scala.xml.Unparsed
val n2 = Unparsed("<&>")
println(n2)
// 3 group
val g1 = <xml:group><li>item 1</li><li>item 2</li></xml:group>
println(g1)
import scala.xml.Group
val g2 = Group(Seq(<li>item 1</li>, <li>item 2</li>))
println(g2)
println()
val items = <li>item 1</li><li>item 2</li>
import scala.xml.NodeSeq
val res1 : NodeSeq = for (n <- <xml:group>{ items }</xml:group>) yield n
val res2 : NodeSeq = for (n <- <ol>{ items }</ol>) yield n
println(res1)
println(res1.length)
println(res2)
println(res2.length)16.7 类XPath表达式
NodeSeq类提供了类似XPath中/和//操作符的方法,在Scala中用\和\\操作符。
\操作符定位某个及诶但或节点序列的直接后代。
通配符_可以匹配任意元素。\\操作符可以定位任意深度的后代。
以@开头的字符串可以定位属性,并没有用于属性的通配符。
\和\\的结果是一个节点序列,如果对\和\\调用text方法,所有结果序列中的文本会被串接在一起。
val list = <dl><dt>Java</dt><dd>Gosling</dd><dt>Scala</dt><dd>Odersky</dd></dl>
val language = list \ "dt"
println(language) //<dt>Java</dt><dt>Scala</dt>
val meta1 = <meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"/>
val link = <link href="/images/branding/product/ico/googleg_lodp.ico" rel="shortcut icon"/>
val meta2 = <meta content="origin" id="mref" name="referrer"/>
val title = <title>Google</title>
val head = <head>{ meta1 }{ link }{ meta2 }{ title }</head>
val divs = <div class="jfk-bubble-arrowimplbefore"></div><div class="jfk-bubble-arrowimplafter"></div>
val div = <div class="jfk-bubble-arrow-id jfk-bubble-arrow">{ divs }</div>
val body = <body>{ div }</body>
val html = <html itemscope="" itemtype="http://schema.org/WebPage" lang="zh-CN">{ head }{ body }</html>
println(html)
println(html \ "body" \ "_" \ "div")
println(html \\ "div")
println(html \\ "@lang")
println(html \\ "@class")
println()
for (htmlClass <- html \\ "@class")
println(htmlClass)
println((<img src="aa.jpg"/><img src="bb.png"/> \\ "@src").text)16.8 模式匹配
可以在模式匹配表达式中使用XML字面量。
在XML模式中,花括号表示代码模式而不是可以被求值的代码。
除了用通配符,可以使用变量名,成功匹配的内容会绑定到该变量上。
在case语句中,只能使用一个节点;XML模式不能有属性,要匹配属性得用守卫。
// 1 no child
val node = <img src="a.jpg"/>
node match {
case <img/> => println("a image node")
case _ => println("unknown node")
}
// 2 with child
val node2 = <li>Scala Impatient Tutorial</li>
node2 match {
//case <li>{ _ }</li> => println("one child")
case <li>{ child }</li> => println(child)
case _ => println("unknown")
}
// 3 multiple children
val node3 = <li>Scala <em>Impatient</em> Tutorial</li>
node3 match {
//case <li>{ _* }</li> => println("multiple children")
case <li>{ children@_* }</li> => println(children)
case _ => println("unknown")
}
// 4 match attribute of node
val node4 = <img alt="TODO"/>
node4 match {
case n@ <img/> if (n.attributes("alt").text == "TODO") => println(n)
case _ => println("not found")
}16.9 修改元素和属性
在Scala中,XML节点和节点序列是不可变的,想编辑一个节点必须创建一个拷贝。
要拷贝Elem节点,使用其copy方法,它有带名参数:prefix, label, attributes, scope, minimizeEmpty, child,任何未指定的参数会从原来的元素中直接拷贝过来。
要修改或添加一个属性,可以使用%操作符。
val list = <ul><li>Alice</li><li>Bob</li></ul>
// prefix, label, attributes, scope, minimizeEmpty, child
// 1 label
val list2 = list.copy(label = "ol")
println(list2)
// 2 child
val list3 = list.copy(child = list.child ++ <li>Cartman</li>)
println(list3)
// 3 add attribute
import scala.xml.Attribute
val image = <img src="a.jpg"/>
val image2 = image % Attribute(null, "alt", "image alt info", xml.Null)
println(image2)
// 4 multiple attributes
val image3 = image % Attribute(null, "alt", "image alt info", // add alt
Attribute(null, "src", "b.jpg", xml.Null)) // modify src
println(image3)16.10 XML变换
XML类库提供了一个RuleTransformer类,可以将一个或多个RewriteRule实例应用到某个节点及其后代。
可以在RuleTransformer的构造器中给出多条规则。
import scala.xml.transform.RewriteRule
val rule1 = new RewriteRule {
import scala.xml.Node
import scala.xml.Elem
override def transform(n : Node) = n match {
case e@ <ul>{ _* }</ul> => e.asInstanceOf[Elem].copy(label = "ol")
case _ => n
}
}
val rule2 = new RewriteRule {
import scala.xml.Node
import scala.xml.Elem
import scala.xml.Attribute
import scala.xml.Null
override def transform(n : Node) = n match {
case e@ <ol>{ _* }</ol> => e.asInstanceOf[Elem] % Attribute(null, "class", "myul", Null)
case _ => n
}
}
val xml = <ul><li>Alice</li><li>Bob</li></ul>
import scala.xml.transform.RuleTransformer
val xmlTransformed = new RuleTransformer(rule1).transform(xml)
println(xmlTransformed)
// rule application order: rule1 -> rule2
val xmlTransformed2 = new RuleTransformer(rule1, rule2).transform(xml)
println(xmlTransformed2)16.11 加载和保存
要从文件中加载XML文档,可以使用XML对象的loadFile方法。文档是使用Java类库中的SAX解析器加载的。
Scala还提供了另一解析器,可以保留注解、CDATA节点和空白:ConstructingParser。
要保存XML到文件中,可以用save方法,也可以保存到java.io.Writer中。
val filepath = "/home/zhoujiagen/local_git_repository/scala/scala/src/com/spike/scala/impatient/xml/myfile.xml"
// 1 load xml
import scala.xml.XML
val root = XML.loadFile(filepath)
// println(root)
import java.io.FileInputStream
val root2 = XML.load(new FileInputStream(filepath))
// println(root2)
import java.io.InputStreamReader
val root3 = XML.load(new InputStreamReader(new FileInputStream(filepath), "UTF-8"))
// println(root3)
import java.net.URL
val root4 = XML.load(new URL("http://files.cnblogs.com/files/zhoujiagen/FOAF0.99.rdf.xml"))
//println(root4)
// 2 ConstructingParser
import scala.xml.parsing.ConstructingParser
import java.io.File
val parser = ConstructingParser.fromFile(new File(filepath), preserveWS = true)
val doc = parser.document
val docRoot = doc.docElem
println(docRoot)
// 3 save xml
val filepath2 = "/home/zhoujiagen/local_git_repository/scala/scala/src/com/spike/scala/impatient/xml/myfile2.xml"
XML.save(filename = filepath2, //
node = docRoot, //
enc = "UTF-8", //
xmlDecl = true
)16.12 命名空间
在Scala中,每个XML元素都有一个scope属性,其类型为NamespaceBinding,该类的uri熟悉将输出命名空间的URI。
每个Elem对象都有prefix和scope值,使用scope.uri找出元素的命名空间。
以编程的方式生成MXL元素时,需要手工设置prefix和scope。
import scala.xml.NamespaceBinding
import scala.xml.TopScope
import scala.xml.Attribute
import scala.xml.Null
import scala.xml.Elem
val scope = new NamespaceBinding("svg", "http://www.w3.org/2000/svg", TopScope)
val attrs = Attribute(null, "width", "100", Attribute(null, "height", "100", xml.Null))
// <body><svg:svg width="100" height="100" xmlns:svg="http://www.w3.org/2000/svg"/></body>
val elem = Elem(null, "body", xml.Null, TopScope, Elem("svg", "svg", attrs, scope))