性能之巅:Linux网络性能分析工具
编者按:InfoQ开设新栏目“品味书香”,精选技术书籍的精彩章节,以及分享看完书留下的思考和收获,欢迎大家关注。本文节选自格雷格著《性能之巅:洞悉系统、企业与云计算》中第10.6节,介绍了其中Linux部分网络性能分析工具的使用方法。
本文介绍基于Linux操作系统的网络性能分析工具。它们的使用策略参见前面的部分。
本节介绍的工具列于下表中。
| Linux |
Solaris |
描述 |
| netstat |
netstat |
多种网络栈和接口统计信息 |
| sar |
- |
统计信息历史 |
| ifconfig |
ifconfig |
接口配置 |
| ip |
dladm |
网络接口统计信息 |
| nicstat |
nicstat |
网络接口吞吐量和使用率 |
| ping |
ping |
测试网络连通性 |
| traceroute |
traceroute |
测试网络路由 |
| pathchar |
pathchar |
确定网络路径特征 |
| tcpdump |
snoop/tcpdump |
网络数据包嗅探器 |
| Wireshark |
Wireshark |
图形化网络数据包检查器 |
| DTrace, perf |
DTrace |
TCP/IP栈跟踪:连接、数据包、丢包、延时 |
本文将仅介绍Linux系统中的前7个网络性能分析工具。一开始是系统层面的统计数据,进而向下挖掘到包嗅探和事件跟踪。完整的功能请参考这些工具的文档,包括Man手册。
netstat
基于使用的选项,netstat(8)命令能报告多种类型的网络统计数据,就像具有多种功能的组合工具。选项介绍如下:
- (默认):列出连接的套接字。
- -a:列出所有套接字的信息。
- -s:网络栈统计信息。
- -i:网络接口信息。
- -r:列出路由表。
其他选项能修改输出,例如-n不解析IP地址为主机名,以及-v(可用时)显示冗长的详细信息。
一个netstat(8)接口统计信息的示例如下:

数据列包括网络接口(Iface)、MTU,以及一系列接收(RX-)和传输(TX-)的指标。
- OK:成功传输的数据包。
- ERR:错误数据包。
- DRP:丢包。
- OVR:超限。
丢包和超限是网络接口饱和的指针,并且能和错误一起用USE方法检查。
-c连续模式能与-i一并使用,每秒输出这些累积的计数器。它提供计算数据包速率的数据。
下面是一个netstat(8)网络栈统计数据(片段)的示例:


输出列出了多项按协议分组的网络数据,主要是来自TCP的。所幸的是,其中多数有较长的描述性名称,因此它们的意思显而易见。不幸的是这些输出缺乏一致性而且有拼写错误,用程序处理这段文字比较麻烦。
许多与性能相关的指标以加粗强调,用以指出可用的信息。其中许多指标要求对TCP行为的深刻理解,包括近些年引入的的最新功能和算法。下面是一些值得查找的示例指标。
- 相比接收的总数据包更高速的包转发率:检查服务器是否应该转发(路由)数据包。
- 开放的被动连接:监视它们能显示客户机连接负载。
- 相比发送的数据段更高的数据段重传输率:能支持网络的不稳定。这可能是意料之中的(互联网客户)。
- 套接字缓冲超限导致的数据包从接收队列中删除:这是网络饱和的标志,能够通过增加套接字缓冲来修复——前提是有足够的系统资源支持应用程序。
一些统计信息名称包括拼写错误。如果其他的监视工具建立在同样的输出上,简单地修复它们可能有问题。这类工具最好能从/proc资源读取这些统计信息,它们是/proc/net/snmp和/proc/net/netstat。例如:

/proc/net/snmp统计信息也用于SNMP管理信息库(MIB),它提供关于每个统计信息的用途的更进一步的文档。扩展的统计信息在/proc/net/netstat中。
netstat(8)可以接受以秒为单位的时间间隔,它按每个时间间隔连续地输出累加的计数器。后期处理这些输出可以计算每个计数器的速率。
sar
系统活动报告工具sar(1)可以观测当前活动并且能配置为保存和报告历史统计数据。第4章中介绍过它,并且本书的多个章节在需要时也会提及它。
Linux版本用以下选项提供网络统计信息。
- -n DEV:网络接口统计信息。
- -n EDEV:网络接口错误。
- -n IP:IP数据报统计信息。
- -n EIP:IP错误统计信息。
- -n TCP:TCP统计信息。
- -n ETCP:TCP错误统计信息。
- -n SOCK:套接字使用。
提供的统计信息见下表。
| 选项 |
统计信息 |
描述 |
单位 |
| -n DEV |
rxpkg/s |
接收的数据包 |
数据包/s |
| -n DEV |
txpkt/s |
传输的数据包 |
数据包/s |
| -n DEV |
rxkB/s |
接收的千字节 |
千字节/s |
| -n DEV |
txkB/s |
传输的千字节 |
千字节/s |
| -n EDEV |
rxerr/s |
接收数据包错误 |
数据包/s |
| -n EDEV |
txerr/s |
传输数据包错误 |
数据包/s |
| -n EDEV |
coll/s |
碰撞 |
数据包/s |
| -n EDEV |
rxdrop/s |
接收数据包丢包(缓冲满) |
数据包/s |
| -n EDEV |
txdrop/s |
传输数据包丢包(缓冲满) |
数据包/s |
| -n EDEV |
rxfifo/s |
接收的数据包FIFO超限错误 |
数据包/s |
| -n EDEV |
txfifo/s |
传输的数据包FIFO超限错误 |
数据包/s |
| -n IP |
irec/s |
输入的数据报文(接收) |
数据报文/s |
| -n IP |
fwddgm/s |
转发的数据报文 |
数据报文/s |
| -n IP |
orq/s |
输出的数据报文请求(传输) |
数据报文/s |
| -n EIP |
idisc/s |
输入的丢弃(例如,缓冲满) |
数据报文/s |
| -n EIP |
odisc/s |
输出的丢弃(例如,缓冲满) |
数据报文/s |
| -n TCP |
active/s |
新的主动TCP连接(connect()) |
连接数/s |
| -n TCP |
active/s |
新的被动TCP连接(listen()) |
连接数/s |
| -n TCP |
active/s |
输入的段(接收) |
段/s |
| -n TCP |
active/s |
输出的段(接收) |
段/s |
| -n ETCP |
active/s |
主动TCP失败连接 |
连接数/s |
| -n ETCP |
active/s |
TCP段重传 |
段/s |
| -n SOCK |
totsck |
使用中的总数据包 |
sockets |
| -n SOCK |
ip-frag |
当前队列中的IP数据片 |
fragments |
| -n SOCK |
tcp-tw |
TIME-WAIT中的TCP套接字 |
sockets |
这里,许多统计信息名称包括方向和计量单位:rx是“接收”,i是“输入”,seg是“段”,依此类推。完整的列表参考Man手册,它包括ICMP、UDP、NFS和IPv6在内的统计信息以及对应的SNMP名称的说明(例如,ipInReceives对应irec/s)。
以下示例是每秒打印的TCP统计信息:


输出显示被动连接率(入站)接近30/s。
网络接口统计信息列(NET)列出所有接口,然而通常只对一个接口感兴趣。以下示例利用awk(1)过滤输出:

这显示出传输和发送的网络吞吐量。这里双向的速率都超过了2MB/s。
ifconfig
ifconfig(8)命令能手动设置网络接口。它也可以列出所有接口的当前配置。用它来检查系统、网络以及路由设置有助于静态性能调优。
Linux版本的输出包括以下这些统计信息:

这些计数器与之前介绍的netstat -i命令一致。txqueuelen是这个接口发送队列的长度。Man手册介绍了这个数值的调优:
对于速度较低的高延时设备(调制解调器连接,ISDN),设置较小的值有助于预防高速的大量传输影响如telnet在内的交互通信。
Linux中,ifconfig(8)已经被ip(8)命令淘汰。
ip
Linux的ip(8)命令能配置网络接口和路由,并且观测它们的状态和统计信息。例如,显示连接统计信息:

除了添加了接收(RX)和传输(TX)字节,这些计数器与之前介绍的netstat -i命令一致。这利于方便地观测吞吐量,不过ip(8)不提供按时间间隔输出报告的方式(利用sar(1))。
nicstat
最初为基于Solaris的系统编写,nicstat(1)这个开源工具输出包括吞吐量和使用率在内的网络接口统计信息。nicstat(1)延续传统的资源统计工具iostat(1M)和mpstat(1M)的风格。用C和Perl编写的版本可用于基于Solaris和Linux的系统[3]。
例如以下的1.92 Linux版本的输出:

最前面的输出是自系统启动以来的总结,紧接着是按时间间隔的总结。这里的时间间隔总结显示了eth4接口的使用率为35%(这里报告的是当前RX或者TX方向的最大值),并且读速度为42MB/s。
字段包括接口名称(Int)、最大使用率(%Util)、反映接口饱和度的统计信息(Sat),以及一系列带前缀的统计信息:r是“读”(接收)而w是“写”(传输)。
- KB/s:千字节每秒。
- Pk/s:数据包每秒。
- Avs/s:平均数据包大小,以字节为单位。
该版本支持多种选项,包括-z用来忽略数值为0的行(闲置的接口)以及-t显示TCP统计信息。
由于能提供使用率和饱和度数值,nicstat(1)特别适用于USE方法。
ping
ping(8)命令发送ICMP echo请求数据包测试网络连通性。例如:
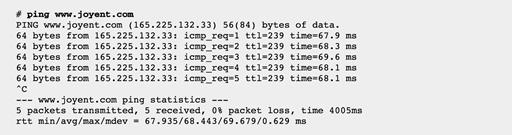
输出显示每个包的往返时间(rtt)并总结各种统计信息。由于时间戳是由ping(8)命令自己计量的,其中包括获取时间戳到处理网络I/O的整个CPU代码路径执行时间。
与应用程序协议相比,路由器可能以较低的优先级处理ICMP数据包,因而延时可能比通常情况下有更高的波动。
traceroute
traceroute(8)命令发出一系列数据包实验性地探测到一个主机当前的路由。它的实现利用了递增每个数据包IP协议的生存时间(TTL),从而导致网关顺序地发送ICMP超时响应报文,向主机揭示自己的存在(如果防火墙没有拦截它们)。
例如测试一个加利福尼亚的主机与一个弗吉尼亚的目标间当前的路由:
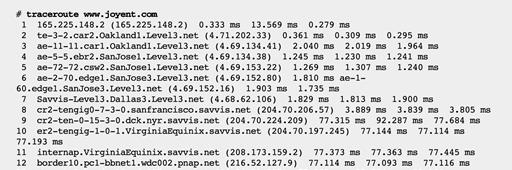
![]()
每一跳显示连续的三个RTT,它们可用作网络延时统计信息的粗略数据源。类似ping(8),由于发送低优先级的数据包,它可能会显示出比其他应用程序协议更高的延时。
也可以把显示的路径作为静态性能调优的研究对象。网络被设计为动态的并且能响应故障。路径的变化可能会降低性能。
书籍介绍

《性能之巅:洞悉系统、企业与云计算》基于Linux 和Solaris系统阐述了适用于所有系统的性能理论和方法,Brendan Gregg 将业界普遍承认的性能方法、工具和指标收集于本书之中。阅读本书,你能洞悉系统运作的方式,学习到分析和提高系统与应用程序性能的方法,这些性能方法同样适用于大型企业与云计算这类最为复杂的环境的性能分析与调优。