Docker在Coding WebIDE项目中的运用
随着云计算技术的日新月异,云端的代码仓库、分工协作、演示运行已经被人们广为接受。云端开发的出现也正是顺应了这一趋势。Docker作为一个轻量级的隔离环境,无疑是云端开发解决资源和效率问题的秘药良方。
记得4月份的杭州Docker Meetup有一参会者提问,“作为一个云主机的租户,向主机商购买的计算资源,其获得的配额不是真实值而只是上限,觉得不值。”这个问题似乎揭露了商家的生意经,但是本人却有不同的看法。正是因为共享技术的发展,才让云计算资源变得廉洁而被广为接受,Docker最大的价值也在这里。
从技术特性上看,VM和Docker有些重合点。但是虚拟机是基于Hypervisor技术的,而Docker是基于容器技术的。Hypervisor要比Container更底层,不是同一层面的竞争关系,真实的场景多是先 Hypervisor再Container,通俗的说法就是在VM里跑Container。
Hypervisor技术让多个操作系统共享一个CPU硬件,这些操作系统独立运行,并不知道彼此的存在,仿佛独占了所有的硬件资源。
Container技术让多个用户空间共享一个操作系统,这些用户空间彼此隔绝,仿佛独占整个操作系统。
我们都知道,文件是对I/O设备的抽象表示,虚拟存储器是对主存和磁盘I/O设备的抽象表示,进程则是对处理器、主存和I/O设备的抽象表示。相比之下,虚拟化将操作系统从硬件中抽象出来,容器技术将应用从操作系统抽象出来。
一个正在执行的进程,由于虚拟内存技术,就其视角来看,仿佛拥有了整个操作系统的计算资源。但是Container的抽象和进程抽象不是在一个层面的。简单说,一台物理设备可以借助于Hypervisor技术,运行多个VM;而个操作系统可以借助Container技术,运行多个 Container,Container里又可以有多个进程。
上面简单的介绍了一些Docker技术的背景,言归正传。
为什么选用Docker而不是更成熟的VM
实现WebIDE首先解决的就是环境隔离,多个用户之间不会相互干扰。物理机是相互隔离的,但是为每一个用户分配一台真实的物理机,显然是不合现实的。
VM可以提供和物理机一样的隔离效果,由于VM共享硬件,所以更省资源。一个可行的方案是借助IaaS平台商提供的OpenAPI来操作VM。这样对物理主机和宿主操作系统的维护工作可以完全委托给IaaS平台商。
相比Docker Container,VM有一个很大的技术优势是支持休眠。操作系统在系统级实现了休眠,这样用户的工作状态,内存中的数据可以完整的持久化。作为一个常年不关机的开发者,个人觉得这个功能非常实用。可惜Docker只提供了睡眠(类似于进程级别的挂起),而做不到休眠。随着CRIU技术的发展,相信Docker很快会支持的。
另外VM在不同宿主机之间的迁移问题,经过多年社区的积累越来越成熟。如果选择向IaaS平台商购买VM服务,这部分工作也不用关心。Docker Container数据的迁移,面临着自制。目前Docker官方提供迁移Container(非image)的命令,只能迁移文件,无法保留状态(比如外部mount的目录)。
考虑到架构的微服务化,如文件服务、Git 服务、Terminal 服务、Runtime服务。有些服务是单例的,另一些则会随着用户会话状态而动态地创建和销毁。当应用实例很多的时候,虚拟化技术的Overhead是需要考虑的因素。为了某个服务而启动整个操作系统有些负担不起。除了过度的内存消耗,启动耗时也存在差异,Container只是用户空间的一个或者一组进程,所以启动耗时基本是毫秒级别,而VM至少是秒级,有的甚至是分钟级(休眠还原的时候)。
做比较的时候总是各有优劣,但最终打动我们的除了Docker的轻量,还有其生机勃勃。我们相信备受社区关注的技术,许多顾虑的问题终究会有解决方案的。
基于Container的Web Terminal
一个完整的IDE需要具备很多功能,比如文件管理、版本管理、编辑器、编译器、执行环境等等。初次上线的最小功能集合里,我们认为Web IDE区别于Web Editor的一个功能亮点就是Web Terminal。
Web Terminal和SSH的工作原理类似,通过架设在TCP之上的应用层协议实现对主机的远程控制。相信大多数开发者都有SSH的使用经验,理解其工作原理的仅占少数。开始研究之初,我们也和大多数人一样搞不清楚terminal、tty、pty、shell、bash之间的区别,所以先来理理概念。
什么是Terminal?
从用户的角度来看,Terminal是键盘和显示器的组合,也称为TTY(电传打字机的缩写)。键盘输入字符,显示器显示字符。从进程的角度来看,终端是字符设备,可以通过read、write、ioctl等系统调用来读写和控制该设备。
TTY早已进入了博物馆,桌面系统上字符界面基本被GUI界面替代。取而代之是一个称之为Terminal Emulator(终端模拟器)的窗口程序,该程序显示的字符界面就是曾经物理显示器里的完整内容。
Terminal作为真实的物理设备已经不复存在了,但是为了和面向终端的程序(比如Bash)进行通信,于是就了发明了 pty(Pseudoterminal,伪终端)。pty是一对master-slave设备,master设备表现得像一个文件,slave设备表现得像一个终端设备,当Terminal Emulator作为一个非面向终端的程序不直接与pty slave通讯,而是通过文件读写流与pty master通讯,pty master 再将字符输入经过线路规程的转换传送给slave,slave进一步传递给bash。
Bash是一个命令行的解释器,通常也是进程会话的主进程,其职责是解释执行终端设备(或者伪终端的slave设备)传递过来的字符串和控制字符,执行命令。
Web Terminal 的工作原理
理解了上面背景知识之后,再看SSH的原理图。
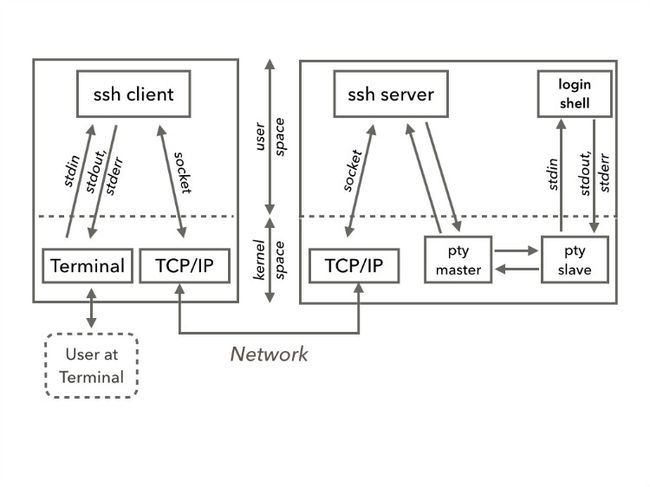
SSH是一个典型的server-client模式架构,用户通过终端将字符流传递给SSH client。SSH client和SSH server之间通过TCP/IP协议进行通讯。远端的server创建一对pty,并且fork+exec一个bash进程,server进程通过pty对与bash进行交互。
仿照SSH的工作原理,我们在HTTP协议之上设计了Web Terminal,见下图:
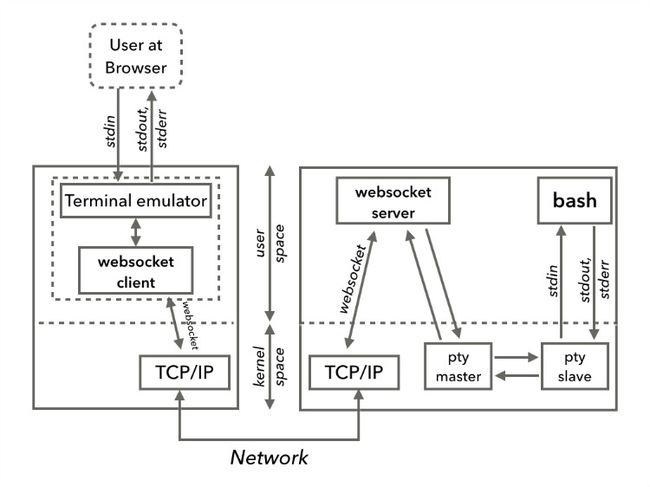
真实实现中,Socket.io是应用层的通讯协议。Terminal Emulator是一个纯JS的实现,Node.js后端使用pty.js模块来创建pty对。
当解决了Web Terminal的整体架构以后,嵌入Docker Container已是水到渠成。
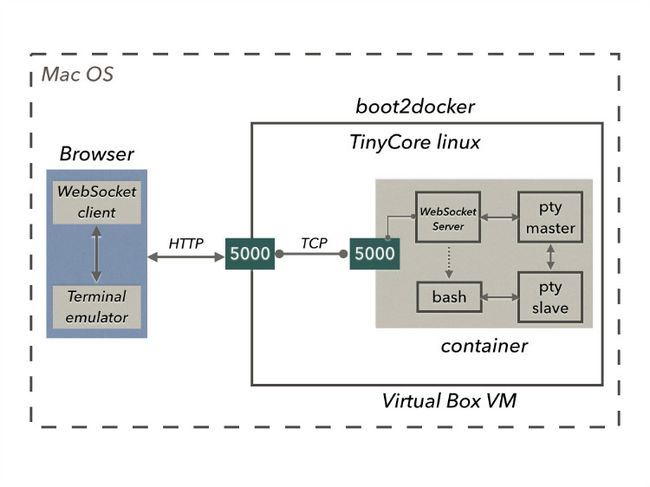
僵尸进程问题
我们知道Docker由于缺少init 0而导致僵尸进程无法回收的问题迄今存在。Terminal作为控制终端,会在使用过程中执行若干命令,这些命令对应进程如果与其父进程脱离父子关系,那僵尸进程问题就来了。
Docker官方推荐的一个Container只跑一个进程。如果Container 与进程同生共死,僵尸进程的问题基本不会遇到。但是Web Terminal所在Container里启动了bash,而bash可以随意执行命令启动进程,僵尸进程问题很难避免。好在社区提供了更好的解决方案:phusion/baseimage。在Dockerfile里将的 FROM ubuntu改为FROM phusion/baseimage,再按照文档说明做些调整基本就好了。
Container 作为构建和管理工具
通常,我们都是把App部署到Docker里去。大致步骤就是编写Dockerfile,再构建成image,然后借助private registry在分布式的集群中分发。由于开发环境、测试环境和生产环境存在差异,往往构建交付物涉及到大量参数和环境变量的设定,过程非常繁琐,一般都会脚本化。所以IDE项目基本都是Dockerfile旁边放置了一个Gemfile和Rakefile。通过Ruby Rake来驱动整个构建过程。
作为脚本语言与Shell相比,Ruby的好处是:
- 隔绝了Darwin,Linux平台之间某些命令的细微差异;
- 对于Shell擅长的部分,可以通过'`'符号方便的嵌入调用;
- 具备完备正则等字符串处理功能;
- 方便调用Docker api的;
- 可以集成Capistrano等分布式管理工具;
但Ruby不像Shell那样信手拈来,需要进行适当的配置,比如,RVM安装指定版本,修改gem source之类的。
从前配置这些基础环境,都是记录成Markdown文档,一堆 apt-get、sed指令。但是引入Docker以后,有更好的选择。
我们的方式如下:
编写一个配置构建环境的Dockerfile,构建成image。
docker build --rm -t="ide-docker-registry.coding.local/ide-builder:0.0.5" .
push到registry里。
docker push ide-docker-registry.coding.local/ide-builder
在构建服务器创建构建所需的builder,通过mount外部目录的方式,构建环境和外部环境交互文件。
docker run --name coding_ide_builder -d -t -v $CODING_IDE_HOME:/data/coding-ide-home --net=host --restart=always ide-docker-registry.coding.local/ide-builder
进入构建环境执行命令。
docker exec -i -t coding_ide_builder bash
或者直接构建。
docker exec -i -t coding_ide_builder rake
Container环境的资源限制问题
资源限制主要针对CPU、内存、磁盘和网络带宽等共享资源的限制。一方面,我们提倡共享,事实上不是所有的用户都需要长时间的占满所需的资源配额,不需要的时候可以释放出来分享给其他用户,因为共享才会更便宜。另一方面,也需要对可共享资源设定一个最大的限制配额,以防止某些用户过度占用而影响其他用户的使用体验。
CPU限制
Docker提供了两个参数来控制CPU的分配策略,--cpuset和--cpu-shares 。
--cpuset="0" [...] 将Container限定于某几个CPU核心上。针对这一特性,我们制定的策略是将重要的Container服务分配在独立的核心上,以保证服务的质量。
--cpu-shares可以调节Container获得的时间片。我们通过这个配置来调节Web Terminal所创建进程对CPU的占用率。
内存限制
Web Terminal里用户的自由度是很大的,对内存限制可以减少恶意破坏。Docker配置内存限制相对简单。另外,我们禁用了swap分区,以减少对磁盘的压力。
磁盘限制
由于用户可以完全自由的访问磁盘,我们最希望Container 磁盘镜像文件具备thin provisioning特性,不需要预分配所有空间也可以限定其大小。
对于Container的磁盘限制分为两部分,对最上层可写layer的限制和对被mount的可写目录的限制。
限制可写layer
Docker Daemon提供了四种storage-driver:aufs、devicemapper、btrfs、overlay。如果Linux发行版本支持aufs,那它就是默认的storage-driver,反之则是devicemapper。aufs最早被Docker支持,而且支持共享二级制文件和动态库文件所占用的内存,btrfs和overlay不支持此特性,但是比aufs速度更快。devicemapper 的特点是支持thin provisioning和copy on write。
限制layer的大小,devicemapper是目前唯一的选择。启动devicemapper后,Docker会为所有的Container创建一个共享存储池,其实质上是一个大文件,另外也会限定每个Container的大小。这两个数字的制定需要慎重,因为考虑到数据迁移,修改很不容易。
限制被mount的可写目录
Docker run的时候mount进Container的可写目录是不受devicemapper的限制,所以需要额外处理。WebIDE场景中workspace目录是被多个Container实例中共享读写的,作为用户工作目录,需要设定一个最大的空间限制。
谈到Linux磁盘空间限制,最先想到quota,它常用于ftp服务中限定用户最大可用空间。但quota有一个技术限制,仅仅适用于整个文件系统而无法针对单个目录。所以quota方案在共享目录的场景不可行。
Linux支持将一个磁盘镜像文件mount成目录,磁盘镜像文件可以限定大小。当镜像文件撑满的时候,目录就不可写了。这是我们目前找到最靠谱的方案。
限制网络带宽
Docker没有直接提供限制网络带宽的命令行参数,但借助Docker 的底层技术Cgroup可以实现。创建一个 Network classifier group,对 cgroup 进行带宽限制的设定,将 Container 都指定到该组里去。Traffic Controller(tc) 和 Netfilter(iptables) 都支持针对 cgroup 指定规则。
关于Dockerize的程度与思考
基于Docker更容易实现架构的微服务化。借助于Docker的link特性和Fig工具,Container可以像乐高积木一样把所有的组件都组合起来。Nginx、Jetty、MySQL、Redis等一系列服务都可以封装到独立的Container中去。
全面Dockerize的最大好处是整个体系都是一致的,所有的组件都是Container。WebIDE在架构初期,考虑全面Dockerize的方案,比如把MySQL分成两个Container,一个存放安装文件,另一个存放数据文件。应用服务器自不必说也在Container里。但是当考虑Nginx是否也要放进Container里,大家想法有些分歧,Container的价值在Nginx上是否明显值得探讨。也正因为存在不同的声音,我们放弃了全面Dockerize。个人的觉得已有的经验和脚本不应该放弃,我们应该节省出更多的精力来做更重要和紧迫的事情。
作者简介
杜万,Coding.net 全栈工程师,目前负责Coding WebIDE项目的架构和研发。从事了近10年以Java语言为主的软件开发工作,热衷于整合框架和开发工具,关注交互设计,喜欢写技术博客,Linux拥趸。近期开始学习和关注 Elixir 函数语言。
参考阅读
- Hypervisor - Wikipedia
- Operating-system-level virtualization - Wikipedia
- User space - Wikipedia
- Basics – Docker, Containers, Hypervisors, CoreOS
- devicemapper - a storage backend based on Device Mapper
- Resizing Docker Containers with the Device Mapper plugin
- Network classifier cgroup