搜索的思考
前段时间上了某论坛的技术讨论区,习惯性的打开搜索看有没有我需要的内容,一登陆账号,发现自己被禁言了,连基本的搜索功能也被限制了。无奈只能手动的一个一个会找帖子。我去,竟然有200多页,每页有40第数据,这样纯手工的方式实在是太蛋疼了。
前段时间自己不是写了一个小爬虫吗?于是我的个人论坛搜索器开始构建了。
一,整体构建
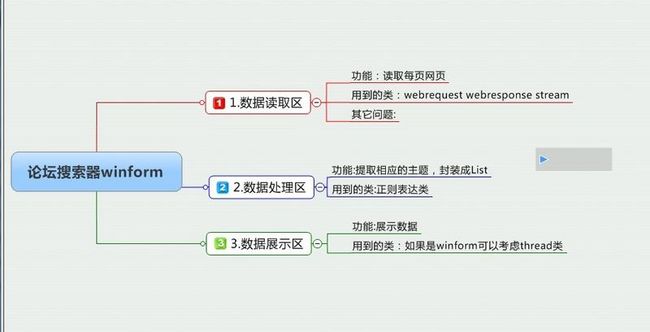
二,实际编码
1,数据读取编码:
读取网页有很多种方法,第一读取网页我选择的是最简单的方式
static string GetPage(int page)
{
string reuslt = string.Empty;
System.Net.WebClient wb = new System.Net.WebClient();
reuslt = wb.DownloadString("http://xx.xxx.xx/thread0806.php?fid=7&search=&page=" + page);
return reuslt;
}
直接利用webclient 读取内容:

咦,这是怎么回事?
直接访问是不可以的,哪里出错了呢?
难不成是地址出错了?我重新检查了一次没有拼错,那换成其它地址呢?

测试可以使用,那就是说这种请求方式只对百度有效。
那说明:直接使用webClinent类来请求xx.xxx.xx这种网站是不可行的,因为它会来接收你的请求头的信息来判断是人工发出的请求还是非人工发出的请求。
如何构造请求头是关键!
那换用另一种方式来请求来,如果要构建新的请求方式,那首先要明白,一次“人工的请求方式”应该是怎么样的,打开chrome,监视了一次请求,得到结果如下:
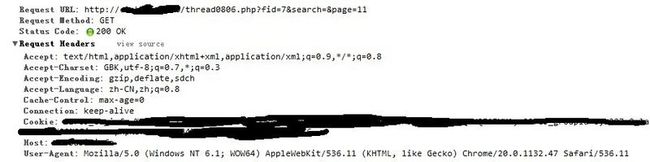
一次合理的请求方式包含哪些信息呢?
url:请求地址
Method:请求方式
Headers:
Accept:本次请求得到的回应的数据格式,版本
Accept-Charset:我这次请求可以接受的编码格式 GBK,UTF-8;q=0.7
Accept-Encoding:编码格式(gzip格式)
Accept-Language:中文
Cache-Control:缓存设置
User-Agent:请求标识头部分
OK,这些既然得到了,那可以开始构建一次正常的请求了。
static string Getpage(int page) { System.IO.Stream response; System.IO.StreamReader sr; string result = string.Empty; string domain = "http://xx.xxx.xx/thread0806.php?fid=7&search=&page=" + page; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(domain); request.Method = "GET"; request.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"; request.Headers.Set("Accept-Charset", "GBK,utf-8;q=0.7,*;q=0.3"); request.Headers.Set("Accept-Language", "zh-cn,zh;q=0.5"); request.Headers.Set("Accept-Encoding", "gzip,deflate,sdch"); request.Host = "xx.xxx.xx"; request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.47 Safari/536.11"; request.KeepAlive = true; HttpWebResponse httprp = (HttpWebResponse)request.GetResponse(); httprp.Headers.Set("Content-Encoding", "gzip"); response = httprp.GetResponseStream(); sr = new System.IO.StreamReader(response,Encoding.UTF8); result = sr.ReadToEnd(); response.Close(); sr.Close(); return result; }
OK,那测试一下看得到数据没有.
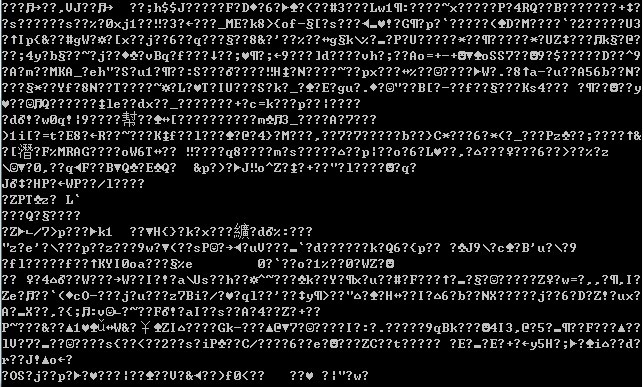
怎么都是乱码呢?
设置读取的时候都是正常的UTF-8编码,如果读取的编码没有问题,那问题应该出在传送的编码上面。我竟然忽略了返回的格式了
httprp.Headers.Set("Content-Encoding", "gzip");
很明显,文档经过了Gzip格式进行压缩,然后在传送过来了,那需要解码一次:代码如下
static
string
Getpage(
int
page)
{
System.IO.Stream response;
System.IO.StreamReader sr;
string
result =
string
.Empty;
string
domain =
"http://xx.xxx.xx/thread0806.php?fid=7&search=&page="
+ page;
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(domain);
request.Method =
"GET"
;
request.Accept =
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
;
request.Headers.Set(
"Accept-Charset"
,
"GBK,utf-8;q=0.7,*;q=0.3"
);
request.Headers.Set(
"Accept-Language"
,
"zh-cn,zh;q=0.5"
);
request.Headers.Set(
"Accept-Encoding"
,
"gzip,deflate,sdch"
);
request.Host =
"xx.xxx.xx"
;
request.UserAgent =
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.47 Safari/536.11"
;
request.KeepAlive =
true
;
HttpWebResponse httprp = (HttpWebResponse)request.GetResponse();
httprp.Headers.Set(
"Content-Encoding"
,
"gzip"
);
response = httprp.GetResponseStream();<br>
//重新修改后的代码
sr =
new
System.IO.StreamReader(
new
GZipStream(response, CompressionMode.Decompress), Encoding.GetEncoding(
"gb2312"
));
result = sr.ReadToEnd();
response.Close();
sr.Close();
return
result;
}
|
那得到结果没有呢?
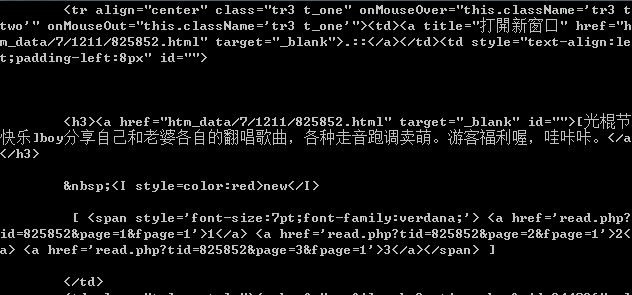
OK,正常得到结果!那下面的工作就简单了~
PS:晚上继续更新第二部分,(数据展示内容---正则表达式的应用)
HTML5资料整理
项目组要做html5这块,花了一周左右时间收集的,快有一年时间了,部分内容需要更新,仅供参考。
几点说明:
- 本次收集的信息以HTML5为主,这里的HTML5 ~= HTML5 + Javascript + CSS3
- 以下资料的协议相关部分主要来自W3C、WHATWG;demo库和开发工具等主要来自IT企业、技术组织的官网或其信息站点
- W3C正式发布的协议称为Recommendation(推荐),下文中“协议”、“推荐”、“REC”是同义词;“协议”未通过之前以“草案”的形式存在
[基本信息]
2个组织
- W3C,万维网联盟,Web标准制定者
- WHATWG,由浏览器厂商的员工发起的非正式组织,致力于改进HTML,其成员来自Mozilla、Opera、Apple、Google等
HTML5发展
- HTML 4.01于1999年发布,2000年W3C发布了XHTML 1.0
- 第一份正式草案公布于2008.1.22,最新草案发布于2011.9.6
- HTML5草案的前身为Web Applications 1.0,2004年由WHATWG提出,2007年被W3C接纳,并成立了新的HTML工作组(合并XHTML团队)
| “WHATWG致力于web表单和应用程序,而W3C专注于XHTML 2.0。在2006年,双方决定进行合作,来创建一个新版本的HTML” —— 摘自W3school。 |
- WHATWG目前仍然是HTML5的主力,HTML5的最新进展会发布在这两个组织的官网,以下默认使用W3C公布的信息
HTML5的新特性体现在下图显示的8个部分,HTML5希望创建一个有本地存储、富客户界面、高效网络IO的Web App。HTML5 Presentation是以下文字和图表更加直观的版本:
- 语义(Semantic),新增header、footer、nav、fig等含有语义的标签,以及一系列含有语义的标签属性
- 离线&存储(Offline&Storage),主要包括Local Storage、Indexed DB、File API
- 设备访问(Device Access),定位信息已经广泛应用,其他还有视频、音频流(如语音输入 ),移动设备的传感器(如方向传感器)
- 网络连接(Connectivity),增加Web Socket、服务器数据推送
- 多媒体(Multimedia),增加video、audio标签,提供原生的视频、音频访问
- 图形接口(GDI),增加canvas标签,提供2D,3D GDI,现已有第3方的WebGL可以提供3D加速渲染
- 性能&整合(Performance & Integration),Web Workers实现脚本后台运行,并提供前后台交互接口,XMLHttpRequest 2提供更好的网络IO
- CSS3,目前仍在开发之中,主流浏览器已经支持其中部分特性,Dashboard是更完整的CSS3 demo
|
|

最新进展参见WHATWG News和W3C HTML首页:
- 最新草案发表于2011.9.6
- W3C希望能在2014让html5成为Recommendation ,参见html5 FAQ
|
|

[Demo库]
这里将所有demo库粗略分为应用和游戏,涵盖了组织、企业、个人开发或收集的demo
[应用demo库]
Edge的Samples,Adobe Edge制作的html5动画
- Adobe请Rain制作的logo动画1、动画2
- 比较精美的齿轮动画
- 过山车动画
- 2个Banner广告
- 简单的banner动画广告,js库文件138KB, 动画自身js+css 10KB
- 另一个Banner公益广告
Html5Rocks, Google demo库
- HTML5 Presentation ,h5版ppt,详细介绍了h5的新特性,里面的demo可直接玩
- WebGL Globe,使用WebGL 3D加速,展示canvas 3D特性
- Ascii Art,使用WebSocket同步服务器数据(字符视频)
- Notification Time,Notification API,提供页面范围以外的消息提示,目前主流浏览器中只有chrome实现
- Drag n Drop Photos, 拖拽文件到浏览器,使用DnD,File API
- Page Flip,书本翻页,基于CSS3 2D transform和animation
html5demos ,人气很高的第三方demo库,提供按特性过滤查看demo
Web O' Wonder,奇幻网络,Mozilla提供的demo库
- Dashboard,展示HTML5、CSS3、SVG、JS等技术的新特性,CSS3的demo很丰富
Safari Technology Demos,Apple提供的demo库
- Photo Transitions,图片切换的动画效果
- Gallery,幻灯片,多种展现模式:水平、垂直、3D滚动..
- 虚拟现实(VR),基于css3 transforms
- 360°,360°旋转,本以为是3D效果,竟然用了72张图片
IE Test Drive,Microsoft为IE开的demo库站点,大量html5的demo
10K Apart,HTML5竞赛作品,基本要求是打包后10KB以内
canvasdemos,专注于canvas的demo库
HTML5研究小组收集的demo库,“HTML5研究小组”是中国首个HTML5推广和交流的开放组织
一些零散的demo:
- iGrapher,很炫的报表程序
- Cloudkick,3D,显示云服务器状态
[游戏demo库]
Mozilla Labs Gaming,Mozilla官方的html5游戏demo库,下面是库中获奖作品
- Marble Run,冠军游戏(best web-iness),画面精细,chrome13下运行较流畅(汗)
- Robots are people too,获得“最有趣奖”(most fun)
html5games,第三方游戏demo库
- html5版的俄罗斯方块
HTML5研究小组收集的游戏demo库
游戏引擎:Impact、Rocket、GameClosure、YoYo
一些零散的demo:
- CubeSpace,搭积木,强大的回放功能
[兼容性]
Html5 test,提供html5新特性的检测
html5兼容性手册
- Where can I use..,提供详尽的兼容性信息,提供按特性查找
- HTML5 readiness,数据来源于前者,提供按时间查询HTML5兼容性,有趣的展现形式
Compatibility Master Table,quirksmode提供的兼容性数据库,涵盖了DOM、CSS、JS等
HTML5 in Firefox,Mozilla 提供的Firefox html5兼容性列表
HTML5 in Chrome,Chromium提供的开发进度信息
HTML5 in IE:官方版本,非官方版本,
Mobile HTML5,Mobile Browser对HTML5的支持
兼容性工具
- Compatibility Detector for Firefox,Firefox插件
- W3C HTML验证,支持对html5文档进行验证
- W3C CSS验证,还不支持CSS3
- html5shiv,让IE支持大部分html5特性,2KB
[开发]
开发手册&文档
- HTML5 参考手册(中文版,英文版),W3school的入门级手册,内含简单的demo
- HTML5: Edition for Web Authors,W3C面向web开发者的高级手册 WHATWG版本
- HTML5 full specification,完整版手册,主要面向浏览器厂商 WHATWG版本
- Dive Into HTML5,免费的在线h5教程
- Mozilla HTML5
Edge,Adobe开发的html5动画制作工具,生成的动画依赖的库较多,直接用于mobile设备文件过大
Swiffy,flash转html5工具
Modernizr,javascript库,对html5、css3 做退化处理
CSS3-HTML5之家,国内的一个站点
HTML5研究小组
Scirra,HTML5 游戏开发平台(付费)