Hadoop Serialization hadoop序列化详解(最新版) (1)【java和hadoop序列化比较和writable接口】
初学java的人肯定对java序列化记忆犹新。最开始很多人并不会一下子理解序列化的意义所在。这样子是因为很多人还是对java最底层的特性不是特别理解,当你经验丰富,对java理解更加深刻之后,你就会发现序列化这种东西的精髓。
谈hadoop序列化之前,我们再来回顾一下java的序列化,也是最底层的序列化:
在面向对象程序设计中,类是个很重要的概念。所谓“类”,可以将它想像成建筑图纸,而对象就是根据图纸盖的大楼。类,规定了对象的一切。根据建筑图纸造房子,盖出来的就是大楼,等同于将类进行实例化,得到的就是对象。
一开始,在源代码里,类的定义是明确的,但对象的行为有些地方是明确的,有些地方是不明确的。对象里不明确地方,是因为对象在运行的时候,需要处理无法预测的事情,诸如用户点了下屏幕,用户点了下按钮,输入点东西,或者需要从网络发送接收数据之类的。后来,引入了泛型的概念之后,类也开始不明确了,如果使用了泛型,直到程序运行的时候,才知道究竟是哪种对象需要处理。
对象可以很复杂,也可以跟时序相关。一般来说,“活的”对象只生存在内存里,关机断电就没有了。一般来说,“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。想象一下,对象怎么出现的,一般是new出来的,new出来的对象在内存里面,另外的计算机怎么可能使用我这台机器上的对象呢?如果要的话,序列化就是你必须要使用的东西。
序列化,可以存储“活的”对象,可以将“活的”对象发送到远程计算机。
把“活的”对象序列化,就是把“活的”对象转化成一串字节,而“反序列化”,就是从一串字节里解析出“活的”对象。于是,如果想把“活的”对象存储到文件,存储这串字节即可,如果想把“活的”对象发送到远程主机,发送这串字节即可,需要对象的时候,做一下反序列化,就能将对象“复活”了。
有例子为证:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
public
class
Person
implements
Serializable {
private
String name =
null
;
private
Integer age =
null
;
private
Gender gender =
null
;
public
Person() {
System.out.println(
"none-arg constructor"
);
}
public
Person(String name, Integer age, Gender gender) {
System.out.println(
"arg constructor"
);
this
.name = name;
this
.age = age;
this
.gender = gender;
}
public
String getName() {
return
name;
}
public
void
setName(String name) {
this
.name = name;
}
public
Integer getAge() {
return
age;
}
public
void
setAge(Integer age) {
this
.age = age;
}
public
Gender getGender() {
return
gender;
}
public
void
setGender(Gender gender) {
this
.gender = gender;
}
@Override
public
String toString() {
return
"["
+ name +
", "
+ age +
", "
+ gender +
"]"
;
}
}
|
SimpleSerial,是一个简单的序列化程序,它先将一个Person对象保存到文件person.out中,然后再从该文件中读出被存储的Person对象,并打印该对象。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public
class
SimpleSerial {
public
static
void
main(String[] args)
throws
Exception {
File file =
new
File(
"person.out"
);
ObjectOutputStream oout =
new
ObjectOutputStream(
new
FileOutputStream(file));
Person person =
new
Person(
"John"
,
101
, Gender.MALE);
oout.writeObject(person);
oout.close();
ObjectInputStream oin =
new
ObjectInputStream(
new
FileInputStream(file));
Object newPerson = oin.readObject();
// 没有强制转换到Person类型
oin.close();
System.out.println(newPerson);
}
}
|
上述程序的输出的结果为:
arg constructor
[John, 31, MALE]
将对象序列化存储到文件,术语又叫“持久化”。将对象序列化发送到远程计算机,术语又叫“数据通信”。
Java对序列化提供了非常方便的支持,在定义类的时候,如果想让对象可以被序列化,只要在类的定义上加上了”implements Serializable”即可,比如说,可以这么定义”public class Building implements Serializable”,其他什么都不要做,Java会自动的处理相关一切。Java的序列化机制相当复杂,能处理各种对象关系。
那么序列化这种操作我们怎么衡量他好不好呢?主要是压缩,速度,扩张,兼容四方面考虑。
hadoop通讯格式需求
hadoop在节点间的内部通讯使用的是RPC,RPC协议把消息翻译成二进制字节流发送到远程节点,远程节点再通过反序列化把二进制流转成原始的信息。RPC的序列化需要实现以下几点:
1.压缩,可以起到压缩的效果,占用的宽带资源要小。
2.快速,内部进程为分布式系统构建了高速链路,因此在序列化和反序列化间必须是快速的,不能让传输速度成为瓶颈。
3.可扩展的,新的服务端为新的客户端增加了一个参数,老客户端照样可以使用。
4.兼容性好,可以支持多个语言的客户端
hadoop存储格式需求
表面上看来序列化框架在持久化存储方面可能需要其他的一些特性,但事实上依然是那四点:
1.压缩,占用的空间更小
2.快速,可以快速读写
3.可扩展,可以以老格式读取老数据
4.兼容性好,可以支持多种语言的读写
Java的序列化机制的缺点就是计算量开销大,且序列化的结果体积大太,有时能达到对象大小的数倍乃至十倍。它的引用机制也会导致大文件不能分割的问题。这些缺点使得Java的序列化机制对Hadoop来说是不合适的。于是Hadoop根据自己上门的需求设计了自己的序列化机制。
Hadoop 使用自己的序列化格式Writables ,它紧凑、快速(但不容易扩展或lava 之外的语言)。由于Writables 是Hadoop 的核心(MapReduce 程序使用它来序列化键/值对),所以在转而简要讨论其他几个有名的序列化框架(比如Apache 的Thrift 和谷歌的Google Protocol Buffers)之前.我们先深入探讨一下.
Hadoop通过Writable接口实现的序列化机制,不过没有提供比较功能,所以和java中的Comparable接口合并,提供一个接口WritableComparable。
Writable接口提供两个方法(write和readFields)。
|
1
2
3
4
5
|
package
org.apache.hadoop.io;
public
interface
Writable {
void
write(DataOutput out)
throws
IOException;
void
readFields(DataInput in)
throws
IOException;
}
|
- package org.apache.hadoop.io;
- public interface WritableComparable <T> extends org.apache.hadoop.io.Writable, java.lang.Comparable<T> {
- }
MapReduce在排序部分要根据key值的大小进行排序,因此类型的比较相当重要,RawComparator是Comparator的增强版。
hadoop中使用的key类型都要事先比较的接口。并且hashcode在hadoop区分keyd 时候会频繁使用,因此确保实现hashcode的输出在不同jvm一样很重要。
- package org.apache.hadoop.io;
- public interface RawComparator <T> extends java.util.Comparator<T> {
- int compare(byte[] bytes, int i, int i1, byte[] bytes1, int i2, int i3);
- }
s1 s2时开始位置,l1,l2是长度,读取之后比较。这个就不需要反序列化。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
public
class
TestComparator {
RawComparator<IntWritable> comparator;
IntWritable w1;
IntWritable w2;
/**
* 获得IntWritable的comparator,并初始化两个IntWritable
*/
@Before
public
void
init() {
comparator = WritableComparator.get(IntWritable.
class
);
w1 =
new
IntWritable(
163
);
w2 =
new
IntWritable(
76
);
}
/**
* 比较两个对象大小
*/
@Test
public
void
testComparator() {
Assert.assertEquals(comparator.compare(w1, w2) >
0
,
true
);
}
/**
* 序列号后进行直接比较
*
* @throws IOException
*/
@Test
public
void
testcompare()
throws
IOException {
byte
[] b1 = serialize(w1);
byte
[] b2 = serialize(w2);
Assert.assertTrue(comparator.compare(b1,
0
, b1.length, b2,
0
, b2.length) >
0
);
}
/**
* 将一个实现了Writable接口的对象序列化成字节流
*
* @param writable
* @return
* @throws java.io.IOException
*/
public
static
byte
[] serialize(Writable writable)
throws
IOException {
ByteArrayOutputStream out =
new
ByteArrayOutputStream();
DataOutputStream dataOut =
new
DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return
out.toByteArray();
}
}
|
额外说一句,从git上下载的hadoop项目本身自带很多test类,大家可以多多尝试一下。
权威指南原文用intwritable 举例说明hadoop如何序列化:
|
1
2
3
4
5
6
7
|
public
static
byte
[] serialize(Writable writable)
throws
IOException {
ByteArrayOutputStream out =
new
ByteArrayOutputStream();
DataOutputStream dataOut =
new
DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return
out.toByteArray();
}
|
|
1
2
3
4
5
6
7
8
|
public
static
byte
[] deserialize(Writable writable,
byte
[] bytes)
throws
IOException {
ByteArrayInputStream in =
new
ByteArrayInputStream(bytes);
DataInputStream dataIn =
new
DataInputStream(in);
writable.readFields(dataIn);
dataIn.close();
return
bytes;
}
|
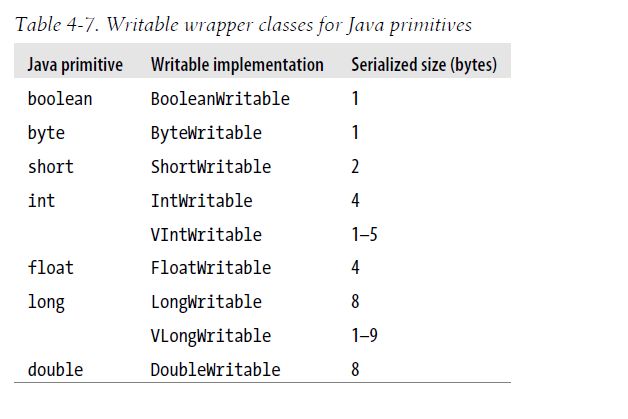
这是目前所有Writeable 的Java 基本类的封装(见表4-哟,此外还有short 和char 类型(两者均可存储在Int W rita ble 中)。它们都有用于检索和存储封装值的get () 和set ( )方撞.
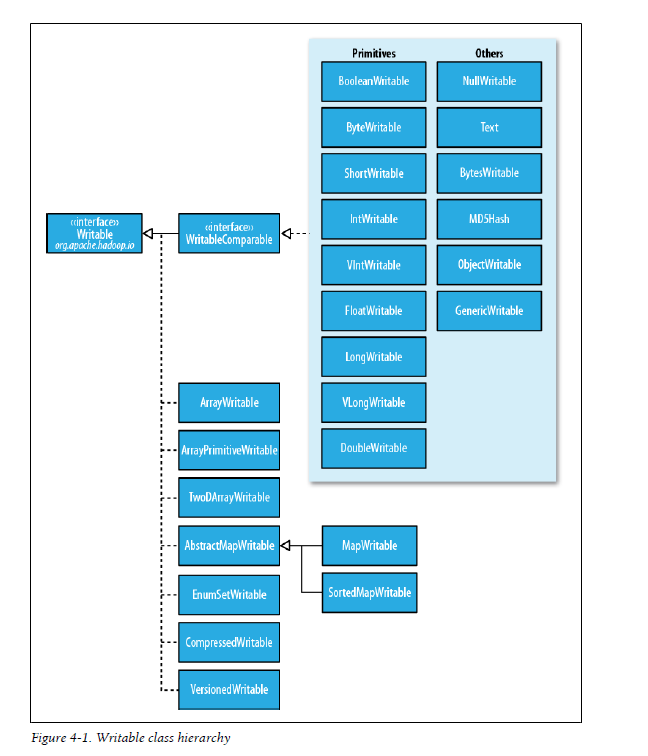
类结构:
在对整数进行编码时,在固定长度格式。intWritable 和LongWritable)和可变长度格式(VlntWritable 和vLongWritable ) 之闹,有一个选择.如果值足够小(-112 和127 之问.包含这两个值) ,可变长度格式就只用一个字节来对值进行编码,否则,使用第一字节来表示值为正还是负,以及后面还有多少字节。
如何在固定长度和可变长度编码之间进行选择?固定长度编码的好处在于值比较均匀地分布在整个值空间中,就像(精心设计)的散列函数。大多数数字变量往往分布, 所以可变长度编码往往更节省空间。可变长度编码的另一个好处是可以将VintWritable 变为VLongWritable ,因为它们的编码实际上是相同的. 因此,通过选择可变长度的编码方式,使空间可以增长,而不是一开始就占用8字节的空间。
权威指南对这些类都有一一介绍,在此不再赘述。
Charles 2015-12-23 于P.P
版权说明:
本文由Charles Dong原创,本人支持开源以及免费有益的传播,反对商业化谋利。
CSDN博客:http://blog.csdn.net/mrcharles
个人站:http://blog.xingbod.cn
EMAIL:[email protected]