架构设计:负载均衡层设计方案(9)——负载均衡层总结下篇
(接上一篇《架构设计:负载均衡层设计方案(8)——负载均衡层总结上篇》)
3、负载均衡层技术汇总
3-4、Keepalived技术
Keepalived在我的博客文章《架构设计:负载均衡层设计方案(7)》(http://blog.csdn.net/yinwenjie/article/details/47211551)、《架构设计:负载均衡层设计方案(6)》(http://blog.csdn.net/yinwenjie/article/details/47130609)中都有介绍。大家可能注意到,在这些文章中从来没有单独介绍Keepalived。这是因为Keepalived是为了监控集群节点的工作状态,在因为某种原因不能正常提供服务的前提下,完成备机的切换。这里面有两个关键点:监控节点上提供的服务、完成网络切换。keepalived本身是不提供业务服务的,只是监控提供的服务是否正常工作,那么既然都没有可以监控的服务,那么Keepalived有什么独立使用的必要呢?
下图是曾经在博文中展现过的Nginx + Keepalived的工作结构和LVS + Keepalived 的工作结构:

Nginx + Keepalived的工作方式
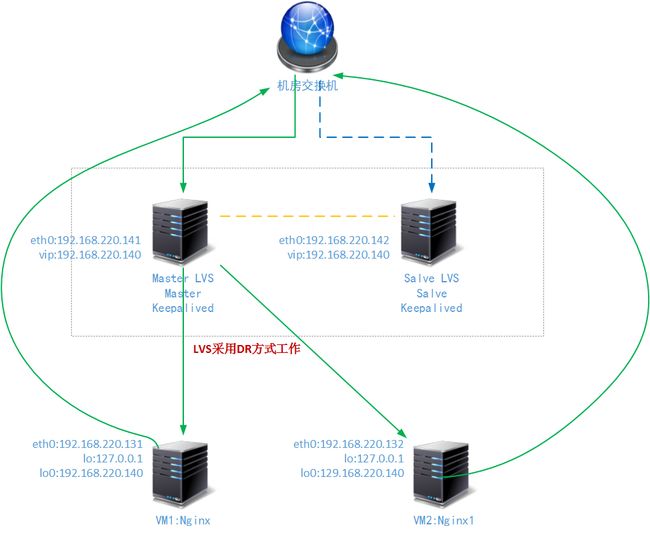
LVS + Keepalived + Nginx的工作方式
- 相关技术还有:
Heartbeat是Linux-HA计划中的一个重要项目,它的功能比Keepalived更强大,安装和管理也相对复杂。网络上有很多资料介绍Heartbeat和Keepalived的优缺点和使用对比。但就我自己的使用经验来说,个人更喜欢使用Keepalived,原因很简单:Keepalived安装和配置更简单,而且够用。另外Redhat Rhcs套件也可以搭建类似的HA集群,但是说实话本人没有尝试过。
3-5、DNS轮询和智能DNS
//TODO DNS技术还没有介绍
3-6、硬件负载
在这个系列的“负载均衡层设计方案”博文中,我们所提到的诸如Nginx、LVS等技术,没有详细讲述的Haproxy、Squid等技术,都是基于软件的负载技术。F5是一家公司,它的BIG-IP LTM技术是基于硬件负载的。硬件负载方案提供了软件负载技术无法提供了性能空间,并且集成了NAT映射功能、SSL加速、Cookie加密、高速缓存、攻击过滤、包过滤、动态Session保持等等很多软件负载无法提供的功能(或者需要多个软件组合使用才能提供的功能)。
但是硬件负载方案也有其缺点,主要就是建设费用比较高昂,它不像软负载可以根据系统的吞吐量的持续增加进行持续扩展。当然您可以根据系统的吞吐量需求,在前期采用软负载,后期采用硬件负载的方案。除了F5公司提供的硬件负载技术,还有Citrix公司的硬负载方案、A10公司的硬件负载方案。
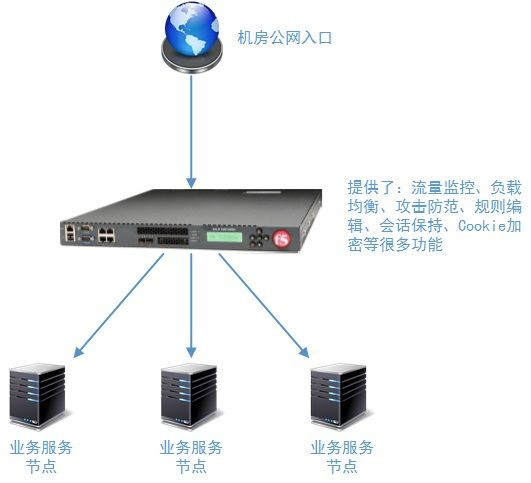
4、常见负载均衡技术组合
这里我们在重新回顾一下这个系列博文中,提到的目前常用的负载均衡技术的组合方式。
4-1、独立的Nginx/Haproxy
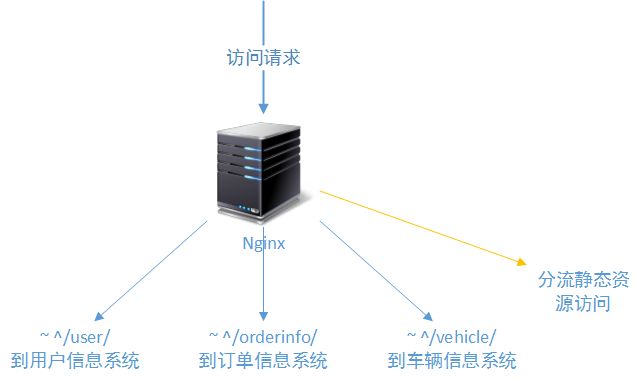
一般的WEB系统,前段假设一个Nginx或者Haproxy服务器,基本上可以解决包括负载分发在内的很多问题了。
4-2、Nginx + Keepalived 或 Haproxy + Keepalived 或 + Heartbeat

为了保证Nginx或者HaProxy服务器的稳定性,可以使用Keepalived或者Heartbeat做一个简单的热备方案。
4-3、LVS + (Keepalived | Heartbeat) + (Nginx | Haproxy)

随着访问压力的增大,我们开始采用多层负载方案,在Nginx或者Haproxy的前段架设LVS服务,并通过Keepalived或者Heartbeat保证Keepalived的持续工作。
4-4、加如DNS轮询技术或者智能DNS路由技术

技术方案扩展到这一步,日千万级PV是完全可以支撑了。前提条件是:程序没有问题^_^。
如果您站点的流量还要大甚至高出几个数量级,那么恭喜您,您肯定是全球排名前100位互联网公司工作;但是从另一个角度来说,您遇到的问题可能只能根据贵公司的业务特点,自己寻求解决方案了。这样的例子有很多,例如YouTube发现市面上的商用CDN网络无法满足他们对视频加速的需求,于是YouTube的工程师们自己动手写了一专门针对自己业务的CDN加速技术;再例如,淘宝发现市面上已经没有一款分布式文件系统能够满足他们对小文件存储的需求,于是动手写了一个TFS。
5、负载均衡技术的其他运用
在这个系列的文章中,我们全在将用于客户端使用HTTP协议请求服务器端进行处理的情况,这里的客户端可以使最终用户,也可以是某个一第三方系统。但实际上负载均衡技术在信息处理领域内,不是只有这样的请求响应层才使用,在其它的技术领域也大量使用,这个小节,我们就来梳理这些技术,作为一个扩展话题。
5-1、关系型数据库系统的负载均衡
一说到关系型数据库,大家自然会联想到Oracle、MS SQL、DB2 和Mysql。在移动互联网领域,通常很多公司在走去OEI的路程。这里我们不去讨论去OEI是否是正确的,也不去讨论怎样走去OEI这条路才合理,一个不可争辩的事实是,目前很多移动互联网公司在使用Mysql数据库。
单台Mysql数据库的处理能力确实赶不上Oracle,甚至赶不上MS SQL这些商用数据库,但是我们可以为Mysql做集群来提高整个数据服务的性能。Mysql从5.1.X版本开始,就已经支持单数据节点的“表分区”功能了,但这个支持仅限于每个节点的配置,提高单个Mysql上的读写性能(还要配合底层的块存储选型,例如DAS)。而想要实现整个Mysql集群性能,就需要从更高级别实现读写分离了。
其中有一种成熟的Mysql集群读写分离的做法,是一台写节点做成Master节点(Master节点单机性能可以做得较高,后端可以使用DAS系统);然后多台读节点做成Salve节点,并接受来源于Master节点的同步日志(MySQL Replication技术),并通过另一个LVS进行读请求的负载,而且可以再配合单个节点上的“表分区”功能。这个做法在80%以上都是读请求的任何系统上,都可以大大增强数据库系统的整体性能,如下图所示:
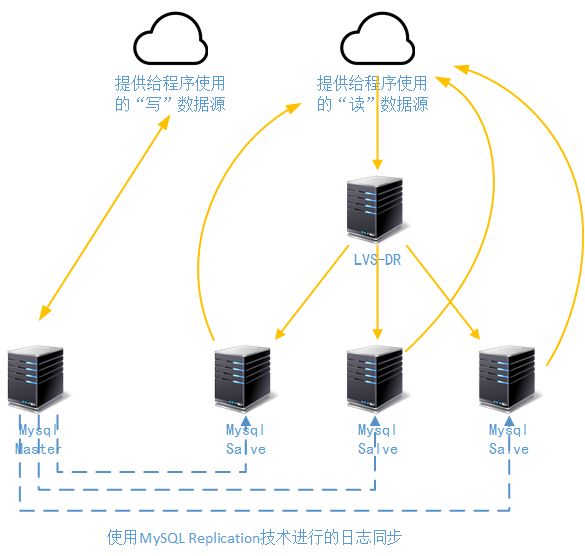
从上图可以看到,来源于程序的“写”操作通过一个数据源提交给了Mysql Master,而所有的读操作则通过LVS-DR模式分发给3个Mysql Salve。这里要说明几个问题:
Mysql Master和Mysql Salve的数据同步是通过MySQL Replication同步技术来实现的,这是一种基于操作日志的异步同步,虽然响应时间不能达到“毫秒”级,但是基本上还是很快很快的。如果不是银行系统、或者“秒杀系统”基本上可以满足事实性
MySQL Replication会降低Mysql Master节点的20%的工作性能,但是转移了原来Mysql Master负责的所有读操作。当然,我们以后介绍“多主”方式和使用HiveDB横向切分的时候,还会重点介绍如何提高Mysql的写性能。
事实上正式的开发架构中,我们不会给程序员两个数据源,这样既不利于代码的管理,也增加了开发难度。我们会采用类似Mysql-Proxy、Amoeba之类的软件实现数据源的整个。
后面在介绍数据存储层架构的时候,我还会介绍多种成熟的可靠的Mysql集群、Mysql读写分离、Mysql横向扩展方式,和读者讨论如何实现几十台Mysql节点的运行和管理。
5-2、分布式存储系统的负载均衡
分布式存储系统目前有很多,Ceph、Swift、MFS、HDFS。他们有的是基于对象存储的,有的是基于快存储的(在《标准Web系统的架构分层》这篇博文中,我对块存储、文件存储和对象存储做了较详细的介绍,后文我们还将详细介绍存储系统)。但是他们有一个或者多个主控节点(有的叫namenode、有的叫master、有的叫Metadata),无论怎么叫,他们都有一些相同的功能:
- 计算“数据该存储在哪里”的问题
- 协调控制“数据是否正确存储”的问题
- 监控“数据节点”的健康状态
- 转移数据
- 回答客户端“到哪里取数据”的问题
- 。。。。。
在处理问题的过程中,这些控制节点实际上起到的就是负载分发的作用,他们的基本原理都是通过“一致性hash算法”,对“数据该存储在”哪里的问题进行分析(用来做hash的属性依据不同而已):
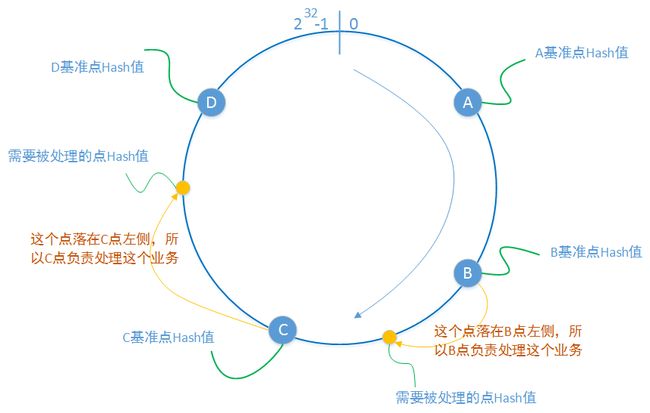
5-3、更广义的负载均衡系统
相同的客流量下,银行多个窗口排队的等待时间肯定比一个窗口排队的时间短;同样的车流量,8车道肯定比6车道的通过率高;把一个任务拆分成多个任务由多个人负责处理其中的一部分,肯定比一个人做一个大任务的时间短;
负载均衡的核心思想在于分流、关键问题在于如何分流、评价标准在于分流后的吞吐量。
6、后文介绍
终于,负载均衡层设计方案算是告一段落了。在这个过程中有很多网友给我提了建议,帮助我进行讲解改进和知识点梳理,在此感谢了。我知道在这几天文章我,我留了很多扣子,无奈本人写作时间有限,能力也不高,所以待到后面的空余时间,我们再进行相关话题的整理。
从下篇文章开始,我们将开始介绍“业务系统间通信”的相关技术、原理和方案,当然也会形成一个系列博文。欢迎各位继续关注我的博客。
明天就是70周年胜利日了,祝我大中华!