Lucene 实例教程(二)之IKAnalyzer中文分词器
作者: 永恒の_☆ 地址: http://blog.csdn.net/chenghui0317/article/details/10281311
一、前言
前面简单介绍了Lucene,以及如何使用Lucene将索引 写入内存,地址:http://blog.csdn.net/chenghui0317/article/details/10052103
但是其中出现很多问题,具体如下:
1、使用IndexWriter 写入的索引全部是放在内存中的,一旦程序挂了 也就什么都没有了,并且如果生成的索引很大,那么很容易导致内存溢出。
2、使用SimpleAnalyzer作为分词器,根据关键字查询的时候 只会匹配根据空格分隔的字符、字母或者数字,并且插入的索引统一变为小写,但是查询的时候没有变为小写,所以检索关键字中出现大写字母 就永远都查不出结果;
3、之后使用StandardAnalyzer作为分词器,因为它是标准来分中文的,所以也只会对中文有分词的效果。尽管这样,仍然不能满足实际开发需求。
在一个真实的项目中如果出现这样的情况,非得为每一个索引的词组中前后添加空格来满足查询,并且所有的关键字必须小写,显然用户体验是非常差的,根本不能满足实际开发需求,这样子的话 还不如不用Lucene 直接去模糊查询数据表记录好了。
接下来介绍一个新的分词器:IKAnalyzer。
二、IKAnalyzer的介绍
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词语言包,它是以Lucene为应用主体,结合词典分词和文法分析算法的中文词组组件。 从3.0版本开始,IK发展为面向java的公用分词组件,独立Lucene项目,同时提供了对Lucene的默认优化实现。 IKAnalyzer实现了简单的分词歧义排除算法,标志着IK分词器从单独的词典分词想模拟语义化分词衍生。
IKAnalyzer 的新特性:
1、.采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和智能分词两种切分模式;
2、在系统环境:Core2 i7 3.4G双核,4G内存,window 7 64位, Sun JDK 1.6_29 64位 普通pc环境测试,IK2012具有160万字/秒(3000KB/S)的高速处理能力。
3、2012版本的智能分词模式支持简单的分词排歧义处理和数量词合并输出。
4、采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符
5、优化的词典存储,更小的内存占用。支持用户词典扩展定义。特别的,在2012版本,词典支持中文,英文,数字混合词语。
三、IKAnalyzer的准备条件
IKAnalyzer3.2.5table.jar
下载地址:http://download.csdn.net/detail/ch656409110/5971413
四、使用Lucene实战
1、使用Lucene将索引 写入磁盘,IKAnalyzer作为分词器检索索引文件
实现的思路如下:
<1> 原先使用的是内存目录对象RAMDirectory 对象,Lucene同时还提供了磁盘目录对象SimpleFSDirectory对象,至于索引写入器IndexWriter 还是和以前一样 ;
<2>利用索引写入器将指定的数据存入磁盘目录对象中;
<3>创建IndexSearch 索引查询对象,然后根据关键字封装Query查询对象;
<4>调用search()方法,将查询的结果返回给TopDocs ,迭代里面所有的Document对象,显示查询结果; <5>关闭IndexWriter ,关闭directory目录对象。
具体代码如下:
package com.lucene.test;
import java.io.File;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
import com.lucene.entity.Article;
public class SimpleFSDirectoryDemo {
/* 创建简单中文分析器 创建索引使用的分词器必须和查询时候使用的分词器一样,否则查询不到想要的结果 */
private Analyzer analyzer = new IKAnalyzer(true);
// 索引保存目录
private File indexFile = new File("./indexDir/");
/**
* 创建索引文件到磁盘中永久保存
*/
public void createIndexFile() {
long startTime = System.currentTimeMillis();
System.out.println("*****************创建索引开始**********************");
Directory directory = null;
IndexWriter indexWriter = null;
try {
// 创建哪个版本的IndexWriterConfig,根据参数可知lucene是向下兼容的,选择对应的版本就好
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_36, analyzer);
// 创建磁盘目录对象
directory = new SimpleFSDirectory(indexFile);
indexWriter = new IndexWriter(directory, indexWriterConfig);
// indexWriter = new IndexWriter(directory, analyzer, true,IndexWriter.MaxFieldLength.UNLIMITED);
// 这上面是使用内存保存索引的创建索引写入对象的例子,和这里的实现方式不一样,但是效果是一样的
Article article0 = new Article(1, "Simple Analyzer","这个分词是一段一段话进行分 ");
Article article1 = new Article(2, "Standard Analyzer","标准分词拿来分中文和ChineseAnalyzer一样的效果");
Article article2 = new Article(3, "PerField AnalyzerWrapper","这个很有意思,可以封装很多分词方式,还可以于先设置field用那个分词分!牛 ");
Article article3 = new Article(4, "CJK Analyzer","这个分词方式是正向退一分词(二分法分词),同一个字会和它的左边和右边组合成一个次,每个人出现两次,除了首字和末字 ");
Article article4 = new Article(5, "Chinese Analyzer","这个是专业的中文分词器,一个一个字分 ");
Article article5 = new Article(6, " BrazilianAnalyzer", "巴西语言分词 ");
Article article6 = new Article(7, " CzechAnalyzer", "捷克语言分词 ");
Article article7 = new Article(8, "DutchAnalyzer", "荷兰语言分词 ");
Article article8 = new Article(9, "FrenchAnalyzer", "法国语言分词 ");
Article article9 = new Article(10, "沪K123", "这是一个车牌号,包含中文,字母,数字");
Article article10 = new Article(11, "沪K345", "上海~!@~!@");
Article article11 = new Article(12, "沪B678", "京津沪");
Article article12 = new Article(13, "沪A3424", "沪K345 沪K3 沪K123 沪K111111111 沪ABC");
Article article13 = new Article(14, "沪 B2222", "");
Article article14 = new Article(15, "沪K3454653", "沪K345");
Article article15 = new Article(16, "123 123 1 2 23 3", "沪K123");
List<Article> articleList = new ArrayList<Article>();
articleList.add(article0);
articleList.add(article1);
articleList.add(article2);
articleList.add(article3);
articleList.add(article4);
articleList.add(article5);
articleList.add(article6);
articleList.add(article7);
articleList.add(article8);
articleList.add(article9);
articleList.add(article10);
articleList.add(article11);
articleList.add(article12);
articleList.add(article13);
articleList.add(article14);
articleList.add(article15);
// 为了避免重复插入数据,每次测试前 先删除之前的索引
indexWriter.deleteAll();
// 获取实体对象
for (int i = 0; i < articleList.size(); i++) {
Article article = articleList.get(i);
// indexWriter添加索引
Document doc = new Document();
doc.add(new Field("id", article.getId().toString(),Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.add(new Field("title", article.getTitle().toString(),Field.Store.YES, Field.Index.ANALYZED));
doc.add(new Field("content", article.getContent().toString(),Field.Store.YES, Field.Index.ANALYZED));
// 添加到索引中去
indexWriter.addDocument(doc);
System.out.println("索引添加成功:第" + (i + 1) + "次!!");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (indexWriter != null) {
try {
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (directory != null) {
try {
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
long endTime = System.currentTimeMillis();
System.out.println("创建索引文件成功,总共花费" + (endTime - startTime) + "毫秒。");
System.out.println("*****************创建索引结束**********************");
}
/**
* 直接读取索引文件,查询索引记录
*
* @throws IOException
*/
public void openIndexFile() {
long startTime = System.currentTimeMillis();
System.out.println("*****************读取索引开始**********************");
List<Article> articles = new ArrayList<Article>();
// 得到索引的目录
Directory directory = null;
IndexReader indexReader = null;
try {
directory = new SimpleFSDirectory(indexFile);
// 根据目录打开一个indexReader
indexReader = IndexReader.open(directory);
//indexReader = IndexReader.open(directory,false);
System.out.println("在索引文件中总共插入了" + indexReader.maxDoc() + "条记录。");
// 获取第一个插入的document对象
Document minDoc = indexReader.document(0);
// 获取最后一个插入的document对象
Document maxDoc = indexReader.document(indexReader.maxDoc() - 1);
// document对象的get(字段名称)方法获取字段的值
System.out.println("第一个插入的document对象的标题是:" + minDoc.get("title"));
System.out.println("最后一个插入的document对象的标题是:" + maxDoc.get("title"));
//indexReader.deleteDocument(0);
int docLength = indexReader.maxDoc();
for (int i = 0; i < docLength; i++) {
Document doc = indexReader.document(i);
Article article = new Article();
if (doc.get("id") == null) {
System.out.println("id为空");
} else {
article.setId(Integer.parseInt(doc.get("id")));
article.setTitle(doc.get("title"));
article.setContent(doc.get("content"));
articles.add(article);
}
}
System.out.println("显示所有插入的索引记录:");
for (Article article : articles) {
System.out.println(article);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (indexReader != null) {
try {
indexReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (directory != null) {
try {
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
long endTime = System.currentTimeMillis();
System.out.println("直接读取索引文件成功,总共花费" + (endTime - startTime) + "毫秒。");
System.out.println("*****************读取索引结束**********************");
}
/**
* 查看IKAnalyzer 分词器是如何将一个完整的词组进行分词的
*
* @param text
* @param isMaxWordLength
*/
public void splitWord(String text, boolean isMaxWordLength) {
try {
// 创建分词对象
Analyzer analyzer = new IKAnalyzer(isMaxWordLength);
StringReader reader = new StringReader(text);
// 分词
TokenStream ts = analyzer.tokenStream("", reader);
CharTermAttribute term = ts.getAttribute(CharTermAttribute.class);
// 遍历分词数据
System.out.print("IKAnalyzer把关键字拆分的结果是:");
while (ts.incrementToken()) {
System.out.print("【" + term.toString() + "】");
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println();
}
/**
* 根据关键字实现全文检索
*/
public void searchIndexFile(String keyword) {
long startTime = System.currentTimeMillis();
System.out.println("*****************查询索引开始**********************");
IndexReader indexReader = null;
IndexSearcher indexSearcher = null;
List<Article> articleList = new ArrayList<Article>();
try {
indexReader = IndexReader.open(FSDirectory.open(indexFile));
// 创建一个排序对象,其中SortField构造方法中,第一个是排序的字段,第二个是指定字段的类型,第三个是是否升序排列,true:升序,false:降序。
Sort sort = new Sort(new SortField[] {new SortField("title", SortField.STRING, false),new SortField("content", SortField.STRING, false) });
//Sort sort = new Sort();
// 创建搜索类
indexSearcher = new IndexSearcher(indexReader);
// 下面是创建QueryParser 查询解析器
// QueryParser支持单个字段的查询,但是MultiFieldQueryParser可以支持多个字段查询,建议用后者这样可以实现全文检索的功能。
// QueryParser queryParser = new QueryParser(Version.LUCENE_36, "title", analyzer);
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_36, new String[] { "title", "content" },analyzer);
// 利用queryParser解析传递过来的检索关键字,完成Query对象的封装
Query query = queryParser.parse(keyword);
splitWord(keyword, true); // 显示拆分结果
// 执行检索操作
TopDocs topDocs = indexSearcher.search(query, 5, sort);
System.out.println("一共查到:" + topDocs.totalHits + "记录");
ScoreDoc[] scoreDoc = topDocs.scoreDocs;
// 像百度,谷歌检索出来的关键字如果有,除了显示在列表中之外还会高亮显示。Lucenen也支持高亮功能,正常应该是<font color='red'></font>这里用【】替代,使效果更加明显
SimpleHTMLFormatter simpleHtmlFormatter = new SimpleHTMLFormatter("【", "】");
// 具体怎么实现的不用管,直接拿来用就好了。
Highlighter highlighter = new Highlighter(simpleHtmlFormatter,new QueryScorer(query));
for (int i = 0; i < scoreDoc.length; i++) {
// 内部编号 ,和数据库表中的唯一标识列一样
int doc = scoreDoc[i].doc;
// 根据文档id找到文档
Document mydoc = indexSearcher.doc(doc);
String id = mydoc.get("id");
String title = mydoc.get("title");
String content = mydoc.get("content");
TokenStream tokenStream = null;
if (title != null && !title.equals("")) {
tokenStream = analyzer.tokenStream("title",new StringReader(title));
title = highlighter.getBestFragment(tokenStream, title);
}
if (content != null && !content.equals("")) {
tokenStream = analyzer.tokenStream("content",new StringReader(content));
// 传递的长度表示检索之后匹配长度,这个会导致返回的内容不全
//highlighter.setTextFragmenter(new SimpleFragmenter(content.length()));
content = highlighter.getBestFragment(tokenStream, content);
}
// 需要注意的是 如果使用了高亮显示的操作,查询的字段中没有需要高亮显示的内容 highlighter会返回一个null回来。
articleList.add(new Article(Integer.valueOf(id),title == null ? mydoc.get("title") : title,content == null ? mydoc.get("content") : content));
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (InvalidTokenOffsetsException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
} finally {
if (indexSearcher != null) {
try {
indexSearcher.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
if (indexReader != null) {
try {
indexReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
System.out.println("根据关键字" + keyword + "检索到的结果如下:");
for (Article article : articleList) {
System.out.println(article);
}
long endTime = System.currentTimeMillis();
System.out.println("全文索引文件成功,总共花费" + (endTime - startTime) + "毫秒。");
System.out.println("*****************查询索引结束**********************");
}
public static void main(String[] args) {
SimpleFSDirectoryDemo luceneInstance = new SimpleFSDirectoryDemo();
// 建立要索引的文件
luceneInstance.createIndexFile();
// 从索引文件中查询数据
// luceneInstance.openIndexFile();
// 查看IKAnalyzer分词结果
/*
* String[] keywords = new
* String[]{"IKAnalyzer是一个基于java语言开发的轻量级的中文分词工具包"
* ,"我正在学习Lucene3.6,看一下效果如何"
* ,"鄂尔多斯"," Java做服务器端时如何接收和处理android客户端base64编码过的图片呢?"};
* luceneInstance.splitWord(keywords[0], true);
* luceneInstance.splitWord(keywords[0], false);
* luceneInstance.splitWord(keywords[1], true);
* luceneInstance.splitWord(keywords[1], false);
* luceneInstance.splitWord(keywords[2], true);
* luceneInstance.splitWord(keywords[2], false);
* luceneInstance.splitWord(keywords[3], true);
* luceneInstance.splitWord(keywords[3], false);
*/
// 获得结果,然后交由相关应用程序处理
String[] searchKeywords = new String[]{"analyzer","沪B123","沪K123","沪K123 上海","沪K3454653"};
luceneInstance.searchIndexFile(searchKeywords[1]);
}
}
上面代码关联的实体类代码如下:
package com.lucene.entity;
public class Article {
private Integer id;
private String title;
private String content;
public Article() {
super();
}
public Article(Integer id, String title, String content) {
super();
this.id = id;
this.title = title;
this.content = content;
}
public synchronized Integer getId() {
return id;
}
public synchronized void setId(Integer id) {
this.id = id;
}
public synchronized String getTitle() {
return title;
}
public synchronized void setTitle(String title) {
this.title = title;
}
public synchronized String getContent() {
return content;
}
public synchronized void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "Article [id=" + id + ", title=" + title + ", content=" + content + "]";
}
}
代码有点长,其中包括了如何将索引写入磁盘,以及IKAnalyzer 分词是如何将检索关键字进行分词的,然后如何实现全文检索操作的。
首先看看createIndexFile()这个方法,该方法用于创建索引,将索引写入磁盘,执行该方法的效果如下:
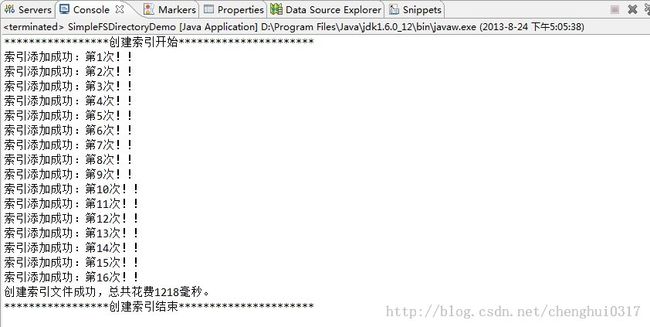
根据提示索引添加成功,然后去当前项目下的indexDir目录中查看索引文件,具体截图如下:

截图中展示全是非文本文件,所以看不到具体存储的什么,但是Lucene知道,我们只需要知道如何利用它去完成自己想要的功能即可。
需要注意的是:
1、如果添加一次索引,那么该目录的大多文件都会发生改变,如果添加索引的时候发现文件的修改时间没有改变 肯定没有添加成功;
2、如果在创建索引的时候使用的是IKAnalyzer分词器,那么查询的索引的时候同样也要使用IkAnalyzer分词器,否则查询不到结果。
然后,索引创建成功之后,接下来看看openIndexFile()这个方法,它使用的是IndexWriter直接读取索引文件,查询索引记录。
执行该方法的具体效果如下:

从截图中看出,Lucene添加的索引全是按照索引下标一个一个按照添加顺序添加进去的, 直接根据这个下标就可以返回对应的Document对象。 另外操作IndexReader 获取的Document对象 还蛮简单的,跟Arraylist有点相似,只不过方法名称不一样。
为了验证 是否和Arraylist一样,删除其中的索引之后,后面的下标是否会向前移动。修改代码:
indexReader 的是否只读属性改为false,默认是true,如果不改为false 删除索引会报错:
Exception in thread "main" java.lang.UnsupportedOperationException: This IndexReader cannot make any changes to the index (it was opened with readOnly = true)
具体修改如下: indexReader = IndexReader.open(directory,false);
然后添加 删除索引的代码:indexReader.deleteDocument(0);
实践发现,该方法没有真正删除索引, 我在重新调用openIndexFile()方法一样返回所有的记录, 但是indexDir目录中确实有索引文件被修改的痕迹, 并且如果使用IndexSearch调用search()方法确检索不到,可见indexReader.deleteDocument(0);没有真正删除索引,只不过在使用IndexSearch检索的时候检索不到罢了。
后来发现:使用IndexReader进行Document删除操作时,文档并不会立即被删除,而是把这个删除动作缓存起来,直到调用IndexReader.Close()时,删除操作才会被真正执行。
然后再看下IKAnalyzer分词器到底有什么效果,为什么这么多特性,它是如何实现分词效果的,运行splitWord()方法,具体效果如下:

由截图可见:
1、IKAnalyzer分词器在分词的时候会把传递过来的字母统一转换成小写,这样子非常有效的避免的添加索引的时候全部小写 而导致大小写不一样检索不到的情况;
2、IKAnalyzer拆分关键字分两种,分别是“最细粒度切分算法”和“智能切分算法”,分别对应的值是false 和 true ,所以如果不想切分的太细小化就传递true,默认值是false;
源代码:
public IKAnalyzer(boolean isMaxWordLength)
{
this.isMaxWordLength = false;
setMaxWordLength(isMaxWordLength);
}
多尝试几次就知道它的具体好处了。
现在对IKAnalyzer分词已经有所了解了,接下来看看searchIndexFile() 如何实现全文检索的。
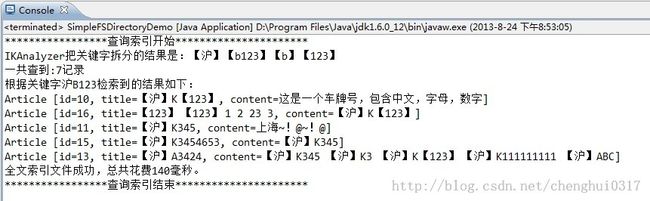
传递关键字“沪B123”,执行一下searchIndexFile()方法,具体效果如下图所示:

从截图中看到 共有7条记录,但是只显示了5条,是因为传递的nDocs参数限制了返回的结果数。
但是显示的 content内容只有高亮的部分,其他全部被截去了。
如果把highlighter.setTextFragmenter(new SimpleFragmenter(content.length())); 这行代码注释掉就ok了,具体效果如下:
现在可以看到完整的内容了,但是明明第二条的信息匹配度要高于第一条,却放在了第二行显示,这是因为 传递的sort对象 先按title排序,然后再按内容排序,要达到最有匹配的效果,索性传递一个空的sort 即可,具体效果如下:
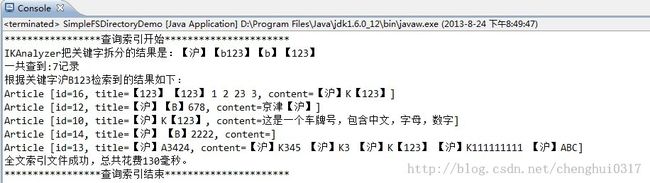
图中最后一条记录中出现的“沪”共有6次,"123"也出现了1次,却被排在了最后一行,费解。。。可以看做是当中一个bug, 具体原因还需要慢慢咀嚼。也许是IKAnalyzer中不完善导致的。
另外如果传递的参数是“analyzer”,具体效果如下:
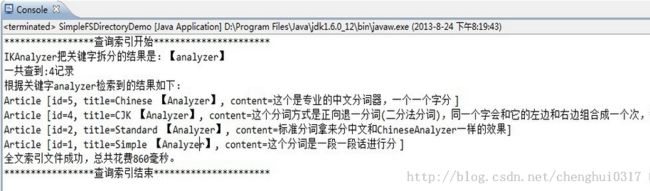
在截图中与插入的数据作对比,发现如果录入索引的内容中的字母以“analyzer”单独为一个词组才可以查询到,就是“analyzer”这个单词的前后有空格,否则查询不到, 但是如果和中文与数字挨在一起却没问题,在上一个例子中可以看到效果。
另外需要说明的是:
如果使用的是SimpleAnalyzer或者StandardAnalyzer作为分词器的话,检索的关键字如果有特殊字符 比如:" \ } 等等,会报错,具体如下:
org.apache.lucene.queryParser.ParseException: Cannot parse '沪B123)': Encountered " ")" ") "" at line 1, column 5.
但是使用IKAnalyzer没有问题,因为它会直接把这些字符过滤掉,不作为检索的条件。
反复多尝试几次,得出如下结论:
<1> 如果录入的索引为字母必须和中文或者数字挨在一起,后者空格隔开分为一个词组 才能查询到,否则IKAnalyzer 会认为是一个整体,不会分词。简而言之,字母与字母挨在一起 会被当做一个完整的词组,数字和数字挨在一起也会被当做一个完整的词组,只有完全匹配才会被检索出来;
<2>如果在检索的时候发现排序不会,最有匹配的并没有放在最上面,这是由于sort排序导致的,它会根据字段的先后顺序和指定的是否升序 来重新排序,多多少少会对实际的效果产生影响。
所以 使用IKAnalyzer 这个中文分词器之后 较以前的检索能力大大的提高了,最优匹配度也比之前好多了,从而提高了用户的体验度。。