little endian 和big endian问题全面解读
在little endian电脑上
#include<stdio.h>
int main()
{
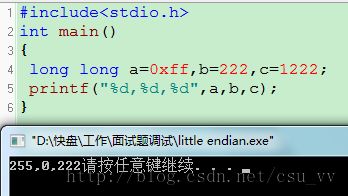
long long a=1,b=2,c=3;
printf("%d,%d,%d",a,b,c);
}
我的电脑输出是 1,0,2
long 4个字节,long long 8个字节
由于x86电脑是little endian,所以是按照从低到高的顺寻存储地址
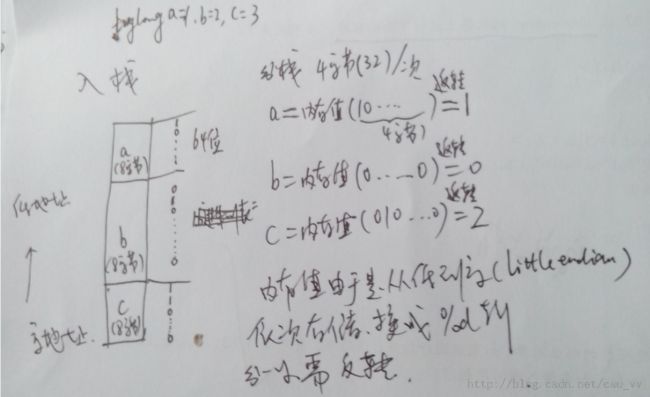
a=0x01 存储的为10..... 8字节32位
b=0x10 存储的为01......
c=0x11 存储的为11.....
而a,b,c八个字节,压栈c,b,a然后4个字节4个字节这样取出,又是小端模式,所以低位存低位,高位存高位
因而依次1,0,2出栈.
纸质分析图:
三个数时的一个规律:
第三个数一直都等于之前的第二个数;
第一个数一直等于本身。
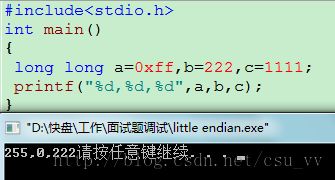


printf()是格式化输出函数,对应格式输出,不然结果不可预知
含义的解释:
其实big endian是指低地址存放最高有效字节(MSB),而little endian则是低地址存放最低有效字节(LSB)。
字节排序 含义
Big-Endian 一个Word中的高位的Byte放在内存中这个Word区域的低地址处。
Little-Endian 一个Word中的低位的Byte放在内存中这个Word区域的低地址处。
必须注意的是:表中一个Word的长度是16位,一个Byte的长度是8位。
如果一个数超过一个Word的长度,必须先按Word分成若干部分,然后每一部分(即每个Word内部)按Big-Endian或者Little-Endian的不同操作来处理字节。
比如数字0x12345678在两种不同字节序CPU中的存储顺序如下所示:
Big Endian
低地址 高地址
----------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 12 | 34 | 56 | 78 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Little Endian
低地址 高地址
----------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 78 | 56 | 34 | 12 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
32机器上各种变量类型的长度
在32 位的系统上
short 的内存大小是2 个byte(字节);
int 内存大小是4 个byte;
long 内存大小是4 个byte;
long long 内存大小是8 个byte;
float 内存大小是4 个byte;
double 内存大小是8 个byte;
char 内存大小是1 个byte。