LINUX邻居子系统(一)
邻居子系统是linux网络协议栈中非常庞大的一块,也是比较混乱复杂的一块,不过有一点感觉挺好玩的就是
它不涉及太多具体协议的内容,所以阅读起来还不算太复杂
而且它很多时候自成一个小小的系统运转(所以才叫子系统),不需要外界太多的管理(ARP,ND等协议的管理),这也是它的一个特色。
不过感觉它也承担了一部分第二层的功能(二层协议首部的封装)
它嵌入在网络层和数据链路层之间(但是又不能把它叫做LLC--逻辑链路控制),可以对上和对下提供一个统一的接口,让两层间的通信变的透明。当然这里面有很大一部分原因得归功于地址解析协议(ARP)
注:这个ARP和ARP协议不是一个东西,所有的能够将L3地址(一般都是逻辑地址)到L2地址(一般选物理地址为数据链路层的地址)的转换的都称作地址解析协议。
弄懂它有助于理解协议栈整体过程。
说明:主要的参考资料来源---
(1)《Understand Linux Kernel Internel》
(2)《Linux内核源码剖析-TCP/IP实现》
(3)linux内核源码--我使用的版本是3.2.4
注:还是建议去买个正版书,一个是好做笔记,另外一个感觉别人写书不容易
开篇点题,什么是邻居子系统?------可以略过不看,感觉说的不是太好
答:这个在《Understand Linux Kernel Internel》中花费了许多笔墨介绍,还举了很多例子给与说明(见第26章)。
个人感觉也没那么复杂:大致意思就是L3的是逻辑地址,L2的是物理地址,需要做的就是实现这两个地址的映射。
举个简单的例子:比如我要给寄出一个包裹到国外,对方的地址就是一个逻辑地址,但是我不可能直接就交到对方手上,我需要做的第一件事情就是看以下附近有没有什么邮局,邮局就是我的一个“邻居关系”,而且它是可以帮助我把包裹送到国外的唯一渠道,那我要做的就是查到邮局的地址,然后把这个包裹送到邮局,让它帮忙。做如下等价:
收件人地址=逻辑地址
邮局地址=物理地址
两者同时具备,这个包裹就可以正确送达了。
注:其实这就是ARP协议做的功能
注2:把它做成邻居子系统的原因就是,网络不可能只有IPV4,其他的协议也需要地址解析,如果为每个单独开发,有很多重复劳动,做一个通用结构就可以减少这些劳动了
注3:可能后面东西会比较零散,个人将很多感觉一开始学习不需要的细节(如初始化,删除等)给略过的原因,先掌握全貌,然后再细致的一个个看,这样可能会简单很多
1、纵览:邻居子系统的框架
框架图(见《Understand Linux Kernel Internel》图26-5):
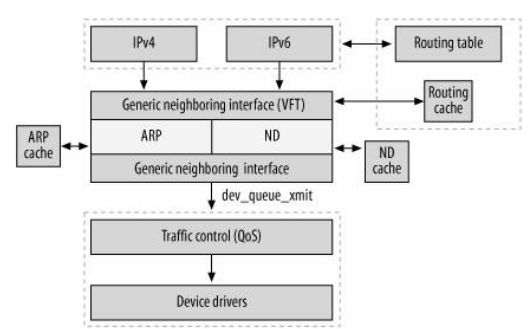
图 1-1 邻居子系统框架图
这个图这么来看:
(1)中间的一块就是邻居子系统
(2)看中间那块最上部,Generic neighbouring interface(VFT),它为上层协议提供了一个统一的输出接口(其实就是neigh->output()),第三层协议在封装好报文后,不需要考虑自身是什么协议类型,直接使用邻居子系统的输出函数,它会自动帮你弄好发送的工作。
(3)看中间那块最下部,Generic neighbouring interface(VFT),它为下层提供的也是一个统一的接口(其实就是dev_queue_xmit()),下层协议只需要处理从dev_queue_xmit()出来的数据就可以了。
(4)看中间那块的中部,可以看到ARP和ND,ARP是为IPV4设计的地址解析协议,而ND(neighbour detect)则是为IPv6设计的。这些地址解析协议可以说是“嵌入”在邻居子系统里面,但是又可以自由灵活的拆卸,非常方便。
还有一点需要注意的,可以看到每个地址解析协议还有各自的缓存(cache),这个是实现的原因,管理方便,搜索迅速。以后会慢慢看到这个缓存的样貌的。
(5)看右方虚线框内,是不是很奇怪?不奇怪就跳过后面内容。这里是这样的,为了加速数据包的发送速度,会将路由表和邻居缓存进行绑定,这个绑定其实就是吧邻居缓存中的每个项的结构体嵌入路由表中的一个路由项中,这样报文在查找到路由以后,其实也相当于已经在邻居子系统中查到了缓存,减少了查找的次数。这样在进入邻居子系统后的处理流程就很短。
注:路由查表工作发生在第四层,TCP协议在建立链接过程中就会把报文需要的路由项保存在套接字结构中了。而udp协议因为不是面向协议,在没有调用connect的情况下会每次都查找路由,这个查找动作发生在udp_sendmsg()尾部
2、先看看数据结构框架(见《Understand Linux Kernel Internel》图27-2):
注:图太大,截图不好弄,结果很模糊,另外如果觉得这个图太复杂可以参考《Linux内核源码剖析-TCP/IP实现》图17-1,那个要清晰很多
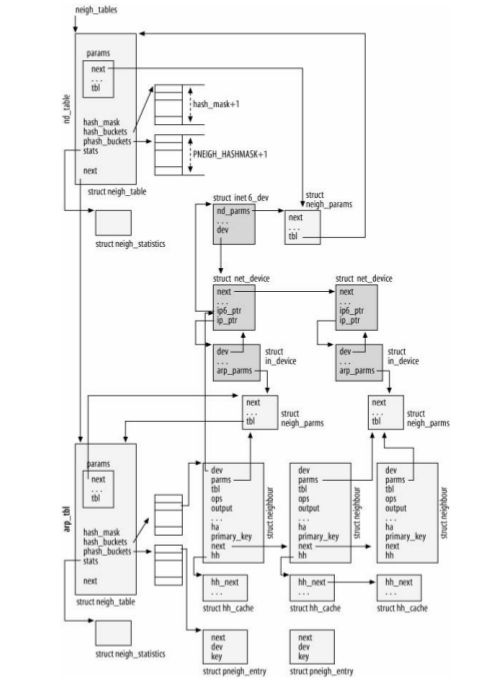
图2 -1邻居子系统,数据框架图
最开始看这张图,感觉这么来看要好一些:
(1)邻居子系统中主要用到的数据结构有
- struct neigh_table
- struct neigh_statistics
- struct neighbour
- struct hhcache
- struct pneigh_entry
- struct neigh_parms
注:中间颜色很深的区域的几个结构可以不去关注,他们和邻居子系统的关系不是太大。
(2)struct neigh_table : 邻居表,每个地址解析协议就会创建这样的一个表,如图中画的,这里有一张nd_table和一张arp_table,分别对应ND协议和ARP协议。!!!这个表中就包含了所有所有的数据成员。
注:所有的邻居表组织成链表的形式方便管理,但是两个表中间其实没有什么关系,他们单独维护一个邻居表而已。
(3)struct neighbour : 邻居项,邻居项代表一个邻居。邻居项用哈希表(散列表)+链表链的组织方式(这种方式在内核中随处可见),最后struct neigh_table的hash_bucket成员就指向这个哈希表的表头。
注:可以看到每个邻居项都会有一个hh字段指向一个struct hh_cache(这个是什么后面介绍),这里需要说明的是图中画的也不准确,因为有多个neighbour指向同一个hh_cache的时候。(貌似说错了)
注2:需要关注以下neighbour中的ops字段,这个字段很重要,后面慢慢讲
(4)struct hh_cache : 这个字段存的就是封装好的二层协议头部。如下图(见《Understand Linux Kernel Internel》图27-1),每个报文在进入邻居子系统前都会查找路由,路由项中就会包含这hh_cache这个结构
注:不是所有的路由项中的hh项指向的数据都是有效的
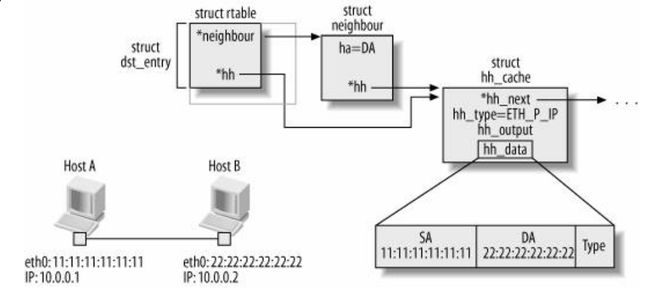
图 2-2 struct hh_cache与struct dst_entry的关系
(5)其他结构暂时不介绍
补:感觉上次写的LL2缓存有些缺陷,现在继续补充一些细节
如下图(见《Understand Linux Kernel Internel》图27-10)
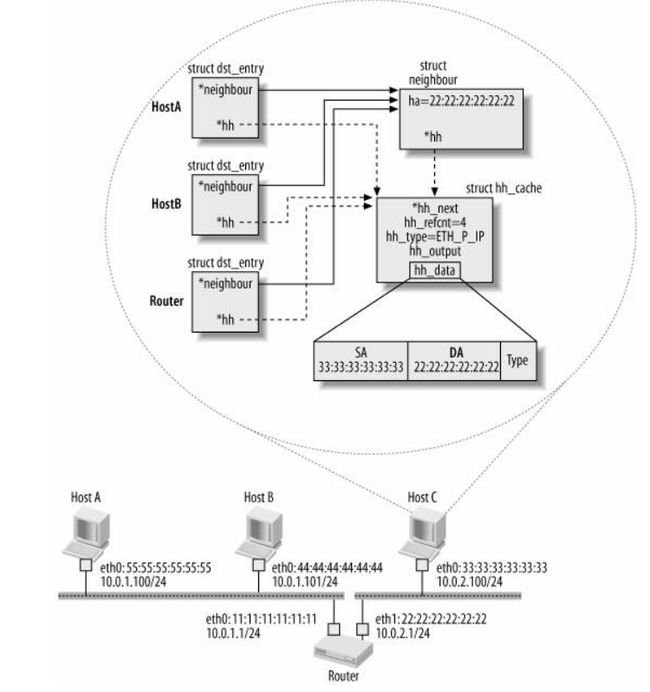
图2-3 struct hh_cache 与struct neighbour关系
其实这个细节也不复杂,意思就是多个路由项可以指向同一个邻居项,同时可以注意的就是hh_cache中的hh_refcnt=4,这个值的大小就是图中虚线箭头的个数
3、现在返回来看在1中提到的(2)(3)--也就是邻居子系统的通用接口
如图(见《Understand Linux Kernel Internel》图27-3)
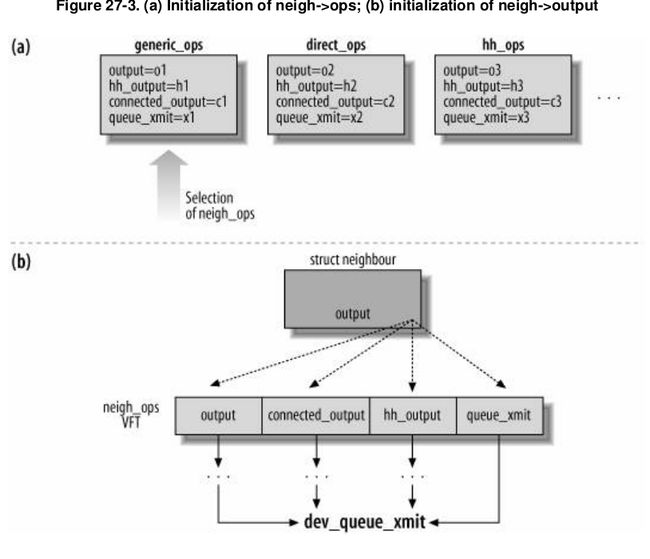
图3-1struct neighbour结构中output函数指针与struct neigh_ops中函数指针的关系
先看图(b)部分
(1)首先之前在1中提到了,对上提供的通用接口就是neigh->output(),如果去翻源码,可以看到它其实是一个函数指针。它会因为当前邻居项所处于的状态(后面会说这个状态机是怎么回事)而改变neigh->output所指向的函数。所以可以看到图中它指向了很多不同的函数。
(2)中间的函数是neigh->ops的成员,但是需要注意的是,这些成员还是函数指针。它们又指向不同的函数(如图(a)所示)。是不是感觉很奇怪,其实这些ops中的函数是根据地址解析协议来确定的。比如ARP,它会准备好几套的ops函数,在初始化的时候根据情况对neigh->ops进行初始化。这样整个系统的灵活性就非常高了(感觉它也是邻居系统精华的部分之一,还有一个就是它的状态机)
注:如果还是看不懂,可以参考《Understand Linux Kernel Internel》章节28.7
(3)然后可以看到最后无论是什么样的output函数,最后出口都是dev_queue_xmt()。
!!注:我看的内核3.2.4中,neigh_ops中的函数指针有变化
struct neigh_ops {
/*定义的一组output操作,会根据状态改变给neigh->output赋值,
* 但是这里的操作还是在初始化的时候根据不同协议进行注册的*/
int family;
void (*solicit)(struct neighbour *, struct sk_buff *); /*发送请求报文函数, */
void (*error_report)(struct neighbour *, struct sk_buff *); /*当邻居项缓存这为发送的报文,即arp_queue
不为空,然而目的项又不可达时
就会调用该函数发送一个主机不可达的ICMP报文*/
int (*output)(struct neighbour *, struct sk_buff *);
int (*connected_output)(struct neighbour *, struct sk_buff *);
};
补:感觉output函数说的不够,结果在后面被卡壳了,现在把一些必要的给补上。
这里补充下,neigh_ops中的函数指针又是指向哪些函数吧。
(1)邻居子系统提供的有
- neigh_connected_output
- neigh_resolve_output
- neigh_compat_output
- neigh_block
这几个函数的说明如下(《Understand Linux Kernel Internel》章节27.2)


然后不同的地址解析协议可以把上面的进行组合,还可以加入自己特有的一部分函数,在初始化的时候赋值给neigh_ops
例如,3.2.4中arp提供的ops的方案有如下几套:
static const struct neigh_ops arp_generic_ops = {
.family = AF_INET,
.solicit = arp_solicit,
.error_report = arp_error_report,
.output = neigh_resolve_output,
.connected_output = neigh_connected_output,
};
static const struct neigh_ops arp_hh_ops = {
.family = AF_INET,
.solicit = arp_solicit,
.error_report = arp_error_report,
.output = neigh_resolve_output,
.connected_output = neigh_resolve_output,
};
static const struct neigh_ops arp_direct_ops = {
.family = AF_INET,
.output = neigh_direct_output,
.connected_output = neigh_direct_output,
};
static const struct neigh_ops arp_broken_ops = {
.family = AF_INET,
.solicit = arp_solicit,
.error_report = arp_error_report,
.output = neigh_compat_output,
.connected_output = neigh_compat_output,
};
注:具体使用哪个需要在初始化的时候会根据相应情况选择,可以参考arp_constructor函数。
4、在3中(2)提到每个邻居项的neigh->output函数指针是根据状态进行改变的,那接下来就看看这个状态是怎么回事
状态转移图(见《Understand Linux Kernel Internel》图26-13)
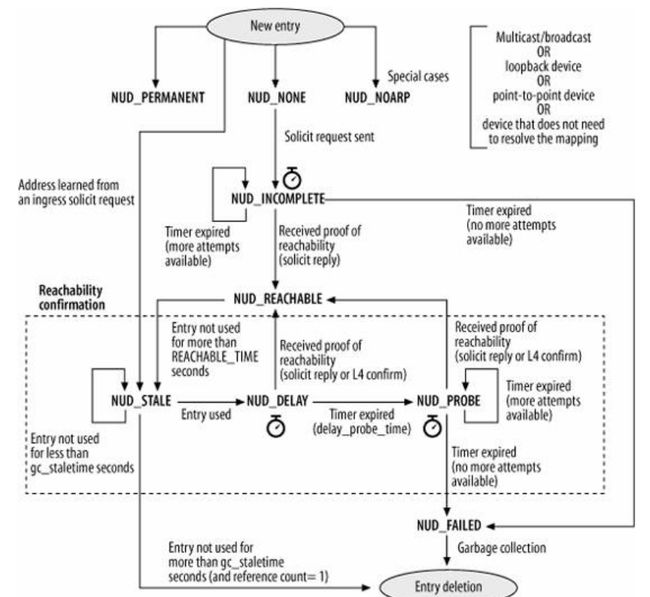
图4-1 邻居子系统状态转移图
(1)每个邻居项都会维持各自的状态机,就是这个状态机的转换在改变neigh->output函数指针指向的函数。
注:如果你是看中文版的,在这个图中有好好几个翻译错误,请比对英文原图看,另外书中在介绍NUD_VALID时第一句话也翻译错了,导致意思完全相反。
注2:状态图中各个状态说明我就不说了,参照见《Understand Linux Kernel Internel》章节26.6,里面说的很清楚。后面是直接的贴图(懒得弄好看了,将就下,不行就去买书吧)







注3:在书中介绍的时候有说到很多派生状态(Derived states),在源代码中很经常看到这几个状态,注意其包含的状态有哪些
注4:注意NUD_STALE、NUD_DEALY, NUD_PROBE三个状态
(2)状态图中有多个定时器,个人感觉没什么好看的,写状态机肯定会涉及到定时器,知道每个定时器的功能就好了。《Understand Linux Kernel Internel》章节27.3.2,和27.6
5、状态切换是通过neigh_update()函数实现的
如图《Understand Linux Kernel Internel》图27-4
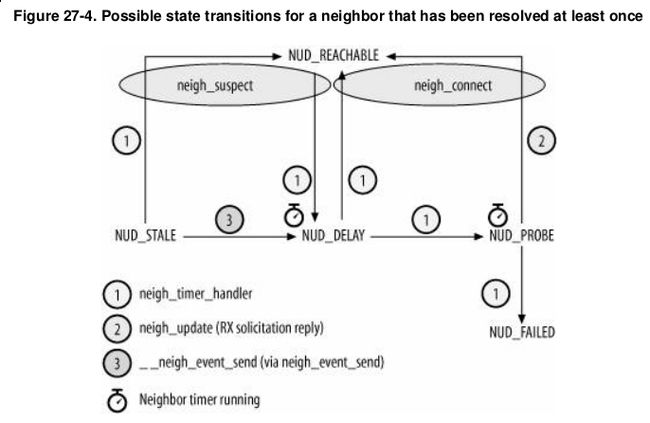
图5-1 状态转移简图
这个图这么来看:
(1)首先图标题,这个是最少被解析过一次的状态机,如果没看懂意思可以参考ARP协议,建议去看看arp_process()函数,看了就明白怎么回事了。
(2)注意neigh_suspect和neigh_connect,这两个其实是两个函数,它们的功能很简单,就是改变neigh->output函数指针指向的函数。
(3)注意圈圈中的1,2,3,我暂时也没弄懂它们是什么。
(4)这里需要特别关注neigh_update函数。需要对着Understand Linux Kernel Internel》图27-5和源码一起看。
好了,今天先写到这,后面内容感觉好多,有种无力写的感觉。。。。。
继续上次的讲
我们现在知道了
(1)邻居子系统的运转是根据状态机来的
(2)每个邻居项有自己的一个状态,存储在neigh->nud_state
(3)更新状态的通用函数是neigh_update()
6、现在让我们来观察下neigh_update()函数。
不过首先先了解下邻居项,也就是struct neighbour
注:如果忘记了neighbour是什么,可以返回前面看2
struct neighbour {
/*存储了邻居的相关信息,包括
* 包括状态,二层和三层协议地址,提供给三层协议的函数指针
* 还有定时器和缓存的二层首部
* 注意:一个邻居不是指一个主机,而是一个三层协议地址*/
struct neighbour __rcu *next;
struct neigh_table *tbl; /*该协议所在的邻居表 */
struct neigh_parms *parms; /*调节邻居协议的参数,在创建邻居项函数neigh_creat()
*中,首先调用neigh_alloc()分配一个邻居项,在该函数中使用邻居表的parms
对该参数进行初始化, 接着neigh_creat()调用邻居表的constructor()对邻居项作特定的设置
时将该参数修改微协议相关设备的参数*/
unsigned long confirmed; /*记录最近一次确认该邻居可达性的时间 */
unsigned long updated; /*最近一次被neigh_update()更新的时间 */
rwlock_t lock;
atomic_t refcnt; /*引用计数 */
struct sk_buff_head arp_queue; /*当邻居项处于无效状态时,用来缓存要发送的报文 */
struct timer_list timer;
unsigned long used; /*最近一次被使用时间
当邻居不处于UND_CONNECTED状态时,该值在neigh_event_send()中更新
当邻居处于UND_CONNECTED状态时,该值会通过gc_timer定时器处理函数更新*/
atomic_t probes;
__u8 flags; /*记录邻居项的一些标志和特性 */
__u8 nud_state; /*邻居状态 */
__u8 type;
__u8 dead; /*生存标志,如果设置为,则意味该项正在被删除,最后会通过垃圾回收器回收 */
seqlock_t ha_lock;
unsigned char ha[ALIGN(MAX_ADDR_LEN, sizeof(unsigned long))];
struct hh_cache hh; /*含有封装二层协议头部时使用的信息,到时候只要复制过去就可以了 */
int (*output)(struct neighbour *, struct sk_buff *); /*出口通用接口,状态不同下函数指针指向函数不同
在刚刚创建一个另据项时,该函数指针指向neigh_resolve_output()函数*/
const struct neigh_ops *ops; /*为neigh->output定义的一组操作函数。 */
struct rcu_head rcu;
struct net_device *dev;
u8 primary_key[0];
};
注:源代码是3.2.4版本,和之前的基本差不多,貌似有一两个地方不一样的,不过不影响大局
注2:有些参数暂时没看懂,就没加笔记了
熟悉了之后,来看neigh_update的流程图(见《Understand Linux Kernel Internel》图27-5,图很大,不好截图)
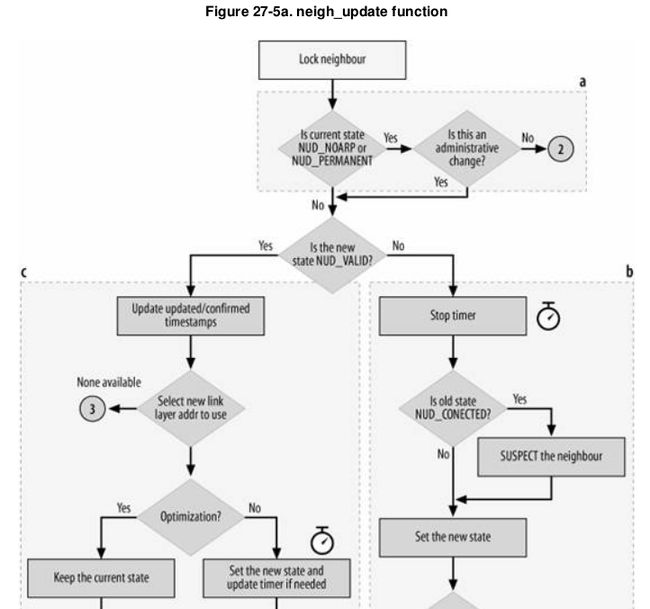
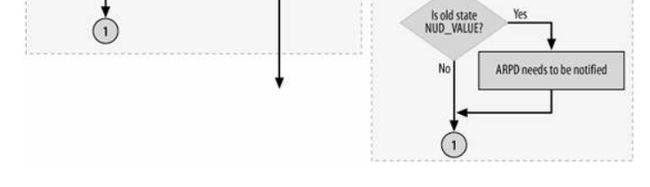
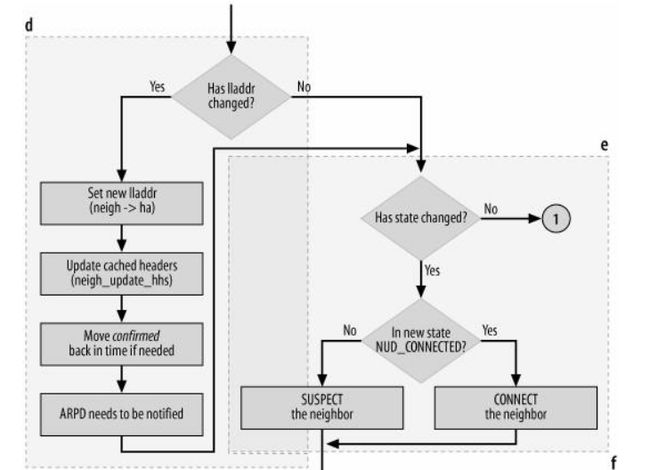
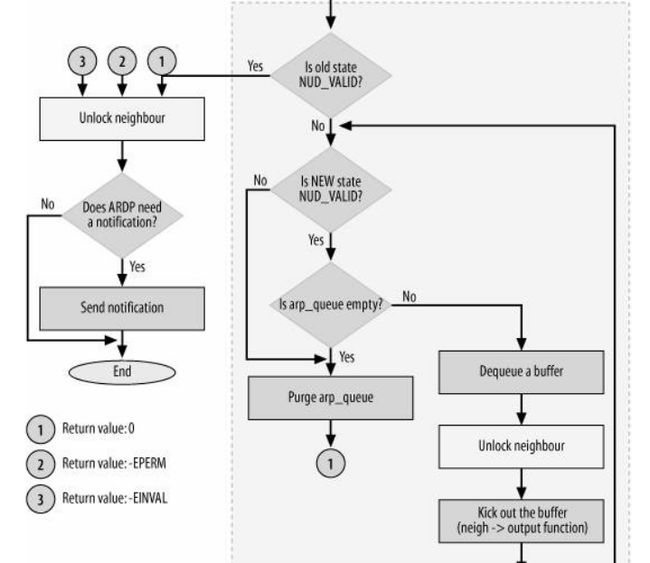

注:有些歪,将就看吧
这个图这么来看
(1)圈圈中数字的出口和入口是一一对应的,意思就是1的出口对应1的入口,依次类推
(2)注意图中虚线框,后面会把一块块的代码给贴上来。
然后我们来看源代码和图怎么对应:
注:后面代码一行没少,而且顺序没乱
注2:内核版本3.2.4
(1)开头部分-这部分没什么好说的。
int neigh_update(struct neighbour *neigh, const u8 *lladdr, u8 new,
u32 flags)
{
/* 用于更新neighbour结构
* 注:该函数也可以用于删除一个neighbour结构,把lladdr=NULL
* 参数说明:
* neigh:指向要更新的neighbour结构
* lladdr,新的链路层地址
* new : 新的状态
* flags:说明见《Linux内核源码剖析-TCP/IP实现》P461
* 返回值:0-正确
* */
u8 old;
int err;
int notify = 0;
struct net_device *dev;
int update_isrouter = 0;
write_lock_bh(&neigh->lock);
dev = neigh->dev;
old = neigh->nud_state;
err = -EPERM;
(2)接下来是图中a部分的代码
/* 流程图见M《深入linux网络技术内幕》p666 */
/* 对应图中区域a*/
if (!(flags & NEIGH_UPDATE_F_ADMIN) && /*当前状态为NUD_NOARP或者NUD_PERMANENT时,如果不是管理员进行改变,就退出 */
(old & (NUD_NOARP | NUD_PERMANENT)))
goto out;
(3)接下来是图中b部分的代码
if (!(new & NUD_VALID)) { /*NUD_VALID = (NUD_PERMANENT | NUD_NOARP | NUD_PROBE | NUD_REACHABLE | NUD_STALE | NUD_DELAY) */
/*新状态无效,对应图中b */
neigh_del_timer(neigh); /*停止计时器 */
if (old & NUD_CONNECTED) /*在旧状态为NUD_CONNECTED时,怀疑neigh */
neigh_suspect(neigh); /*这里会把neigh->output = neigh->ops->output */
neigh->nud_state = new; /*更新状态 */
err = 0;
notify = old & NUD_VALID;
if ((old & (NUD_INCOMPLETE | NUD_PROBE)) && /*旧状态是NUD_VALID的么? */
(new & NUD_FAILED)) {
neigh_invalidate(neigh);
notify = 1;
}
goto out;
}
(4)接下来是图中c部分的代码
/* 根据状态调整硬件地址,对应图中c*/
/* Compare new lladdr with cached one */
if (!dev->addr_len) {
/* First case: device needs no address. */
lladdr = neigh->ha;
} else if (lladdr) {
/* The second case: if something is already cached
and a new address is proposed:
- compare new & old
- if they are different, check override flag
*/
if ((old & NUD_VALID) &&
!memcmp(lladdr, neigh->ha, dev->addr_len))
lladdr = neigh->ha;
} else {
/* No address is supplied; if we know something,
use it, otherwise discard the request.
*/
err = -EINVAL;
if (!(old & NUD_VALID)) /*完全找不到硬件地址,没招了,只能退出了 */
goto out;
lladdr = neigh->ha;
}
/* 如果新状态为NUD_CONNECTED,说明邻居可达,
* 就更新最新确认时间,该部分未在图中表现出来*/
if (new & NUD_CONNECTED)
neigh->confirmed = jiffies;
neigh->updated = jiffies; /* 记录最近一次状态更新时间,对应图中c区右方出口 */
(5)接下来是图中d部分的代码
注:这部分代码不像图中那么画的那么简单
/* If entry was valid and address is not changed,
do not change entry state, if new one is STALE.
对应图中d,但是流程比要复杂很多
*/
err = 0;
update_isrouter = flags & NEIGH_UPDATE_F_OVERRIDE_ISROUTER; /*NEIGH_UPDATE_F_OVERRIDE_ISROUTER为IPV6使用 */
if (old & NUD_VALID) {
if (lladdr != neigh->ha && !(flags & NEIGH_UPDATE_F_OVERRIDE)) { /*硬件地址发生改变 */
update_isrouter = 0;
if ((flags & NEIGH_UPDATE_F_WEAK_OVERRIDE) &&
(old & NUD_CONNECTED)) {
lladdr = neigh->ha;
new = NUD_STALE; /*新状态 */
} else
goto out;
} else {
if (lladdr == neigh->ha && new == NUD_STALE &&
((flags & NEIGH_UPDATE_F_WEAK_OVERRIDE) ||
(old & NUD_CONNECTED))
)
new = old;
}
}
if (new != old) {
neigh_del_timer(neigh);
if (new & NUD_IN_TIMER)
neigh_add_timer(neigh, (jiffies +
((new & NUD_REACHABLE) ?
neigh->parms->reachable_time :
0)));
neigh->nud_state = new;
}
if (lladdr != neigh->ha) {
write_seqlock(&neigh->ha_lock);
memcpy(&neigh->ha, lladdr, dev->addr_len);
write_sequnlock(&neigh->ha_lock);
neigh_update_hhs(neigh);
if (!(new & NUD_CONNECTED))
neigh->confirmed = jiffies -
(neigh->parms->base_reachable_time << 1);
notify = 1;
}
(6)接着是图中e部分代码
注:d部分的出口都会到达e部分的入口
/* 对应图中e*/ if (new == old) /*状态发生了改变后需要根据新状态改变output函数指针 */ goto out; if (new & NUD_CONNECTED) neigh_connect(neigh); /* neigh->output = neigh->ops->connected_output*/ else neigh_suspect(neigh); /* neigh->output = neigh->ops->output;*/
(7)然后是f部分的代码
/* 对应图中f*/
if (!(old & NUD_VALID)) {
struct sk_buff *skb;
/* Again: avoid dead loop if something went wrong */
/* 当状态从无效状态转为有效状态,就将apr_queue队列中缓存的
* skb报文发送出去*/
while (neigh->nud_state & NUD_VALID && /* 排空arp_queue队列 */
(skb = __skb_dequeue(&neigh->arp_queue)) != NULL) {
struct dst_entry *dst = skb_dst(skb);
struct neighbour *n2, *n1 = neigh;
write_unlock_bh(&neigh->lock);
rcu_read_lock();
/* On shaper/eql skb->dst->neighbour != neigh :( */
if (dst && (n2 = dst_get_neighbour(dst)) != NULL)
n1 = n2;
n1->output(n1, skb);
rcu_read_unlock();
write_lock_bh(&neigh->lock);
}
skb_queue_purge(&neigh->arp_queue);
}
(8)出现错误时候的出口,就是圈圈2,3的出口
out:
if (update_isrouter) {
neigh->flags = (flags & NEIGH_UPDATE_F_ISROUTER) ?
(neigh->flags | NTF_ROUTER) :
(neigh->flags & ~NTF_ROUTER);
}
write_unlock_bh(&neigh->lock);
if (notify)
neigh_update_notify(neigh);
return err;
}
7、对邻居子系统的状态熟悉了,那就看看邻居子系统怎么根据状态发送报文吧
(1)首先先熟悉一下报文是怎么从上层递交下来的,然后慢慢介绍进入邻居子系统的过程
如下图,见《Understand Linux Kernel Internel》图18-1
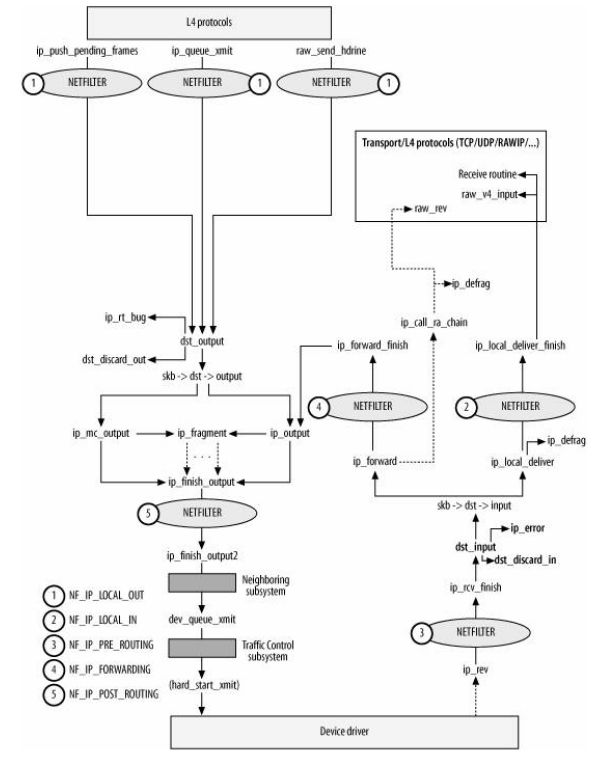
图 8-1 IP层函数框架
这个是IP层的框架,现在我们关注邻居子系统,所以大部分可以不管。注意以下两个事实
(a)可以看到从底层上来的数据由ip_rcv函数处理,并没有经过邻居子系统。所以这条往上的流程都可以暂时不看
(b)注意从上层下来数据,经过ip_finish_output2函数后就进入了邻居子系统
注:可以看到数据从邻居子系统的出口都是dev_queue_xmit,这点和我们之前讲的内容是一致的。
注2:IPV6的流程和IPV4的流程基本一样,是通过ip6_finish_output2进入邻居子系统
注3:如果觉得为什么图中有ip_finish_output了还需要有ip_finish_output2,这个是因为ip_finish_output并不是处理发送,而是需要处理分片,数据最后都是通过ip_finish_output2发送的。
(2)从上图我们知道了邻居子系统在数据包发送过程中所处在的位置,那就跳到ip_finish_output2函数看看流程吧。。(一库)
先看看ip_finish_output2中最后处理报文的简单流程吧(《Understand Linux Kernel Internel》图27-12)
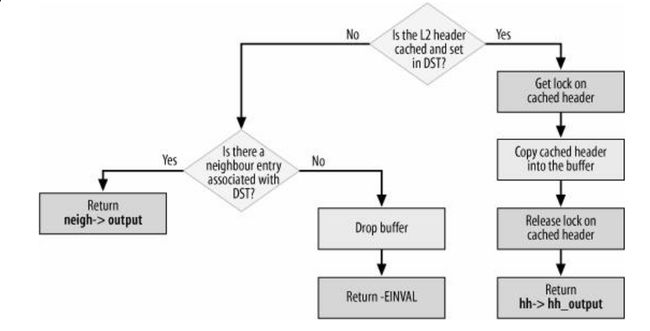
图8-2 ip_finish_output2出口流程
注:书中的说明是这个是ip_finish_output2的处理流程,但是3.2.4的源代码不是这样的。我的代码是这样的
……………………/* 上面的内容省略 */
neigh = dst_get_neighbour(dst);
/* 之后会根据邻居中hh_cache的情况进行分支
* 如果能够找到hh_cache,会立马填充头部并通过dev_queue_xmit发送
* 如果找不到,会进入neigh->output进行发送,neigh->output会因为所处状态
* 的不同将会有3种情况,分别会进入
* neigh_blackhole
* neigh_connected_output
* neigh_resolve_output*/
if (neigh) {
int res = neigh_output(neigh, skb);
rcu_read_unlock();
return res;
}
rcu_read_unlock();
if (net_ratelimit())
printk(KERN_DEBUG "ip_finish_output2: No header cache and no neighbour!\n");
kfree_skb(skb);
return -EINVAL;
}
注2:图中的流程说的反而是neigh_output之后的内容:如下
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb)
{
struct hh_cache *hh = &n->hh;
if ((n->nud_state & NUD_CONNECTED) && hh->hh_len) /*邻居子系统状态为NUD_CONNECTED,并且缓冲头部长度不为0(即存在缓冲头部) */
return neigh_hh_output(hh, skb);
else
return n->output(n, skb);
}
我们先看图中右边的分支线(参考neigh_output函数):需要肯定的就是,右边分支线中的函数入口就是neigh_hh_output()
static inline int neigh_hh_output(struct hh_cache *hh, struct sk_buff *skb)
{
unsigned seq;
int hh_len;
do {
int hh_alen;
seq = read_seqbegin(&hh->hh_lock);
hh_len = hh->hh_len;
hh_alen = HH_DATA_ALIGN(hh_len);
memcpy(skb->data - hh_alen, hh->hh_data, hh_alen);
} while (read_seqretry(&hh->hh_lock, seq));
skb_push(skb, hh_len);
return dev_queue_xmit(skb);
}然后我们关注左分支,左分支情况很复杂,见下图(《Understand Linux Kernel Internel》图27-13,图很外,建议看书去,这种大图太难弄了,自己画又觉得太麻烦了)
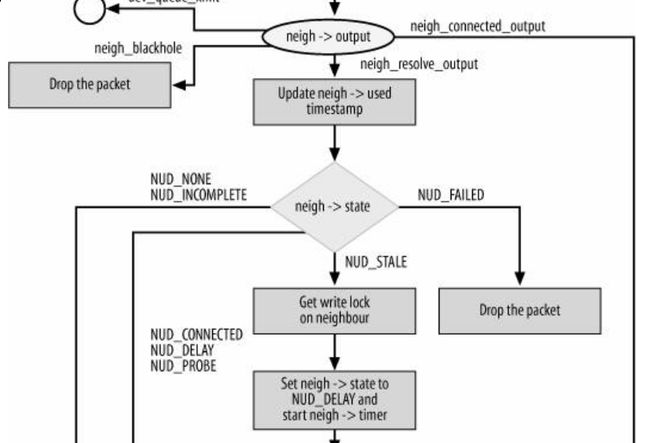
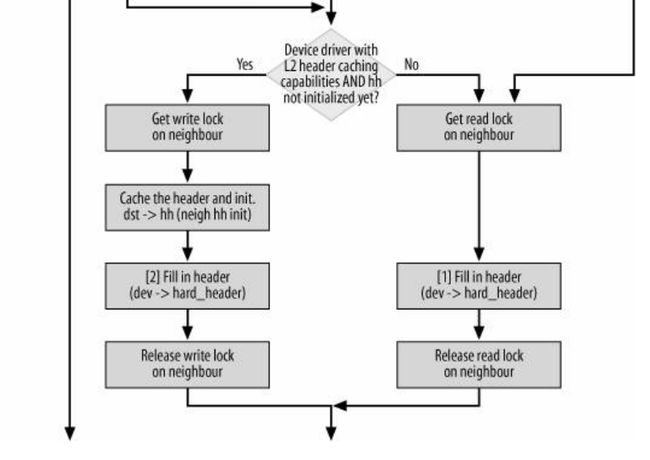
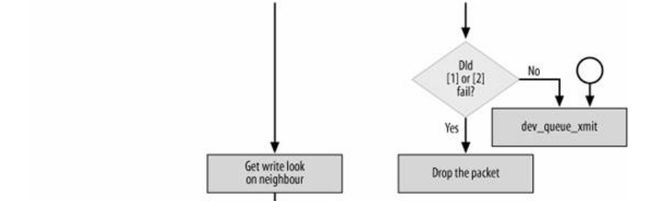
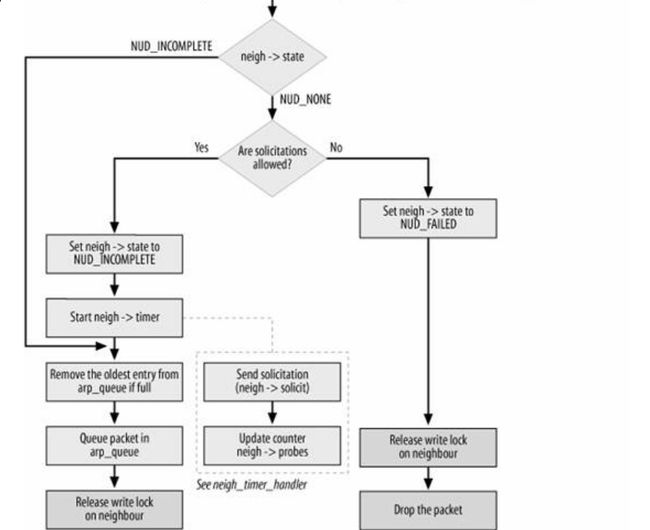
图8-3 neigh->output函数分支情况说明
,这里需要这么看
(1)neigh->output函数没有图中画的这么复杂,这个图是把所有的情况全部加入进来了。
注:output指向的函数在上文第3节有说明,可以返回去看
(2)这里面一个分支就是一个主线,这个图中画出了4个主线,可以根据每个主线去查阅相应的源代码。
先写到这里,休息下,下次看看是不是补充一下队列部分的内容