java集合类TreeMap和TreeSet
看这篇博客前,我觉得很有必要先看下我之前的几篇博客
- Red-Black Trees(红黑树) (TreeMap底层的实现就是用的红黑树数据结构)
- 探索equals()和hashCode()方法 (TreeMap/TreeSet实现使用到的核心方法)
- java中的HashTable,HashMap和HashSet (同为java集合类,对比下他们的区别)
- java中Map,List与Set的区别 (TreeMap/TreeSet最主要的区别就是分别实现了Map和Set接口)
1. TreeSet和TreeMap的关系
- TreeMap和TreeSet都是有序的集合,也就是说他们存储的值都是拍好序的。
- TreeMap和TreeSet都是非同步集合,因此他们不能在多线程之间共享,不过可以使用方法Collections.synchroinzedMap()来实现同步
- 运行速度都要比Hash集合慢,他们内部对元素的操作时间复杂度为O(logN),而HashMap/HashSet则为O(1)。
- 最主要的区别就是TreeSet和TreeMap非别实现Set和Map接口
- TreeSet只存储一个对象,而TreeMap存储两个对象Key和Value(仅仅key对象有序)
- TreeSet中不能有重复对象,而TreeMap中可以存在
2. TreeSet实现原理
TreeMap 的实现使用了红黑树数据结构,也就是一棵自平衡的排序二叉树,这样就可以保证快速检索指定节点。对于 TreeMap 而言,它采用一种被称为“红黑树”的排序二叉树来保存 Map 中每个 Entry —— 每个 Entry 都被当成“红黑树”的一个节点对待。举例:
public class TreeMapTest { public static void main(String[] args) { TreeMap<String , Double> map = new TreeMap<String , Double>(); map.put("ccc" , 89.0); map.put("aaa" , 80.0); map.put("zzz" , 80.0); map.put("bbb" , 89.0); System.out.println(map); } }当程序执行 map.put("ccc" , 89.0); 时,系统将直接把 "ccc"-89.0 这个 Entry 放入 Map 中,这个 Entry 就是该“红黑树”的根节点。接着程序执行 map.put("aaa" , 80.0); 时,程序会将 "aaa"-80.0 作为新节点添加到已有的红黑树中。
以后每向 TreeMap 中放入一个 key-value 对,系统都需要将该 Entry 当成一个新节点,添加成已有红黑树中,通过这种方式就可保证 TreeMap 中所有 key 总是由小到大地排列。例如我们输出上面程序,将看到如下结果(所有 key 由小到大地排列):
{aaa=80.0, bbb=89.0, ccc=89.0, zzz=80.0}
TreeMap的添加节点(put()方法)
对于 TreeMap 而言,由于它底层采用一棵“红黑树”来保存集合中的 Entry,这意味这 TreeMap 添加元素、取出元素的性能都比 HashMap 低(红黑树和Hash数据结构上的区别):当 TreeMap 添加元素时,需要通过循环找到新增 Entry 的插入位置,因此比较耗性能;当从 TreeMap 中取出元素时,需要通过循环才能找到合适的 Entry,也比较耗性能。但 TreeMap、TreeSet 比 HashMap、HashSet 的优势在于:TreeMap 中的所有 Entry 总是按 key 根据指定排序规则保持有序状态,TreeSet 中所有元素总是根据指定排序规则保持有序状态。
为了很好的理解TreeMap你必须先理解红黑树,然而红黑树又是一种特殊的二叉查找树,所以你必须先看两篇博客
- Binary search tree(二叉查找树)
- Red-Black Trees(红黑树)
public V put(K key, V value)
{
// 先以 t 保存链表的 root 节点
Entry<K,V> t = root;
// 如果 t==null,表明是一个空链表,即该 TreeMap 里没有任何 Entry
if (t == null)
{
// 将新的 key-value 创建一个 Entry,并将该 Entry 作为 root
root = new Entry<K,V>(key, value, null);
// 设置该 Map 集合的 size 为 1,代表包含一个 Entry
size = 1;
// 记录修改次数为 1
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
Comparator<? super K> cpr = comparator;
// 如果比较器 cpr 不为 null,即表明采用定制排序
if (cpr != null)
{
do {
// 使用 parent 上次循环后的 t 所引用的 Entry
parent = t;
// 拿新插入 key 和 t 的 key 进行比较
cmp = cpr.compare(key, t.key);
// 如果新插入的 key 小于 t 的 key,t 等于 t 的左边节点
if (cmp < 0)
t = t.left;
// 如果新插入的 key 大于 t 的 key,t 等于 t 的右边节点
else if (cmp > 0)
t = t.right;
// 如果两个 key 相等,新的 value 覆盖原有的 value,
// 并返回原有的 value
else
return t.setValue(value);
} while (t != null);
}
else
{
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
// 使用 parent 上次循环后的 t 所引用的 Entry
parent = t;
// 拿新插入 key 和 t 的 key 进行比较
cmp = k.compareTo(t.key);
// 如果新插入的 key 小于 t 的 key,t 等于 t 的左边节点
if (cmp < 0)
t = t.left;
// 如果新插入的 key 大于 t 的 key,t 等于 t 的右边节点
else if (cmp > 0)
t = t.right;
// 如果两个 key 相等,新的 value 覆盖原有的 value,
// 并返回原有的 value
else
return t.setValue(value);
} while (t != null);
}
// 将新插入的节点作为 parent 节点的子节点
Entry<K,V> e = new Entry<K,V>(key, value, parent);
// 如果新插入 key 小于 parent 的 key,则 e 作为 parent 的左子节点
if (cmp < 0)
parent.left = e;
// 如果新插入 key 小于 parent 的 key,则 e 作为 parent 的右子节点
else
parent.right = e;
// 修复红黑树
fixAfterInsertion(e); // ①
size++;
modCount++;
return null;
}
上面这段代码看起来复杂其实不然,本质上就是红黑树德元素插入操作的代码。看下面红黑树插入操作的伪代码
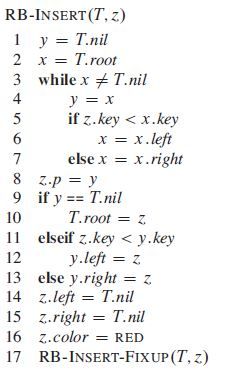
private void deleteEntry(Entry<K,V> p)
{
modCount++;
size--;
// 如果被删除节点的左子树、右子树都不为空
if (p.left != null && p.right != null)
{
// 用 p 节点的中序后继节点代替 p 节点
Entry<K,V> s = successor (p);
p.key = s.key;
p.value = s.value;
p = s;
}
// 如果 p 节点的左节点存在,replacement 代表左节点;否则代表右节点。
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null)
{
replacement.parent = p.parent;
// 如果 p 没有父节点,则 replacemment 变成父节点
if (p.parent == null)
root = replacement;
// 如果 p 节点是其父节点的左子节点
else if (p == p.parent.left)
p.parent.left = replacement;
// 如果 p 节点是其父节点的右子节点
else
p.parent.right = replacement;
p.left = p.right = p.parent = null;
// 修复红黑树
if (p.color == BLACK)
fixAfterDeletion(replacement); // ①
}
// 如果 p 节点没有父节点
else if (p.parent == null)
{
root = null;
}
else
{
if (p.color == BLACK)
// 修复红黑树
fixAfterDeletion(p); // ②
if (p.parent != null)
{
// 如果 p 是其父节点的左子节点
if (p == p.parent.left)
p.parent.left = null;
// 如果 p 是其父节点的右子节点
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
检索节点
当 TreeMap 根据 key 来取出 value 时,TreeMap 对应的方法如下:
public V get(Object key)
{
// 根据指定 key 取出对应的 Entry
Entry>K,V< p = getEntry(key);
// 返回该 Entry 所包含的 value
return (p==null ? null : p.value);
}
从上面程序的粗体字代码可以看出,get(Object key) 方法实质是由于 getEntry() 方法实现的,这个 getEntry() 方法的代码如下:
final Entry<K,V> getEntry(Object key)
{
// 如果 comparator 不为 null,表明程序采用定制排序
if (comparator != null)
// 调用 getEntryUsingComparator 方法来取出对应的 key
return getEntryUsingComparator(key);
// 如果 key 形参的值为 null,抛出 NullPointerException 异常
if (key == null)
throw new NullPointerException();
// 将 key 强制类型转换为 Comparable 实例
Comparable<? super K> k = (Comparable<? super K>) key;
// 从树的根节点开始
Entry<K,V> p = root;
while (p != null)
{
// 拿 key 与当前节点的 key 进行比较
int cmp = k.compareTo(p.key);
// 如果 key 小于当前节点的 key,向“左子树”搜索
if (cmp < 0)
p = p.left;
// 如果 key 大于当前节点的 key,向“右子树”搜索
else if (cmp > 0)
p = p.right;
// 不大于、不小于,就是找到了目标 Entry
else
return p;
}
return null;
}
上面的 getEntry(Object obj) 方法也是充分利用排序二叉树的特征来搜索目标 Entry,程序依然从二叉树的根节点开始,如果被搜索节点大于当前节点,程序向“右子树”搜索;如果被搜索节点小于当前节点,程序向“左子树”搜索;如果相等,那就是找到了指定节点。
当 TreeMap 里的 comparator != null 即表明该 TreeMap 采用了定制排序,在采用定制排序的方式下,TreeMap 采用 getEntryUsingComparator(key) 方法来根据 key 获取 Entry。下面是该方法的代码:
final Entry<K,V> getEntryUsingComparator(Object key)
{
K k = (K) key;
// 获取该 TreeMap 的 comparator
Comparator<? super K> cpr = comparator;
if (cpr != null)
{
// 从根节点开始
Entry<K,V> p = root;
while (p != null)
{
// 拿 key 与当前节点的 key 进行比较
int cmp = cpr.compare(k, p.key);
// 如果 key 小于当前节点的 key,向“左子树”搜索
if (cmp < 0)
p = p.left;
// 如果 key 大于当前节点的 key,向“右子树”搜索
else if (cmp > 0)
p = p.right;
// 不大于、不小于,就是找到了目标 Entry
else
return p;
}
}
return null;
}
其实 getEntry、getEntryUsingComparator 两个方法的实现思路完全类似,只是前者对自然排序的 TreeMap 获取有效,后者对定制排序的 TreeMap 有效。
通过上面源代码的分析不难看出,TreeMap 这个工具类的实现其实很简单。或者说:从内部结构来看,TreeMap 本质上就是一棵“红黑树”,而 TreeMap 的每个 Entry 就是该红黑树的一个节点。
3. 常见问题
其实这个问题就是在问红黑树相对于排序二叉树的优点。我们都知道排序二叉树虽然可以快速检索,但在最坏的情况下:如果插入的节点集本身就是有序的,要么是由小到大排列,要么是由大到小排列,那么最后得到的排序二叉树将变成链表:所有节点只有左节点(如果插入节点集本身是大到小排列);或所有节点只有右节点(如果插入节点集本身是小到大排列)。在这种情况下,排序二叉树就变成了普通链表,其检索效率就会很差。
为了改变排序二叉树存在的不足,Rudolf Bayer 与 1972 年发明了另一种改进后的排序二叉树:红黑树,他将这种排序二叉树称为“对称二叉 B 树”,而红黑树这个名字则由 Leo J. Guibas 和 Robert Sedgewick 于 1978 年首次提出。
红黑树是一个更高效的检索二叉树,因此常常用来实现关联数组。典型地,JDK 提供的集合类 TreeMap 本身就是一个红黑树的实现。
红黑树在原有的排序二叉树增加了如下几个要求:
- 性质 1:每个节点要么是红色,要么是黑色。
- 性质 2:根节点永远是黑色的。
- 性质 3:所有的叶节点都是空节点(即 null),并且是黑色的。
- 性质 4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
- 性质 5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。
Java 中实现的红黑树可能有如图 6 所示结构:
图 6. Java 红黑树的示意
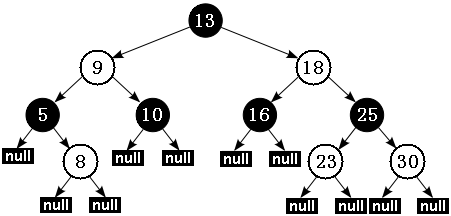
备注:本文中所有关于红黑树中的示意图采用白色代表红色。黑色节点还是采用了黑色表示。
根据性质 5:红黑树从根节点到每个叶子节点的路径都包含相同数量的黑色节点,因此从根节点到叶子节点的路径中包含的黑色节点数被称为树的“黑色高度(black-height)”。
性质 4 则保证了从根节点到叶子节点的最长路径的长度不会超过任何其他路径的两倍。假如有一棵黑色高度为 3 的红黑树:从根节点到叶节点的最短路径长度是 2,该路径上全是黑色节点(黑节点 - 黑节点 - 黑节点)。最长路径也只可能为 4,在每个黑色节点之间插入一个红色节点(黑节点 - 红节点 - 黑节点 - 红节点 - 黑节点),性质 4 保证绝不可能插入更多的红色节点。由此可见,红黑树中最长路径就是一条红黑交替的路径。
由此我们可以得出结论:对于给定的黑色高度为 N 的红黑树,从根到叶子节点的最短路径长度为 N-1,最长路径长度为 2 * (N-1)。
提示:排序二叉树的深度直接影响了检索的性能,正如前面指出,当插入节点本身就是由小到大排列时,排序二叉树将变成一个链表,这种排序二叉树的检索性能最低:N 个节点的二叉树深度就是 N-1。
红黑树通过上面这种限制来保证它大致是平衡的——因为红黑树的高度不会无限增高,这样保证红黑树在最坏情况下都是高效的,不会出现普通排序二叉树的情况。
由于红黑树只是一个特殊的排序二叉树,因此对红黑树上的只读操作与普通排序二叉树上的只读操作完全相同,只是红黑树保持了大致平衡,因此检索性能比排序二叉树要好很多。
但在红黑树上进行插入操作和删除操作会导致树不再符合红黑树的特征,因此插入操作和删除操作都需要进行一定的维护,以保证插入节点、删除节点后的树依然是红黑树。
”TreeMap、TreeSet 对比 HashMap、HashSet的优缺点?“
缺点:
对于 TreeMap 而言,由于它底层采用一棵“红黑树”来保存集合中的 Entry,这意味这 TreeMap 添加元素、取出元素的性能都比 HashMap (O(1))低:
- 当 TreeMap 添加元素时,需要通过循环找到新增 Entry 的插入位置,因此比较耗性能(O(logN))
- 当从 TreeMap 中取出元素时,需要通过循环才能找到合适的 Entry,也比较耗性能(O(logN))
TreeMap 中的所有 Entry 总是按 key 根据指定排序规则保持有序状态,TreeSet 中所有元素总是根据指定排序规则保持有序状态。
好吧,java集合类的讲解就告一段落了,这几天把重要的Set,List,Map,HashMap,HashSet,TreeMap,TreeSet都讲了一遍,不过还要慢慢屡清楚,集合类就先讲这些,以后碰到了哪些重要的,还会继续写。
Reference:
http://www.ibm.com/developerworks/cn/java/j-lo-tree/index.html
http://shmilyaw-hotmail-com.iteye.com/blog/1836431
http://blog.csdn.net/mazhimazh/article/details/19028311