GIS+=地理信息+云计算技术——Spark集群部署
Spark 1.5.4:wget http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz
Hadoop 2.6.3:wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.6.3/hadoop-2.6.3.tar.gz
scala :apt-get install scala
第二步:配置环境变量
执行/etc/profile
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_80
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/BIN:${SCALA_HOME}/bin:${SPARK_HOME}/bin:/home/supermap/program/hadoop-2.6.3/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export SCALA_HOME=/usr/lib/scala/scala-2.11.7
export PATH=${SCALA_HOME}/bin:$PATH
export SPARK_HOME=/program/spark-1.5.2-bin-hadoop2.6
source /etc/profile
第三步:创建镜像
通过OpenStack管理器根据配置好的虚拟机创建镜像,生成的镜像配置如下:
镜像概况信息
名称 spark-hadoop
ID 61055db5-598b-4f1a-98fa-d2cbbf305d0c
状态 Active
公有 False
受保护的 False
校验和 47acf7993101713aee17764802602941
________________________________________
配置 4.4 GB
容器格式 BARE
磁盘格式 QCOW2
最小磁盘 60.0GB
第四步:创建虚拟机
基于创建的镜像,生成2台虚拟机,加上最开始用于创建镜像的1台,一共3台虚拟主机,名称分别为:
spark_hadoop_master
spark_hadoop_slave1
spark_hadoop_slave2
下面就可以开始做与创建Spark集群相关的操作了。
第五步:设置主机名
1.在/etc/hostname中就改主机名,分别设置三台主机为master、slave1、slave2,并重启

2.重启之后,分别设置三个节点etc/hosts,指定ip和主机名的对应关系。
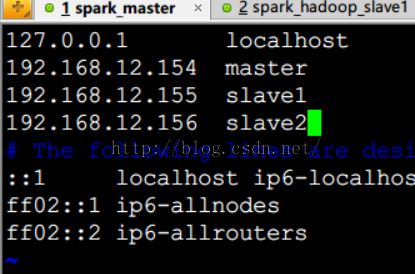
通过测试root@master:~# ssh slave1,在输入root用户密码后可以登录。
第六步:修改ssh无密码访问
首先开启root用户访问权限
1. 修改/etc/ssh/sshd-config文件,设置如下:
2. PermitRootLogin yes
3. PubkeyAuthentication yes
4. PasswordAuthentication yes
重新启动ssh服务:service ssh restart
再进行如下测试,可以免输入密码登录了。

第七步:配置Spark集群
进入Spark的conf目录:

把spark-env.sh.template拷贝为spark-env.sh
把slaves.template拷贝为slaves
vim打开spark-env.sh修改其中的内容,加入以下设置
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_80
export SPARK_MASTER_IP=192.168.12.154
export SPARK_WORKER_MEMORY=4g
export SCALA_HOME=/usr/lib/scala/scala-2.11.7
export HADOOP_CONF_DIR=/home/supermap/program/hadoop-2.6.3/conf
SPARK_WORKER_MEMORY:制定的Worker节点能够最大分配给Excutors的内存大小,由于配置的虚拟机是4g内存,为了最大限度使用内存,这里设置4G。
接下来配置slaves文件,把Workers节点都添加进去:

这种配置把master也作为一个Worker节点。
以上配置在master和slave1,slave2节点都做相同处理。
第八步:启动集群
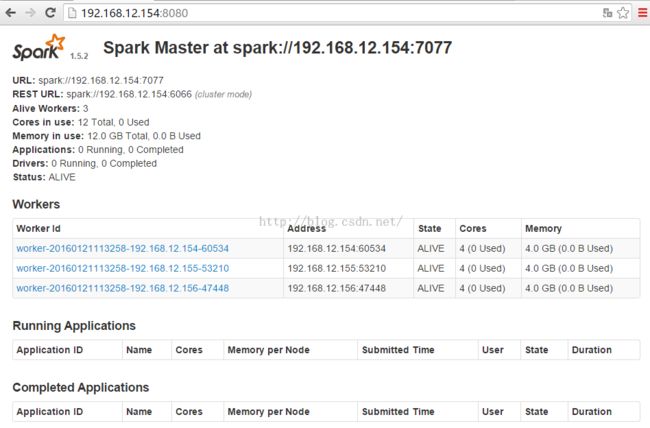
这里测试没有启动Hadoop集群,只需要Spark集群进行启动即可,在Spark目录下,运行sbin/start-all.sh即可启动集群服务。

最后通过访问spark管理页面查看服务状态