hadoop2.2+mahout0.9实战
版本:hadoop2.2.0,mahout0.9。
使用mahout的org.apache.mahout.cf.taste.hadoop.item.RecommenderJob进行测试。
首先说明下,如果使用官网提供的下载hadoop2.2.0以及mahout0.9进行调用mahout的相关算法会报错。一般报错如下:
java.lang.IncompatibleClassChangeError: Found interface org.apache.hadoop.mapreduce.JobContext, but class was expected at org.apache.mahout.common.HadoopUtil.getCustomJobName(HadoopUtil.java:174) at org.apache.mahout.common.AbstractJob.prepareJob(AbstractJob.java:614) at org.apache.mahout.cf.taste.hadoop.preparation.PreparePreferenceMatrixJob.run(PreparePreferenceMatrixJob.java:73) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)这个是因为目前mahout只支持hadoop1 的缘故。在这里可以找到解决方法:https://issues.apache.org/jira/browse/MAHOUT-1329。主要就是修改pom文件,修改mahout的依赖。
大家可以下载修改后的源码包(http://download.csdn.net/detail/fansy1990/7165957)自己编译mahout(mvn clean install -Dhadoop2 -Dhadoop.2.version=2.2.0 -DskipTests),或者直接下载已经编译好的jar包(http://download.csdn.net/detail/fansy1990/7166017、http://download.csdn.net/detail/fansy1990/7166055)。
接着,按照这篇文章建立eclipse的环境:http://blog.csdn.net/fansy1990/article/details/22896249。环境配置好了之后,需要添加mahout的jar包,下载前面提供的jar包,然后导入到java工程中。
编写下面的java代码:
package fz.hadoop2.util;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.yarn.conf.YarnConfiguration;
public class Hadoop2Util {
private static Configuration conf=null;
private static final String YARN_RESOURCE="node31:8032";
private static final String DEFAULT_FS="hdfs://node31:9000";
public static Configuration getConf(){
if(conf==null){
conf = new YarnConfiguration();
conf.set("fs.defaultFS", DEFAULT_FS);
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", YARN_RESOURCE);
}
return conf;
}
}
package fz.mahout.recommendations;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.util.ToolRunner;
import org.apache.mahout.cf.taste.hadoop.item.RecommenderJob;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import fz.hadoop2.util.Hadoop2Util;
/**
* 测试mahout org.apache.mahout.cf.taste.hadoop.item.RecommenderJob
* environment:
* mahout0.9
* hadoop2.2
* @author fansy
*
*/
public class RecommenderJobTest{
//RecommenderJob rec = null;
Configuration conf =null;
@Before
public void setUp(){
// rec= new RecommenderJob();
conf= Hadoop2Util.getConf();
System.out.println("Begin to test...");
}
@Test
public void testMain() throws Exception{
String[] args ={
"-i","hdfs://node31:9000/input/user.csv",
"-o","hdfs://node31:9000/output/rec001",
"-n","3","-b","false","-s","SIMILARITY_EUCLIDEAN_DISTANCE",
"--maxPrefsPerUser","7","--minPrefsPerUser","2",
"--maxPrefsInItemSimilarity","7",
"--outputPathForSimilarityMatrix","hdfs://node31:9000/output/matrix/rec001",
"--tempDir","hdfs://node31:9000/output/temp/rec001"};
ToolRunner.run(conf, new RecommenderJob(), args);
}
@After
public void cleanUp(){
}
}
在前面下载好了mahout的jar包后,需要把这些jar包放入hadoop2的lib目录(share/hadoop/mapreduce/lib,注意不一定一定要这个路径,其他hadoop lib也可以)。然后运行RecommenderJobTest即可。
输入文件如下:
1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 3,101,2.5 3,104,4.0 3,105,4.5 3,107,5.0 4,101,5.0 4,103,3.0 4,104,4.5 4,106,4.0 5,101,4.0 5,102,3.0 5,103,2.0 5,104,4.0 5,105,3.5 5,106,4.0
输出文件为:
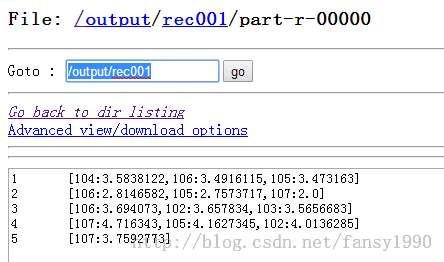
最后一个MR日志:
2014-04-09 13:03:09,301 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - io.sort.factor is deprecated. Instead, use mapreduce.task.io.sort.factor 2014-04-09 13:03:09,301 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.map.child.java.opts is deprecated. Instead, use mapreduce.map.java.opts 2014-04-09 13:03:09,302 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - io.sort.mb is deprecated. Instead, use mapreduce.task.io.sort.mb 2014-04-09 13:03:09,302 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.task.timeout is deprecated. Instead, use mapreduce.task.timeout 2014-04-09 13:03:09,317 INFO [main] client.RMProxy (RMProxy.java:createRMProxy(56)) - Connecting to ResourceManager at node31/192.168.0.31:8032 2014-04-09 13:03:09,460 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(287)) - Total input paths to process : 1 2014-04-09 13:03:09,515 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(394)) - number of splits:1 2014-04-09 13:03:09,531 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - fs.default.name is deprecated. Instead, use fs.defaultFS 2014-04-09 13:03:09,547 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(477)) - Submitting tokens for job: job_1396479318893_0015 2014-04-09 13:03:09,602 INFO [main] impl.YarnClientImpl (YarnClientImpl.java:submitApplication(174)) - Submitted application application_1396479318893_0015 to ResourceManager at node31/192.168.0.31:8032 2014-04-09 13:03:09,604 INFO [main] mapreduce.Job (Job.java:submit(1272)) - The url to track the job: http://node31:8088/proxy/application_1396479318893_0015/ 2014-04-09 13:03:09,604 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1317)) - Running job: job_1396479318893_0015 2014-04-09 13:03:24,170 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1338)) - Job job_1396479318893_0015 running in uber mode : false 2014-04-09 13:03:24,170 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - map 0% reduce 0% 2014-04-09 13:03:32,299 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - map 100% reduce 0% 2014-04-09 13:03:41,373 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - map 100% reduce 100% 2014-04-09 13:03:42,404 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1356)) - Job job_1396479318893_0015 completed successfully 2014-04-09 13:03:42,485 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1363)) - Counters: 43 File System Counters FILE: Number of bytes read=306 FILE: Number of bytes written=163713 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=890 HDFS: Number of bytes written=192 HDFS: Number of read operations=10 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=5798 Total time spent by all reduces in occupied slots (ms)=6179 Map-Reduce Framework Map input records=7 Map output records=21 Map output bytes=927 Map output materialized bytes=298 Input split bytes=131 Combine input records=0 Combine output records=0 Reduce input groups=5 Reduce shuffle bytes=298 Reduce input records=21 Reduce output records=5 Spilled Records=42 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=112 CPU time spent (ms)=1560 Physical memory (bytes) snapshot=346509312 Virtual memory (bytes) snapshot=1685782528 Total committed heap usage (bytes)=152834048 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=572 File Output Format Counters Bytes Written=192
说明:由于只测试了一个协同过滤算法的程序,其他的算法并没有测试,如果其他算法在此版本上有问题,也是可能有的。
ps:如果是使用web项目的话,可能会报jar包冲突,那么需要把mahout-core-0.9-job.jar 和 mahout-examples-0.9-job.jar中的javax下面的el和servlet文件夹去掉就可以了。
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990