《Master Opencv...读书笔记》非刚性人脸跟踪 II
上一篇博文中,我们了解了系统的功能和模块,明确了需要采集哪些类型的样本点及利用类的序列化的保存方式。这次将介绍几何约束模块,通过统计形态分析法(Statistical Shape Analysis, SSA),利用样本点建立对形状的描述,然后对描述的形状建立点分布模型,并从中学习统计参数,完成对形状的建模。该模块在后续跟踪阶段将被用来约束和剔除不合理的特征点。
本次讲解目录:
- facial geometry是什么?程序主要数据结构介绍
- 普氏分析是什么?作用是什么?怎么实现?[代码分析]
- 线性形状模型是什么?作用是什么?如何实现?[代码分析]
- 如何联合全局和局部特征?[代码分析]
- 展示训练后的结果,介绍可视化程序
简单概括:【从N幅图像提取k个表情】
根据上次对N幅图像手工采集得到的样本点,首先将point2f向量转换成坐标矩阵,然后利用普氏分析、标准正交基、SVD等技术提取非刚性变化(脸部表情),构建描述人脸模型的联合表达(刚性-非刚性)矩阵V,并计算N幅图像的样本点在该联合空间投影后得到坐标的标准差矩阵e,最后将上次标注的连接关系从Vec2i向量转换成坐标索引矩阵形式。
本文末尾,将以动画的形式展示提取的人脸表情模型,表情模型数量由训练过程(即选前k个奇异值)决定。注意,这边的k个表情前后无衔接关系,动画只是展示不同表情模型在联合(刚性-非刚性)空间坐标轴(x和y轴±50)上,失真程度为3个标准差时的表情形状。
1. Facial geometry
人脸由眼睛、鼻子、嘴巴、下巴等部位构成,正是因为这些部位形状、大小和相对位置的各种变化,才使得人脸表情千差万别,因此可以对这些部位的形状和结构关系进行几何描述,作为人脸表情识别的重要特征。这里,几何关系就是指预定义点集的空间组态模式,而这些点与脸部器官在几何空间存在对应关系(比如眼角、鼻尖、眉毛)。
Facial geometry,通过两种元素的参数化配置组成:全局变形(刚性)和局部变形(非刚性)。全局变形是指人脸在图像中的分布,允许人脸出现在图像中任意位置,包括人脸的坐标(x,y)、角度、大小;局部形变是指不同人和不同表情之间脸部形状的不同,与全局形变不同,人脸的高度结构化特征对局部形变产生了极大的约束。全局变形可以由二维空间的函数表达,并且可以应用于任何类型的对象;然而局部形变只针对特定目标,需要从训练集中学习。
本文程序可以捕捉单个人物的表情变化、不同人的脸型差异、或者不同人的不同表情变化。该程序将用shape_model类来存储这些参数,
数据结构采用以下4个主要的矩阵:
Mat p; //parameter vector (kx1) CV_32F Mat V; //shape basis (2nxk) CV_32F Mat e; //parameter variance (kx1) CV_32F Mat C; //connectivity (cx2) CV_32S
V:描述人脸模型的联合矩阵
e:存在联合空间内表情模型坐标的标准差矩阵
C:描述之前标注的连接关系矩阵
主要操作包含以下3个函数:
void
calc_params(const vector<Point2f> &pts, //points to compute parameters from
const Mat weight = Mat(), //weight of each point (nx1) CV_32F
const float c_factor = 3.0); //clamping factor
vector<Point2f> calc_shape(); //shape described by parameters @p
void
train(const vector<vector<Point2f> > &p, //N-example shapes
const vector<Vec2i> &con = vector<Vec2i>(),//point-connectivity
const float frac = 0.95, //fraction of variation to retain
const int kmax = 10); //maximum number of modes to retain
calc_params函数:将点集映射到合理的脸型上,它还可以为每个映射点提供单独的置信权重。这一步供人脸跟踪时调用,涉及上面Mat p矩阵,人脸跟踪将在下一篇博文介绍。
calc_shape函数:根据子空间V和方差矢量e对参数向量p进行解编码,产生新点集,这些点集在人脸跟踪和结果展示时会用到。
trian函数:从脸型样本集中学习编码模型,每个编码模型包含相同数量的点,该函数也是本次学习的重点。下面我们先讲解普氏分析Procrustes analysis,如何注册刚性点集;然后讲解线性模型,如何表达局部变形。
在将Procrustes分析之前,承接上次文章,看看我们目前对什么类型的数据做操作 。
函数:pts2mat
入参:
vector<vector<Point2f> >&points ,points向量存放了所有图像标注的样本点
返回值:
Mat x, 它是一个2n*N矩阵,n表示样本点数量,N表示图像帧数
Mat shape_model::pts2mat(const vector<vector<Point2f> > &points)
{
int N = points.size();
/*检查图像数量大于0*/
assert(N > 0); //assert(expression),如果括号内的表达式值为假,则打印出错信息
int n = points[0].size();
for(int i = 1; i < N; i++)
/*检查每幅图像的样本点数量是否相同*/
assert(int(points[i].size()) == n);
Mat X(2*n,N,CV_32F);
for(int i = 0; i < N; i++){
Mat x = X.col(i),y = Mat(points[i]).reshape(1,2*n); //points[i]是一个point2f向量,存放着一幅图像的样本点
y.copyTo(x);
}
return X;
}
2. Procrustes Analysis
为了构建脸型的形变模型,我们首先要从标注的样本点中剔除全局刚性部分,即保留物体在去除位移、旋转和缩放因素后所遗留的几何信息。

选取N幅同类目标物体的二维图像,并用上一篇博文的方法标注轮廓点,这样就得到训练样本集:
![]()
由于图像中目标物体的形状和位置存在较大偏差,因此所得到的数据并不具有仿射不变性,需要对其进行归一化处理。这里采用Procrustes分析方法对样本集中的所有形状集合进行归一化。形状和位置的载体还是样本点的空间坐标。
普氏分析法是一种用来分析形状分布的方法。数学上来讲,就是不断迭代,寻找标准形状(canonical shape),并利用最小二乘法寻找每个样本形状到这个标准形状的仿射变化方式。(可参照维基百科的GPA算法)
本书中,两个形状的归一化过程(一个形状为canonical shape,另一个为样本形状):
(1) 求每个样本点i(i=1,2..,n)在N幅图像中的均值
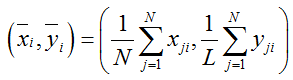
(2) 对所有形状的大小进行归一化,即将每个样本点减去其对应均值

(3) 根据去中心化数据,计算每幅图像中形状的重心,对于第i幅图像,其重心为:
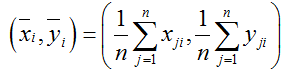
(4) 根据重心和角度,将标准和样本形状对齐在一起,使得两个形状的普氏距离最小,下式为普氏距离定义:
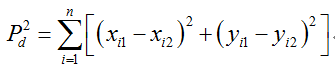
这个第(4)步的具体做法,不断迭代以下过程:
(a)通过计算每幅图像中所有归一化样本点的平均值得到每个图像的标准形状canonical shape。
(b)利用最小二乘法求每个图像中样本形状到标准形状的旋转角度。根据普氏距离的定义,也就是求:
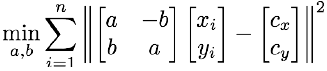
其中的a和b表示仿射变换里旋转变化的参数:

对上式求偏导数,可以得到所求的a和b:
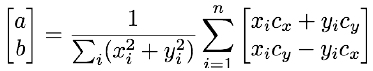
(c)根据旋转参数,对样本形状做旋转变化,得到和标准形状对齐的新的形状
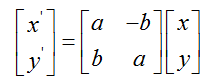
(d)重复以上步骤,直到达到指定循环次数或者前后两次迭代之间canonical shape的绝对范数满足一定阈值
Procrustesanalysis的作用可以看作是一种对原始数据的预处理,目的是为了获取更好的局部变化模型作为后续模型学习的基础。如下图所示,每一个人脸特征点可以用一种单独的颜色表示;经过归一化变化,人脸的结构越来越明显,即脸部特征簇的位置越来越接近他们的平均位置;经过一系列迭代,尺度和旋转的归一化操作,这些特征簇变得更加紧凑,它们的分布越来越能表达人脸表情的变化。【剔除刚性部分、保留柔性部分】
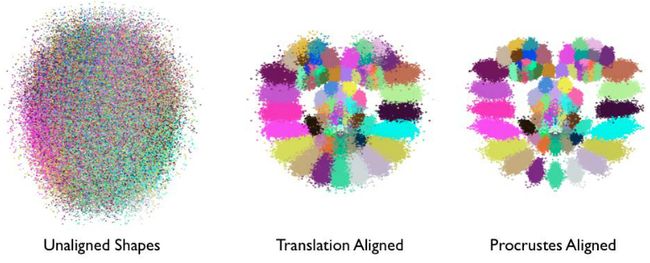
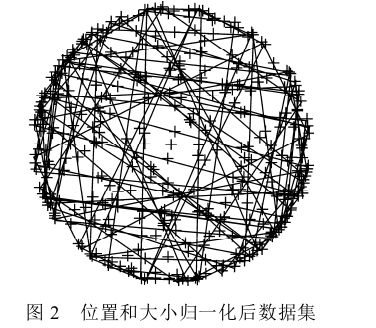
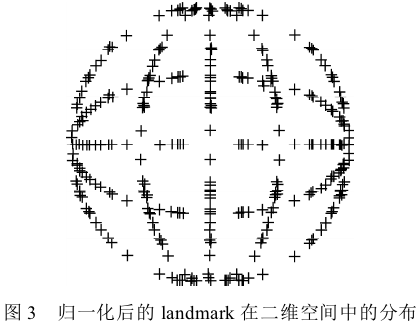
上图为不同大小、不同长宽比的矩形,经过归一化过程后,各个样本点分布服从一定概率分布趋势。
具体代码实现:
函数:Mat shape_model::procrustes(const Mat &X,const int itol,constfloat ftol)
矩阵X:2n*N维矩阵,即有N副图像,每幅图像有n个特征点(2n是因为x和y坐标)
Itol:迭代次数
Ftol:求绝对范数的阈值
返回值:矩阵P,存放对齐后的形状坐标
Mat shape_model::procrustes(const Mat &X,const int itol,const float ftol)
{
/* X.cols:特征点个数,X.rows: 图像数量*2 */
int N = X.cols,n = X.rows/2;
//remove centre of mass
Mat P = X.clone();
for(int i = 0; i < N; i++)
{
/*取X第i个列向量*/
Mat p = P.col(i);
float mx = 0,my = 0;
for(int j = 0; j < n; j++)
{
mx += p.fl(2*j);
my += p.fl(2*j+1);
}
/*分别求图像集,2维空间坐标x和y的平均值*/
mx /= n;
my /= n;
/*对x,y坐标去中心化*/
for(int j = 0; j < n; j++)
{
p.fl(2*j) -= mx;
p.fl(2*j+1) -= my;
}
}
//optimise scale and rotation
Mat C_old;
for(int iter = 0; iter < itol; iter++)
{
/*计算(含n个形状)的重心*/
Mat C = P*Mat::ones(N,1,CV_32F)/N;
/*C为2n*1维矩阵,含n个重心,对n个重心归一化处理*/
normalize(C,C);
if(iter > 0)
{
if(norm(C,C_old) < ftol)//norm:求绝对范数,小于阈值,则退出循环
break;
}
C_old = C.clone();
for(int i = 0; i < N; i++)
{
//求当前形状与归一化重心之间的旋转角度,即上式a和b
Mat R = this->rot_scale_align(P.col(i),C);
for(int j = 0; j < n; j++)
{
float x = P.fl(2*j,i),y = P.fl(2*j+1,i);
/*仿射变化*/
P.fl(2*j ,i) = R.fl(0,0)*x + R.fl(0,1)*y;
P.fl(2*j+1,i) = R.fl(1,0)*x + R.fl(1,1)*y;
}
}
}
return P;
}
3. Linear Shape Model
经过上述归一化过程后,我们得到N个经过对齐的形状。为了建立相应的表情空间,我们首先要剔除刚性成分,然后才能利用该空间里的数据,对人脸表情变化建模,即找到一种参数化表达方式,它能够描述不同人和不同表情的脸部变化。最简单的做法,对脸部几何空间采用线性表达方式,其主要思想如下:
假设一个人脸形状,在2n维空间中有n个脸部特征点,线性建模的目的是寻找一个低维超平面,该超平面将包含所有脸型的特征点(见下图中绿色的点)。这个超平面子空间的维数越低,脸型的表达就更具有兼容性。
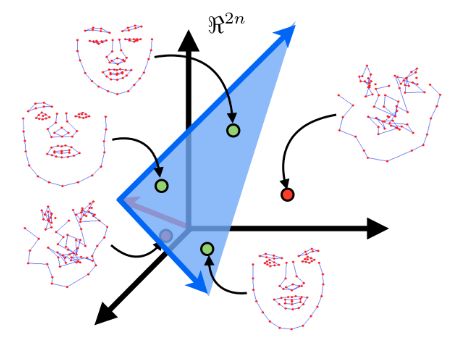
也就是说,经过上述样本点预处理(统计形状分析)后,必然会有大量的数据冗余,在人脸跟踪时会造成不必要的计算开销。因此,这里采用PCA降维技术,在尽可能保留具有显著变化特征数据的基础上,减少样本维数,剔除那些特征变化较小的维度。但是,由于PCA降维时需要提前指定保留子空间的维数,现实中是很难做到的。通常替代做法是根据所选子空间的特征变化占总体空间特征变化的比例来决定。
另外,针对单个个体人脸脸建模,其子空间捕捉的表情变化比大众化人脸建模更具有兼容性,因此针对个体的人脸跟踪比大众化跟踪更精确。
由于样本经过预处理,已经是去中心化的数据,PCA和SVD可以直接对应起来。(SVD与PCA特征的联系,PCA得到的是矩阵Data的特征值,SVD就是矩阵Data*DataT特征值的平方根)【后面老外代码是用SVD去实现的】(SVD和 PCA可以参考我前面的博文:http://blog.csdn.net/jinshengtao/article/details/41387379,
http://blog.csdn.net/jinshengtao/article/details/18599165)
为了提取非刚性成分,我们要从预处理后的形状中剔除刚性成分,为此我们要先求N幅图像对齐后形状空间的标准正交基,然后将每幅图像的原始形状投射到该标准正交空间得到新的形状坐标集合,再用原始图像减去该集合得到非刚性成分。
回顾一下线代基础:

这里的线性无关向量是n=4个,按照如下方式构造:

此处线性无关向量,即为矩阵R的4个列向量。函数:calc_rigid_basis,求对齐后形状空间(表情空间)的施密特标准正交基:
入参:矩阵X,对齐后的形状空间
返回值:矩阵R,n个特征点的标准正交基(R*RT=I)
Mat shape_model::calc_rigid_basis(const Mat &X)
{
//compute mean shape
int N = X.cols,n = X.rows/2;
Mat mean = X*Mat::ones(N,1,CV_32F)/N;
//construct basis for similarity transform
Mat R(2*n,4,CV_32F);
for(int i = 0; i < n; i++)
{
R.fl(2*i,0) = mean.fl(2*i ); R.fl(2*i+1,0) = mean.fl(2*i+1);
R.fl(2*i,1) = -mean.fl(2*i+1); R.fl(2*i+1,1) = mean.fl(2*i );
R.fl(2*i,2) = 1.0; R.fl(2*i+1,2) = 0.0;
R.fl(2*i,3) = 0.0; R.fl(2*i+1,3) = 1.0;
}
//Gram-Schmidt orthonormalization
for(int i = 0; i < 4; i++)
{
Mat r = R.col(i);
for(int j = 0; j < i; j++){
Mat b = R.col(j);
r -= b*(b.t()*r);
}
normalize(r,r);
}
return R;
}
整个非刚性特征提取的实现流程:
//compute rigid transformation, rigid subspace
Mat R = this->calc_rigid_basis(Y);
//compute non-rigid transformation
Mat P = R.t()*Y;
Mat dY = Y - R*P; //project-out rigidity
/*Data = U*w*Vt ,奇异值矩阵为w*/
SVD svd(dY*dY.t());
int m = min(min(kmax,N-1),n-1);
float vsum = 0;
for(int i = 0; i < m; i++)
vsum += svd.w.fl(i);
float v = 0; int k = 0;
for(k = 0; k < m; k++)
{
v += svd.w.fl(k);
if(v/vsum >= frac)
{
k++;
break;
}
} /*取前k个奇异值*/
if(k > m)
k = m;
Mat D = svd.u(Rect(0,0,k,2*n)); /*非刚性变化投影*/
4. A Combined local-globalrepresentation 全局/局部联合表达
经过第3步,我们只是对非刚性空间里的特征点利用SVD降维,得到了非刚性变化的投影矩阵,并没有得到真正的线性模型(Linear model)。我们知道每帧图像中人脸的形状由局部变化和全局变化组成(非刚性和刚性)。从数学角度来讲,二者组合的参数是很难获取的,因为这需要求解高维非线性函数,它的解是非闭合的(个人认为解集是不定的,自变量太多,方程太少)。
替代的解决方案:将二者合并到一个线性空间中,得到Linear Shape Model。
对于一个特定的形状,其相似变换可以按照如下线性子空间[a b tx ty]T建模:
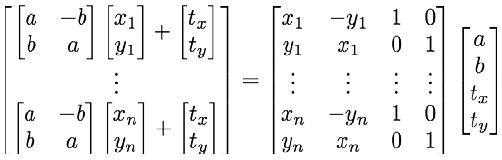
也就是说,联合矩阵可以分成2个分块矩阵,左半边是刚性参数(4列),右半边是非刚性参数(k列)。具体可以看代码注释。
//combine bases V.create(2*n,4+k,CV_32F); Mat Vr = V(Rect(0,0,4,2*n)); R.copyTo(Vr);//rigid subspace Mat Vd = V(Rect(4,0,k,2*n)); D.copyTo(Vd);//nonrigid subspace
上述公式中,a和b是刚性变化的参数,tx和ty是非刚性变化参数,x和y是样本特征点坐标。由于在得到非刚性参数之前,样本特征点就已经去中心化了,因此非刚性子空间正交于刚性子空间。那么将两个子空间串联起来,得到上述脸型的联合线性表达[a b tx ty]T也是正交的。这样,我们就可以非常容易得使用这个正交空间来描述脸型。
![]()
P是人脸形状在联合子空间中的坐标,V是联合变化矩阵,X是2N维空间样本坐标。这样就可以获得联合分布空间的坐标了。
代码分析:
//compute variance (normalized wrt scale)
Mat Q = V.t()*X; //矩阵Q即为联合分布空间中的新坐标集合
for(int i = 0; i < N; i++)
{
/*用Q的第一行元素分别去除对应的0~K+4行元素,归一化新空间的scale,
*防止数据样本(联合分布投影后)的相对尺度过大,影响后面的判断
*/
float v = Q.fl(0,i);
Mat q = Q.col(i);
q /= v;
}
e.create(4+k,1,CV_32F);
/*为了计算方差*/
pow(Q,2,Q);
for(int i = 0; i < 4+k; i++){
if(i < 4)
e.fl(i) = -1; //no clamping for rigid coefficients,矩阵Q的前4列为刚性系数
else
e.fl(i) = Q.row(i).dot(Mat::ones(1,N,CV_32F))/(N-1); //点积,对k列非刚性系数,分别求每幅图像的平均值
}
但是,2N维空间投射到联合分布空间的人脸可能会失真。我们对联合分布空间坐标求标准方差,下面几幅图显示的是联合分布子空间中人脸的形状,并且人脸坐标沿着一个方向以4倍标准方差不断增加。我们注意到对于较小的方差倍数,图形的结果仍然保持人脸的形状,而方差倍数变大时,人脸形状就失真了。(上面代码中矩阵e就存放着方差,老外的意思是人脸失真只能是由非刚性变化导致的)
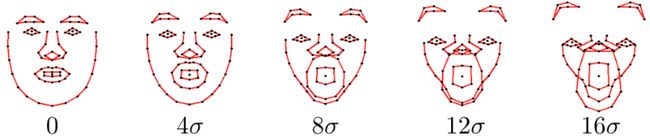
这里,我们选用c(c=3)倍方差为阈值,对于映射后的坐标大于该阈值的,使用clamp函数进行尺寸修正。下面这段代码是在人脸跟踪时使用,这是后话了,下面的代码,本次博文可以忽视。
void shape_model::clamp(const float c) //c*standard deviations box
{
/*p = V.t()*s; simple projection
* p: (k+4)*1维,存放采样点投影到联合分布空间的坐标集合
*/
double scale = p.fl(0);
for(int i = 0; i < e.rows; i++){
if(e.fl(i) < 0)
continue;
float v = c*sqrt(e.fl(i));
if(fabs(p.fl(i)/scale) > v)
{
if(p.fl(i) > 0)
p.fl(i) = v*scale;
else
p.fl(i) = -v*scale;
}
}
}
当完成表情模型的训练后,将shape_model类序列化,以文件形式保存,供后续步骤使用。本次训练入口函数如下,首先载入上次标注的xml数据文件,然后调用train方法训练,获取形状空间参数。
完整的流程:#include "ft.hpp"
#include "ft_data.hpp"
#include "shape_model.hpp"
#include <opencv2/highgui/highgui.hpp>
#include <iostream>
int main(int argc,char** argv)
{
vector<vector<Point2f> > points;
shape_model smodel;
float frac = 0.95;
int kmax = 20;
bool mirror = false;
ft_data data = load_ft<ft_data>("annotations.xml");
if(data.imnames.size() == 0)
{
cerr << "Data file does not contain any annotations."<< endl;
return 0;
}
//remove unlabeled samples and get reflections as well
data.rm_incomplete_samples();
for(int i = 0; i < int(data.points.size()); i++)
{
points.push_back(data.get_points(i,false));
if(mirror)
points.push_back(data.get_points(i,true));
}
//train model and save to file
cout << "shape model training samples: " << points.size() << endl;
smodel.train(points,data.connections,frac,kmax);
cout << "retained: " << smodel.V.cols-4 << " modes" << endl;
save_ft("shape.xml",smodel); //类的序列化
return 0;
}
其中,模型训练函数如下,frac为非刚性空间奇异值的阈值,kmax为非刚性空间保留奇异值的个数。
void
shape_model::
train(const vector<vector<Point2f> > &points,
const vector<Vec2i> &con,
const float frac,
const int kmax)
{
//vectorize points
Mat X = this->pts2mat(points);
int N = X.cols,n = X.rows/2;
//align shapes
Mat Y = this->procrustes(X);
//compute rigid transformation, rigid subspace
Mat R = this->calc_rigid_basis(Y);
//compute non-rigid transformation
Mat P = R.t()*Y;
Mat dY = Y - R*P; //project-out rigidity
/*Data = U*w*Vt ,奇异值矩阵为w*/
SVD svd(dY*dY.t());
int m = min(min(kmax,N-1),n-1);
float vsum = 0;
for(int i = 0; i < m; i++)
vsum += svd.w.fl(i);
float v = 0; int k = 0;
for(k = 0; k < m; k++)
{
v += svd.w.fl(k);
if(v/vsum >= frac)
{
k++;
break;
}
} /*取前k个奇异值*/
if(k > m)
k = m;
Mat D = svd.u(Rect(0,0,k,2*n)); /*非刚性变化投影*/
//combine bases
V.create(2*n,4+k,CV_32F);
Mat Vr = V(Rect(0,0,4,2*n)); R.copyTo(Vr);//rigid subspace
Mat Vd = V(Rect(4,0,k,2*n)); D.copyTo(Vd);//nonrigid subspace
//compute variance (normalized wrt scale)
Mat Q = V.t()*X; //矩阵Q即为联合分布空间中的新坐标集合
for(int i = 0; i < N; i++)
{
/*用Q的第一行元素分别去除对应的0~K+4行元素,归一化新空间的scale,
*防止数据样本(联合分布投影后)的相对尺度过大,影响后面的判断
*/
float v = Q.fl(0,i);
Mat q = Q.col(i);
q /= v;
}
e.create(4+k,1,CV_32F);
/*为了计算方差*/
pow(Q,2,Q);
for(int i = 0; i < 4+k; i++){
if(i < 4)
e.fl(i) = -1; //no clamping for rigid coefficients,矩阵Q的前4列为刚性系数
else
e.fl(i) = Q.row(i).dot(Mat::ones(1,N,CV_32F))/(N-1); //点积,对k列非刚性系数,分别求每幅图像的平均值
}
//store connectivity
if(con.size() > 0){ //default connectivity
int m = con.size();
C.create(m,2,CV_32F);
for(int i = 0; i < m; i++){
C.at<int>(i,0) = con[i][0]; C.at<int>(i,1) = con[i][1];
}
}else{ //user-specified connectivity
C.create(n,2,CV_32S);
for(int i = 0; i < n-1; i++){
C.at<int>(i,0) = i; C.at<int>(i,1) = i+1;
}
C.at<int>(n-1,0) = n-1; C.at<int>(n-1,1) = 0;
}
}
5. 展示训练后的结果
本文程序会在每个非刚性变化方向上(k个表情模型)依次以动画形式表达学习得到的非刚性形变。即根据联合矩阵的非刚性形变参数,在给定2维空间里,还原动画效果。
函数主要流程:
int main(int argc,char** argv)
{
vector<float> val;
Mat img(300,300,CV_8UC3);
shape_model smodel = load_ft<shape_model>("shape.xml");
namedWindow("shape model");
/*为了让动画图像处于窗口的中央,窗口大小300*300像素*/
int n = smodel.V.rows/2; //矩阵V为脸型的刚性和非刚性联合变换矩阵,大小为2n*(k+4),V的第一列为尺度大小,第三、第四列对应x和y方向的变化
float scale = calc_scale(smodel.V.col(0),200);//200为展示的目标大小,返回的scale是缩放比例
float tranx = n*150.0/smodel.V.col(2).dot(Mat::ones(2*n,1,CV_32F));
float trany = n*150.0/smodel.V.col(3).dot(Mat::ones(2*n,1,CV_32F));
/*下面四个循环,生成画图的坐标系(x:-50~50,y:-50~50)*/
for(int i = 0; i < 50; i++)
val.push_back(float(i)/50);
for(int i = 0; i < 50; i++)
val.push_back(float(50-i)/50);
for(int i = 0; i < 50; i++)
val.push_back(-float(i)/50);
for(int i = 0; i < 50; i++)
val.push_back(-float(50-i)/50);
//visualise
while(1)
{
/*按照非刚性变化,展示动画,动画数量供V.cols-3个,不断遍历这个循环*/
for(int k = 4; k < smodel.V.cols; k++)
{
for(int j = 0; j < int(val.size()); j++)
{
Mat p = Mat::zeros(smodel.V.cols,1,CV_32F);
//以下三个参数为固定值,目的就是让图形处于屏幕中央
p.at<float>(0) = scale;
p.at<float>(2) = tranx;
p.at<float>(3) = trany;
p.at<float>(k) = scale*val[j]*3.0*sqrt(smodel.e.at<float>(k)); //根据缩放尺度、坐标系、柔性变化(标准差),还原脸型
p.copyTo(smodel.p);
img = Scalar::all(255);
char str[256];
sprintf(str,"mode: %d, val: %f sd",k-3,val[j]/3.0);
draw_string(img,str);
vector<Point2f> q = smodel.calc_shape();//根据结构体p中的信息,还原图像中的坐标
draw_shape(img,q,smodel.C);
imshow("shape model",img);
if(waitKey(10) == 'q')
return 0;
}
}
}
return 0;
}
感谢上次网友sinat_25264411提供的数据集:http://pan.baidu.com/s/1bn6L2aF,图像样本近4000多个,文本文件都几兆了。我稍微简化处理了下,就以第一个MM为列,挑了个15个图片,文本文件涉及其中9幅图片。完整的3个代码(标注、形状 学习、展示形状)我会上传到CSDN,见留言板。
这里文本文件只包含了标注点,而connection连线和symmetry点需要自己选择,比较累。【其他文本文件,暂时还没看懂用意】

下面为学习到的5个表情模型:





耗时两个礼拜,终于写完这一个section了,华为上班思路又断断续续的,不知道上面胡乱写了啥,算是纯粹的读书笔记吧。
反正,这个section口口声声喊是学习表情形状模型,在我看了就用SVD从N幅图像里挑选了比较特别的k幅图,最终体现也就是两个矩阵:联合分布矩阵V和标准差e,至于后面怎么用它们,后一章节还没读,不确定是不是能继续写下去。
如果回头发现自己前面写错了,也没办法。
我一直做着和工作无关的事情,这半年来图像处理模式识别这块成长几乎是停止的,至多说眼界广一些,很多东西都缺乏自己的思考(这需要时间)
另外,关于华为部门年会抽奖没拿到MATE7 高配,就不吐槽了,过完年就闪人了。