基本的HTML文本解析器的设计和实现(C/C++源码),图文并茂
作者:庄晓立 (liigo)
日期:2011-1-19
原创链接:http://blog.csdn.net/liigo/archive/2011/01/19/6153829.aspx
转载请保持本文完整性,并注明出处:http://blog.csdn.net/liigo
关键字:HTML,解析器(Parser),节点(Node),标签(Tag)
这是进入2011年以来,本人(liigo)“重复发明轮子”系列博文中的最新一篇。本文主要探讨如何设计和实现一个基本的HTML文本解析器。
众所周知,HTML是结构化文档(Structured Document),由诸多标签(<p>等)嵌套形成的著名的文档对象模型(DOM, Document Object Model),是显而易见的树形多层次结构。如果带着这种思路看待HTML、编写HTML解析器,无疑将导致问题复杂化。不妨从另一视角俯视HTML文本,视其为一维线状结构:诸多单一节点的顺序排列。仔细审视任何一段HTML文本,以左右尖括号(<和>)为边界,会发现HTML文本被天然地分割为:一个标签(Tag),接一段普通文字,再一个标签,再一段普通文字…… 如下图所示:
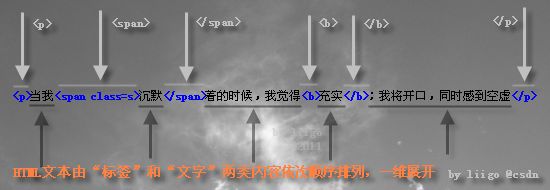
标签有两种,开始标签(如<p>)和结束标签(</p>),它们和普通文字一起,顺序排列,共同构成了HTML文本的全部。
为了再次简化编程模型,我(liigo)继续将“开始标签”“结束标签”“普通文字”三者统一抽象归纳为“节点”(HtmlNode),相应的,“节点”有三种类型,要么是开始标签,要么是结束标签,要么是普通文字。现在,HTML在我们眼里更加单纯了,它就是“节点”的线性顺序组合,是一维的“节点”数组。如下图所示:HTML文本 = 节点1 + 节点2 + 节点3 + ……

在正式编码之前,先确定好“节点”的数据结构。作为“普通文字”节点,需要记录一个文本(text);作为“标签”节点,需要记录标签名称(tagName)、标签类型(tagType)、所有属性值(props);另外还要有个类型(type)以便区分该节点是普通文字、开始标签还是结束标签。这其中固然有些冗余信息,比如对标签来说不需要记录文本,对普通文字来说又不需要记录标签名称、属性值等,不过无伤大雅,简洁的编程模型是最大的诱惑。用C/C++语言语法表示如下:
enum HtmlNodeType { NODE_UNKNOWN = 0, NODE_START_TAG, NODE_CLOSE_TAG, NODE_CONTENT, }; enum HtmlTagType { TAG_UNKNOWN = 0, TAG_A, TAG_DIV, TAG_FONT, TAG_IMG, TAG_P, TAG_SPAN, TAG_BR, TAG_B, TAG_I, TAG_HR, }; struct HtmlNodeProp { WCHAR* szName; WCHAR* szValue; }; #define MAX_HTML_TAG_LENGTH (15) struct HtmlNode { HtmlNodeType type; HtmlTagType tagType; WCHAR tagName[MAX_HTML_TAG_LENGTH+1]; WCHAR* text; int propCount; HtmlNodeProp* props; };
具体到编写程序代码,要比想象中容易的多。编码的核心要点是,以左右尖括号(<和>)为边界自然分割标签和普通文字。左右尖括号之间的当然是标签节点(开始标签或结束标签),左尖括号(<)之前(直到前一个右尖括号或开头)、右尖括号(>)之后(直到后一个左尖括号或结尾)的显然是普通文字节点。区分开始标签或结束标签的关键点是,看左尖括号(<)后面第一个非空白字符是否为'/'。对于开始标签,在标签名称后面,间隔至少一个空白字符,可能会有形式为“key1=value1 key2=value2 key3”的属性表,关于属性表,后文有专门的函数负责解析。此外有一点要注意,属性值一般有引号括住,引号内出现的左右尖括号应该不被视为边界分隔符。
下面就是负责把HTML文本解析为一个个节点(HtmlNode)的核心代码(不足百行,够精简吧):
void HtmlParser::ParseHtml(const WCHAR* szHtml) { m_html = szHtml ? szHtml : L""; freeHtmlNodes(); if(szHtml == NULL || *szHtml == L'/0') return; WCHAR* p = (WCHAR*) szHtml; WCHAR* s = (WCHAR*) szHtml; HtmlNode* pNode = NULL; WCHAR c; bool bInQuotes = false; while( c = *p ) { if(c == L'/"') { bInQuotes = !bInQuotes; p++; continue; } if(bInQuotes) { p++; continue; } if(c == L'<') { if(p > s) { //Add Text Node pNode = NewHtmlNode(); pNode->type = NODE_CONTENT; pNode->text = duplicateStrUtill(s, L'<', true); } s = p + 1; } else if(c == L'>') { if(p > s) { //Add HtmlTag Node pNode = NewHtmlNode(); while(isspace(*s)) s++; pNode->type = (*s != L'/' ? NODE_START_TAG : NODE_CLOSE_TAG); if(*s == L'/') s++; copyStrUtill(pNode->tagName, MAX_HTML_TAG_LENGTH, s, L'>', true); //处理自封闭的结点, 如 <br/>, 删除tagName中可能会有的'/'字符 //自封闭的结点的type设置为NODE_START_TAG应该可以接受(否则要引入新的NODE_STARTCLOSE_TAG) int tagNamelen = wcslen(pNode->tagName); if(pNode->tagName[tagNamelen-1] == L'/') pNode->tagName[tagNamelen-1] = L'/0'; //处理结点属性 for(int i = 0; i < tagNamelen; i++) { if(pNode->tagName[i] == L' ' //第一个空格后面跟的是属性列表 || pNode->tagName[i] == L'=') //扩展支持这种格式: <tagName=value>, 等效于<tagName tagName=value> { WCHAR* props = (pNode->tagName[i] == L' ' ? s + i + 1 : s); pNode->text = duplicateStrUtill(props, L'>', true); int nodeTextLen = wcslen(pNode->text); if(pNode->text[nodeTextLen-1] == L'/') //去掉最后可能会有的'/'字符, 如这种情况: <img src="..." mce_src="..." /> pNode->text[nodeTextLen-1] = L'/0'; pNode->tagName[i] = L'/0'; parseNodeProps(pNode); //parse props break; } } pNode->tagType = getHtmlTagTypeFromName(pNode->tagName); } s = p + 1; } p++; } if(p > s) { //Add Text Node pNode = NewHtmlNode(); pNode->type = NODE_CONTENT; pNode->text = duplicateStr(s, -1); } #ifdef _DEBUG dumpHtmlNodes(); //just for test #endif }
下面是负责解析“开始标签”属性表文本(形如“key1=value1 key2=value2 key3”)的代码,parseNodeProps(),核心思路是按空格和等号字符进行分割属性名和属性值,由于想兼容HTML4.01及以前的不标准的属性表写法(如没有=号也没有属性值),颇费周折:
//[virtual] void HtmlParser::parseNodeProps(HtmlNode* pNode) { if(pNode == NULL || pNode->propCount > 0 || pNode->text == NULL) return; WCHAR* p = pNode->text; WCHAR *ps = NULL; CMem mem; bool inQuote1 = false, inQuote2 = false; WCHAR c; while(c = *p) { if(c == L'/"') { inQuote1 = !inQuote1; } else if(c == L'/'') { inQuote2 = !inQuote2; } if((!inQuote1 && !inQuote2) && (c == L' ' || c == L'/t' || c == L'=')) { if(ps) { mem.AddPointer(duplicateStrAndUnquote(ps, p - ps)); ps = NULL; } if(c == L'=') mem.AddPointer(NULL); } else { if(ps == NULL) ps = p; } p++; } if(ps) mem.AddPointer(duplicateStrAndUnquote(ps, p - ps)); mem.AddPointer(NULL); mem.AddPointer(NULL); WCHAR** pp = (WCHAR**) mem.GetPtr(); CMem props; for(int i = 0, n = mem.GetSize() / sizeof(WCHAR*) - 2; i < n; i++) { props.AddPointer(pp[i]); //prop name if(pp[i+1] == NULL) { props.AddPointer(pp[i+2]); //prop value i += 2; } else props.AddPointer(NULL); //prop vlalue } pNode->propCount = props.GetSize() / sizeof(WCHAR*) / 2; pNode->props = (HtmlNodeProp*) props.Detach(); }
根据标签名称取标签类型的getHtmlTagTypeFromName()方法,就非常直白了,查表,逐一识别:
//[virtual] HtmlTagType HtmlParser::getHtmlTagTypeFromName(const WCHAR* szTagName) { //todo: uses hashmap struct N2T { const WCHAR* name; HtmlTagType type; }; static N2T n2tTable[] = { { L"A", TAG_A }, { L"FONT", TAG_FONT }, { L"IMG", TAG_IMG }, { L"P", TAG_P }, { L"DIV", TAG_DIV }, { L"SPAN", TAG_SPAN }, { L"BR", TAG_BR }, { L"B", TAG_B }, { L"I", TAG_I }, { L"HR", TAG_HR }, }; for(int i = 0, count = sizeof(n2tTable)/sizeof(n2tTable[0]); i < count; i++) { N2T* p = &n2tTable[i]; if(wcsicmp(p->name, szTagName) == 0) return p->type; } return TAG_UNKNOWN; }
请注意,上文负责解析属性表的parseNodeProps()函数,和负责识别标签名称的getHtmlTagTypeFromName()函数,都是虚函数(virtual method)。我(liigo)这么设计是有深意的,给使用者留下了很大的定制空间,可以自由发挥。例如,通过在子类中覆盖/覆写(override)parseNodeProps()方法,可以采用更好的解析算法,或者干脆不做任何处理以提高HTML解析效率——将来某一时间可以调用基类同名函数专门解析特定标签的属性表;例如,通过在子类中覆盖/覆写(override)getHtmlTagTypeFromName()方法,使用者可以选择识别跟多的标签名称(包括自定义标签),或者识别更少的标签名称,甚至不识别任何标签名称(以便提高解析效率)。以编写网络爬虫程序为实例,它多数情况下通常只需识别<A>标签及其属性就足够了,没必要浪费CPU运算去识别其它标签、解析其他标签属性。
至于HTML文本解析器的用途,我目前想到的有:用于HTML格式检查或规范化,用于重新排版HTML文本,用于编写网络爬虫程序/搜索引擎,用于基于HTML模板的动态网页生成,用于HTML网页渲染前的基础解析,等等。
下面附上完整源码,仅供参考,欢迎指正。
HtmlParser.h:
#include "common.h" //HtmlParser类,用于解析HTML文本 //by liigo, @2010 enum HtmlNodeType { NODE_UNKNOWN = 0, NODE_START_TAG, NODE_CLOSE_TAG, NODE_CONTENT, NODE_SOFT_LINE, }; enum HtmlTagType { TAG_UNKNOWN = 0, TAG_A, TAG_DIV, TAG_FONT, TAG_IMG, TAG_P, TAG_SPAN, TAG_BR, TAG_B, TAG_I, TAG_HR, TAG_COLOR, TAG_BGCOLOR, //非标准HTML标签, 可以这样使用: <color=red>, 等效于 <color color=red> }; struct HtmlNodeProp { WCHAR* szName; WCHAR* szValue; }; #define MAX_HTML_TAG_LENGTH (15) struct HtmlNode { HtmlNodeType type; HtmlTagType tagType; WCHAR tagName[MAX_HTML_TAG_LENGTH+1]; WCHAR* text; int propCount; HtmlNodeProp* props; }; class HtmlParser { friend class HTMLView; public: HtmlParser() {} public: //html void ParseHtml(const WCHAR* szHtml); const WCHAR* GetHtml() const { return m_html.GetText(); } //nodes unsigned int getHtmlNodeCount(); HtmlNode* getHtmlNodes(); //props const HtmlNodeProp* getNodeProp(const HtmlNode* pNode, const WCHAR* szPropName); const WCHAR* getNodePropStringValue(const HtmlNode* pNode, const WCHAR* szPropName, const WCHAR* szDefaultValue = NULL); int getNodePropIntValue(const HtmlNode* pNode, const WCHAR* szPropName, int defaultValue = 0); protected: //允许子类覆盖, 以便识别更多结点(提高解析质量), 或者识别更少结点(提高解析速度) virtual HtmlTagType getHtmlTagTypeFromName(const WCHAR* szTagName); public: //允许子类覆盖, 以便更好的解析节点属性, 或者干脆不解析节点属性(提高解析速度) virtual void parseNodeProps(HtmlNode* pNode); //todo: make protected, after testing private: HtmlNode* NewHtmlNode(); void freeHtmlNodes(); void dumpHtmlNodes(); private: CMem m_HtmlNodes; CMString m_html; }; //一些文本处理函数 WCHAR* duplicateStr(const WCHAR* pSrc, unsigned int nChar); void freeDuplicatedStr(WCHAR* p); unsigned int copyStr(WCHAR* pDest, unsigned int nDest, const WCHAR* pSrc, unsigned int nChar);
HtmlParser.cpp:
#include "HtmlParser.h" //HtmlParser类,用于解析HTML文本 //by liigo, @2010 const WCHAR* wcsnchr(const WCHAR* pStr, int len, WCHAR c) { const WCHAR *p = pStr; while(1) { if(*p == c) return p; p++; if((p - pStr) == len) break; } return NULL; } const WCHAR* getFirstUnquotedChar(const WCHAR* pStr, WCHAR endcahr) { WCHAR c; const WCHAR* p = pStr; bool inQuote1 = false, inQuote2 = false; //'inQuote1', "inQuote2" while(c = *p) { if(c == L'/'') { inQuote1 = !inQuote1; } else if(c == L'/"') { inQuote2 = !inQuote2; } if(!inQuote1 && !inQuote2) { if(c == endcahr) return p; } p++; } return NULL; } //nDest and nChar can by -1 unsigned int copyStr(WCHAR* pDest, unsigned int nDest, const WCHAR* pSrc, unsigned int nChar) { if(pDest == NULL || nDest == 0) return 0; if(pSrc == NULL) { pDest[0] = L'/0'; return 0; } if(nChar == (unsigned int)-1) nChar = wcslen(pSrc); if(nChar > nDest) nChar = nDest; memcpy(pDest, pSrc, nChar * sizeof(WCHAR)); pDest[nChar] = L'/0'; return nChar; } int copyStrUtill(WCHAR* pDest, unsigned int nDest, const WCHAR* pSrc, WCHAR endchar, bool ignoreEndCharInQuoted) { if(nDest == 0) return 0; pDest[0] = L'/0'; const WCHAR* pSearched = (ignoreEndCharInQuoted ? getFirstUnquotedChar(pSrc,endchar) : wcschr(pSrc, endchar)); if(pSearched <= pSrc) return 0; return copyStr(pDest, nDest, pSrc, pSearched - pSrc); } //nChar can be -1 WCHAR* duplicateStr(const WCHAR* pSrc, unsigned int nChar) { if(nChar == (unsigned int)-1) nChar = wcslen(pSrc); WCHAR* pNew = (WCHAR*) malloc( (nChar+1) * sizeof(WCHAR) ); copyStr(pNew, -1, pSrc, nChar); return pNew; } WCHAR* duplicateStrUtill(const WCHAR* pSrc, WCHAR endchar, bool ignoreEndCharInQuoted) { const WCHAR* pSearched = (ignoreEndCharInQuoted ? getFirstUnquotedChar(pSrc,endchar) : wcschr(pSrc, endchar));; if(pSearched <= pSrc) return NULL; int n = pSearched - pSrc; return duplicateStr(pSrc, n); } void freeDuplicatedStr(WCHAR* p) { if(p) free(p); } HtmlNode* HtmlParser::NewHtmlNode() { static char staticHtmlNodeTemplate[sizeof(HtmlNode)] = {0}; /* static HtmlNode staticHtmlNodeTemplate; //= {0}; staticHtmlNodeTemplate.type = NODE_UNKNOWN; staticHtmlNodeTemplate.tagName[0] = L'/0'; staticHtmlNodeTemplate.text = NULL; */ m_HtmlNodes.Append(staticHtmlNodeTemplate, sizeof(HtmlNode)); HtmlNode* pNode = (HtmlNode*) (m_HtmlNodes.GetPtr() + m_HtmlNodes.GetSize() - sizeof(HtmlNode)); return pNode; } void HtmlParser::ParseHtml(const WCHAR* szHtml) { m_html = szHtml ? szHtml : L""; freeHtmlNodes(); if(szHtml == NULL || *szHtml == L'/0') return; WCHAR* p = (WCHAR*) szHtml; WCHAR* s = (WCHAR*) szHtml; HtmlNode* pNode = NULL; WCHAR c; bool bInQuotes = false; while( c = *p ) { if(c == L'/"') { bInQuotes = !bInQuotes; p++; continue; } if(bInQuotes) { p++; continue; } if(c == L'<') { if(p > s) { //Add Text Node pNode = NewHtmlNode(); pNode->type = NODE_CONTENT; pNode->text = duplicateStrUtill(s, L'<', true); } s = p + 1; } else if(c == L'>') { if(p > s) { //Add HtmlTag Node pNode = NewHtmlNode(); while(isspace(*s)) s++; pNode->type = (*s != L'/' ? NODE_START_TAG : NODE_CLOSE_TAG); if(*s == L'/') s++; copyStrUtill(pNode->tagName, MAX_HTML_TAG_LENGTH, s, L'>', true); //处理自封闭的结点, 如 <br/>, 删除tagName中可能会有的'/'字符 //自封闭的结点的type设置为NODE_START_TAG应该可以接受(否则要引入新的NODE_STARTCLOSE_TAG) int tagNamelen = wcslen(pNode->tagName); if(pNode->tagName[tagNamelen-1] == L'/') pNode->tagName[tagNamelen-1] = L'/0'; //处理结点属性 for(int i = 0; i < tagNamelen; i++) { if(pNode->tagName[i] == L' ' //第一个空格后面跟的是属性列表 || pNode->tagName[i] == L'=') //扩展支持这种格式: <tagName=value>, 等效于<tagName tagName=value> { WCHAR* props = (pNode->tagName[i] == L' ' ? s + i + 1 : s); pNode->text = duplicateStrUtill(props, L'>', true); int nodeTextLen = wcslen(pNode->text); if(pNode->text[nodeTextLen-1] == L'/') //去掉最后可能会有的'/'字符, 如这种情况: <img src="..." mce_src="..." /> pNode->text[nodeTextLen-1] = L'/0'; pNode->tagName[i] = L'/0'; parseNodeProps(pNode); //parse props break; } } pNode->tagType = getHtmlTagTypeFromName(pNode->tagName); } s = p + 1; } p++; } if(p > s) { //Add Text Node pNode = NewHtmlNode(); pNode->type = NODE_CONTENT; pNode->text = duplicateStr(s, -1); } #ifdef _DEBUG dumpHtmlNodes(); //just for test #endif } unsigned int HtmlParser::getHtmlNodeCount() { return (m_HtmlNodes.GetSize() / sizeof(HtmlNode)); } HtmlNode* HtmlParser::getHtmlNodes() { return (HtmlNode*) m_HtmlNodes.GetPtr(); } void HtmlParser::freeHtmlNodes() { HtmlNode* pNodes = getHtmlNodes(); for(int i = 0, count = getHtmlNodeCount(); i < count; i++) { HtmlNode* pNode = pNodes + i; if(pNode->text) freeDuplicatedStr(pNode->text); if(pNode->props) MFreeMemory(pNode->props); //see: CMem::Alloc } m_HtmlNodes.Empty(); } //[virtual] HtmlTagType HtmlParser::getHtmlTagTypeFromName(const WCHAR* szTagName) { //todo: uses hashmap struct N2T { const WCHAR* name; HtmlTagType type; }; static N2T n2tTable[] = { { L"A", TAG_A }, { L"FONT", TAG_FONT }, { L"IMG", TAG_IMG }, { L"P", TAG_P }, { L"DIV", TAG_DIV }, { L"SPAN", TAG_SPAN }, { L"BR", TAG_BR }, { L"B", TAG_B }, { L"I", TAG_I }, { L"HR", TAG_HR }, { L"COLOR", TAG_COLOR }, { L"BGCOLOR", TAG_BGCOLOR }, }; for(int i = 0, count = sizeof(n2tTable)/sizeof(n2tTable[0]); i < count; i++) { N2T* p = &n2tTable[i]; if(wcsicmp(p->name, szTagName) == 0) return p->type; } return TAG_UNKNOWN; } void skipSpaceChars(WCHAR*& p) { if(p) { while(isspace(*p)) p++; } } const WCHAR* nextUnqotedSpaceChar(const WCHAR* p) { const WCHAR* r = getFirstUnquotedChar(p, L' '); if(!r) r = getFirstUnquotedChar(p, L'/t'); return r; } const WCHAR* duplicateStrAndUnquote(const WCHAR* str, unsigned int nChar) { if( nChar > 1 && (str[0] == L'/"' && str[nChar-1] == L'/"') || (str[0] == L'/'' && str[nChar-1] == L'/'') ) { str++; nChar-=2; } return duplicateStr(str, nChar); } //[virtual] void HtmlParser::parseNodeProps(HtmlNode* pNode) { if(pNode == NULL || pNode->propCount > 0 || pNode->text == NULL) return; WCHAR* p = pNode->text; WCHAR *ps = NULL; CMem mem; bool inQuote1 = false, inQuote2 = false; WCHAR c; while(c = *p) { if(c == L'/"') { inQuote1 = !inQuote1; } else if(c == L'/'') { inQuote2 = !inQuote2; } if((!inQuote1 && !inQuote2) && (c == L' ' || c == L'/t' || c == L'=')) { if(ps) { mem.AddPointer(duplicateStrAndUnquote(ps, p - ps)); ps = NULL; } if(c == L'=') mem.AddPointer(NULL); } else { if(ps == NULL) ps = p; } p++; } if(ps) mem.AddPointer(duplicateStrAndUnquote(ps, p - ps)); mem.AddPointer(NULL); mem.AddPointer(NULL); WCHAR** pp = (WCHAR**) mem.GetPtr(); CMem props; for(int i = 0, n = mem.GetSize() / sizeof(WCHAR*) - 2; i < n; i++) { props.AddPointer(pp[i]); //prop name if(pp[i+1] == NULL) { props.AddPointer(pp[i+2]); //prop value i += 2; } else props.AddPointer(NULL); //prop vlalue } pNode->propCount = props.GetSize() / sizeof(WCHAR*) / 2; pNode->props = (HtmlNodeProp*) props.Detach(); } const HtmlNodeProp* HtmlParser::getNodeProp(const HtmlNode* pNode, const WCHAR* szPropName) { if(pNode == NULL || pNode->propCount <= 0) return NULL; for(int i = 0; i < pNode->propCount; i++) { HtmlNodeProp* prop = pNode->props + i; if(wcsicmp(prop->szName, szPropName) == 0) return prop; } return NULL; } const WCHAR* HtmlParser::getNodePropStringValue(const HtmlNode* pNode, const WCHAR* szPropName, const WCHAR* szDefaultValue /*= NULL*/) { const HtmlNodeProp* pProp = getNodeProp(pNode, szPropName); if(pProp) return pProp->szValue; else return szDefaultValue; } int HtmlParser::getNodePropIntValue(const HtmlNode* pNode, const WCHAR* szPropName, int defaultValue /*= 0*/) { const HtmlNodeProp* pProp = getNodeProp(pNode, szPropName); if(pProp && pProp->szValue) return _wtoi(pProp->szValue); else return defaultValue; } void HtmlParser::dumpHtmlNodes() { #ifdef _DEBUG HtmlNode* pNodes = getHtmlNodes(); WCHAR buffer[256]; OutputDebugString(L"/n-------- dumpHtmlNodes --------/n"); for(int i = 0, count = getHtmlNodeCount(); i < count; i++) { HtmlNode* pNode = pNodes + i; switch(pNode->type) { case NODE_CONTENT: wsprintf(buffer, L"%2d) type: NODE_CONTENT, text: %s", i, pNode->text); break; case NODE_START_TAG: wsprintf(buffer, L"%2d) type: NODE_START_TAG, tagName: %s (%d), text: %s", i, pNode->tagName, pNode->tagType, pNode->text); break; case NODE_CLOSE_TAG: wsprintf(buffer, L"%2d) type: NODE_CLOSE_TAG, tagName: %s", i, pNode->tagName); break; case NODE_UNKNOWN: default: wsprintf(buffer, L"%2d) type: NODE_UNKNOWN", i); break; } OutputDebugString(buffer); OutputDebugString(L"/n"); if(pNode->propCount > 0) { OutputDebugString(L" props: "); for(int i = 0; i < pNode->propCount; i++) { HtmlNodeProp* prop = pNode->props + i; if(prop->szValue) wsprintf(buffer, L"%s = %s", prop->szName, prop->szValue); else wsprintf(buffer, L"%s", prop->szName); OutputDebugString(buffer); if(i < pNode->propCount - 1) { OutputDebugString(L", "); } } OutputDebugString(L"/n"); } } OutputDebugString(L"-------- end of dumpHtmlNodes --------/n"); #endif } //just for test class TestHtmlParser { public: TestHtmlParser() { HANDLE CMem_GetProcessHeap(); CMem_GetProcessHeap(); HtmlParser htmlParser; HtmlNode node; node.text = L" a=1 b c=/'x y=0/' d = abc "; htmlParser.parseNodeProps(&node); htmlParser.ParseHtml(L"...<p>---<a href="url" mce_href="url">link</a>..."); htmlParser.ParseHtml(L"<p>---< a href=url >link</a>"); htmlParser.ParseHtml(L"<p x=a y=b z = /"c <a href="url" mce_href="url">/" >"); } }; TestHtmlParser testHtmlParser;
全文完,谢谢。
2011-1-22 liigo 补记:本文所提供的源代码,目前有未完善之处,如没有考虑到内嵌JavaScrip代码和HTML注释中的特殊字符(特别是尖括号)对解析器的影响,另外还可能有其他疏漏和bug,故代码仅可用于学习参考研究使用。我今后也将继续改进此HTML语法解析器。特此声明。
2012-5-5 liigo 补记:在刚刚过去的半个多月里,我又对此HTML解析器做了很多改进(并将持续改进),目前应该说是比较成熟和完善了。源代码已经放到GitHub: https://github.com/liigo/html-parser 。另外,本文嵌入的代码已经很旧了(且其中C/C++转义字符被CSDN博客系统粗暴替换),但主要的设计和实现思路依然有效。我也有计划新写一篇本文的2.0版。