August 11, 2004
Despite the lack of vendor support, Representational State Transfer (REST) web services have won the hearts of many working developers. For example, Amazon's web services have both SOAP and REST interfaces, and 85% of the usage is on the REST interface. Compared with other styles of web services, REST is easy to implement and has many highly desirable architectural properties: scalability, performance, security, reliability, and extensibility. Those characteristics fit nicely with the modern business environment, which commands technical solutions just as adoptive and agile as the business itself.
A few short years ago, REST had a much lower profile than XML-RPC, which was much in fashion. Now XML-RPC seems to have less mindshare. People have made significant efforts to RESTize SOAP and WSDL. The question is no longer whether to REST, but instead it's become how to be the best REST?
The purpose of this article is to summarize some best practices and guidelines for implementing RESTful web services. I also propose a number of informal standards in the hope that REST implementations can become more consistent and interoperable.
The following notations are used in this article:
- BP: best practice
- G: general guideline
- PS: proposed informal standard
- TIP: implementation tip
- AR: arguably RESTful -- may not be RESTful in the strict sense
Reprising REST
Let's briefly reiterate the REST web services architecture. REST web services architecture conforms to the W3C's Web Architecture, and leverages the architectural principles of the Web, building its strength on the proven infrastructure of the Web. It utilizes the semantics of HTTP whenever possible and most of the principles, constraints, and best practices published by the TAG also apply.
The REST web services architecture is related to the Service Oriented Architecture. This limits the interface to HTTP with the four well-defined verbs: GET, POST, PUT, and DELETE. REST web services also tend to use XML as the main messaging format.
[G] Implementing REST correctly requires a resource-oriented view of the world instead of the object-oriented views many developers are familiar with.
Resource
One of the most important concepts of web architecture is a "resource." A resource is an abstract thing identified by a URI. A REST service is a resource. A service provider is an implementation of a service.
URI Opacity [BP]
The creator of a URI decides the encoding of the URI, and users should not derive metadata from the URI itself. URI opacity only applies to the path of a URI. The query string and fragment have special meaning that can be understood by users. There must be a shared vocabulary between a service and its consumers.
Query String Extensibility [BP, AR]
A service provider should ignore any query parameters it does not understand during processing. If it needs to consume other services, it should pass all ignored parameters along. This practice allows new functionality to be added without breaking existing services.
[TIP] XML Schema provides a good framework for defining simple types, which can be used for validating query parameters.
Deliver Correct Resource Representation [G]
A resource may have more than one representation. There are four frequently used ways of delivering the correct resource representation to consumers:
- Server-driven negotiation. The service provider determines the right representation from prior knowledge of its clients or uses the information provided in HTTP headers like Accept, Accept-Charset, Accept-Encoding, Accept-Language, and User-Agent. The drawback of this approach is that the server may not have the best knowledge about what a client really wants.
- Client-driven negotiation. A client initiates a request to a server. The server returns a list of available of representations. The client then selects the representation it wants and sends a second request to the server. The drawback is that a client needs to send two requests.
- Proxy-driven negotiation. A client initiates a request to a server through a proxy. The proxy passes the request to the server and obtains a list of representations. The proxy selects one representation according to preferences set by the client and returns the representation back to the client.
- URI-specified representation. A client specifies the representation it wants in the URI query string.
Server-Driven Negotiation [BP]
- When delivering a representation to its client, a server MUST check the following HTTP headers: Accept, Accept-Charset, Accept-Encoding, Accept-Language, and User-Agent to ensure the representation it sends satisfies the user agent's capability.
- When consuming a service, a client should set the value of the following HTTP headers: Accept, Accept-Charset, Accept-Encoding, Accept-Language, and User-Agent. It should be specific about the type of representation it wants and avoid "*/*", unless the intention is to retrieve a list of all possible representations.
- A server may determine the type of representation to send from the profile information of the client.
URI-Specified Representation [PS, AR]
A client can specify the representation using the following query string:
mimeType={mime-type}A REST server should support this query.
Different Views of a Resource [PS, AR]
A resource may have different views, even if there is only one representation available. For example, a resource has an XML representation but different clients may only see different portion of the same XML. Another common example is that a client might want to obtain metadata of the current representation.
To obtain a different view, a client can set a "view" parameter in the URI query string. For example:
GET http://www.example.com/abc?view=metawhere the value of the "view" parameter determines the actual view. Although the value of "view" is application specific in most cases, this guideline reserves the following words:
- "
meta," for obtaining the metadata view of the resource or representation. - "
status," for obtaining the status of a request/transaction resource.
Service
A service represents a specialized business function. A service is safe if it does not incur any obligations from its invoking client, even if this service may cause a change of state on the server side. A service is obligated if the client is held responsible for the change of states on server side.
Safe Service
A safe service should be invoked by the GET method of HTTP. Parameters needed to invoke the service can be embedded in the query string of a URI. The main purpose of a safe service is to obtain a representation of a resource.
Service Provider Responsibility [BP]
If there is more than one representation available for a resource, the service should negotiate with the client as discussed above. When returning a representation, a service provider should set the HTTP headers that relate to caching policies for better performance.
A safe service is by its nature idempotent. A service provider should not break this constraint. Clients should expect to receive consistent representations.
Obligated Services [BP]
Obligated services should be implemented using POST. A request to an obligated service should be described by some kind of XML instance, which should be constrained by a schema. The schema should be written in W3C XML Schema or Relax NG. An obligated service should be made idempotent so that if a client is unsure about the state of its request, it can send it again. This allows low-cost error recovery. An obligated service usually has the simple semantic of "process this" and has two potential impacts: either the creation of new resources or the creation of a new representation of a resource.
Asynchronous Services
One often hears the criticism that HTTP is synchronous, while many services need to be asynchronous. It is actually quite easy to implement an asynchronous REST service. An asynchronous service needs to perform the following:
- Return a receipt immediately upon receiving a request.
- Validate the request.
- If the request if valid, the service must act on the request as soon as possible. It must report an error if the service cannot process the request after a period of time defined in the service contract.
Request Receipt
An example receipt is shown below:
<receipt xmlns="http://www.xml.org/2004/rest/receipt" requestUri = "http://www.example.com/xya343343" received = "2004-10-03T12:34:33+10:00">
<transaction uri="http://www.example.com/xyz2343" status = "http://www.example.com/xyz2343?view=status"/>
</receipt>
A receipt is a confirmation that the server has received a request from a client and promises to act on the request as soon as possible. The receipt element should include a received attribute, the value of which is the time the server received the request in WXS dateTime type format. The requestUri attribute is optional. A service may optionally create a request resource identified by the requestUri. The request resource has a representation, which is equivalent to the request content the server receives. A client may use this URI to inspect the actual request content as received by the server. Both client and server may use this URI for future reference.
However, this is application-specific. A request may initiate more than one transaction. Each transaction element must have a URI attribute which identifies this transaction. A server should also create a transaction resource identified by the URI value. The transaction element must have a status attribute whose value is a URI pointing to a status resource. The status resource must have an XML representation, which indicates the status of the transaction.
Transaction
A transaction represents an atomic unit of work done by a server. The goal of a transaction is to complete the work successfully or return to the original state if an error occurs. For example, a transaction in a purchase order service should either place the order successfully or not place the order at all, in which case the client incurs no obligation.
Status URI [BP, AR]
The status resource can be seen as a different view of its associated transaction resource. The status URI should only differ in the query string with an additional status parameter. For example:
Transaction URI: http://www.example.com/xyz2343 Transaction Status URI: http://www.example.com/xyz2343?view=status
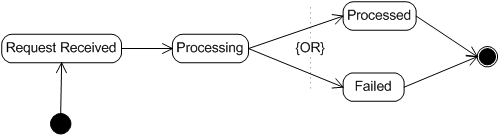
Transaction Lifecycle [G]
A transaction request submitted to a service will experience the following lifecycle as defined in Web Service Management: Service Life Cycle:
- Start -- the transaction is created. This is triggered by the arrival of a request.
- Received -- the transaction has been received. This status is reached when a request is persisted and the server is committed to fulfill the request.
- Processing -- the transaction is being processed, that is, the server has committed resources to process the request.
- Processed -- processing is successfully finished. This status is reached when all processing has completed without any errors.
- Failed -- processing is terminated due to errors. The error is usually caused by invalid submission. A client may rectify its submission and resubmit. If the error is caused by system faults, logging messages should be included. An error can also be caused by internal server malfunction.
- Final -- the request and its associated resources may be removed from the server. An implementation may choose not to remove those resources. This state is triggered when all results are persisted correctly.
Note that it is implementation-dependent as to what operations must be performed on the request itself in order to transition it from one status to another. The state diagram of a request (taken from Web Service Management: Service Life Cycle) is shown below:
 |
As an example of the status XML, when a request is just received:
<status state="received" timestamp="2004-10-03T12:34:33+10:00" />
The XML contains a state attribute, which indicates the current state of the request. Other possible values of the state attribute are processing, processed, and failed.
When a request is processed, the status XML is (non-normative):
<status state="processed" timestamp="2004-10-03T12:34:33+10:00" >
<result uri="http://example.com/rest/1123/xyz" />
</status>
This time, a result element is included and it points to a URL where the client can GET request results.
In case a request fails, the status XML is (non-normative):
<status state="failed" timestamp="2002-10-03T12:34:33+10:00" >
<error code="3" >
<message>A bad request. </message>
<exception>line 3234</exception>
</error>
</status>A client application can display the message enclosed within the message tag. It should ignore all other information. If a client believes that the error was not caused by its fault, this XML may serve as a proof. All other information is for internal debugging purposes.
Request Result [BP]
A request result view should be regarded as a special view of a transaction. One may create a request resource and transaction resources whenever a request is received. The result should use XML markup that is as closely related to the original request markup as possible.
Receiving and Sending XML [BP]
When receiving and sending XML, one should follow the principle of "strict out and loose in." When sending XML, one must ensure it is validated against the relevant schema. When receiving an XML document, one should only validate the XML against the smallest set of schema that is really needed. Any software agent must not change XML it does not understand.
An Implementation Architecture
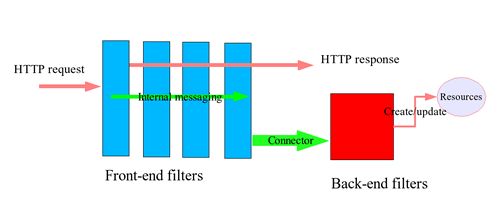 |
The architecture represented above has a pipe-and-filter style, a classical and robust architectural style used as early as in 1944 by the famous physicist, Richard Feynman, to build the first atomic bomb in his computing team. A request is processed by a chain of filters and each filter is responsible for a well-defined unit of work. Those filters are further classified as two distinct groups: front-end and back-end. Front-end filters are responsible to handle common Web service tasks and they must be light weight. Before or at the end of front-end filters, a response is returned to the invoking client.
All front-end filters must be lightweight and must not cause serious resource drain on the host. A common filter is a bouncer filter, which checks the eligibility of the request using some simple techniques:
- IP filtering. Only requests from eligible IPs are allowed.
- URL mapping. Only certain URL patterns are allowed.
- Time-based filtering. A client can only send a certain number of requests per second.
- Cookie-based filtering. A client must have a cookie to be able to access this service.
- Duplication-detection filter. This filter checks the content of a request and determines whether it has received it before. A simple technique is based on the hash value of the received message. However, a more sophisticated technique involves normalizing the contents using an application-specific algorithm.
A connector, whose purpose is to decouple the time dependency between front-end filters and back-end filters, connects front-end filters and back-end filters. If back-end processing is lightweight, the connector serves mainly as a delegator, which delegates requests to its corresponding back-end processors. If back-end processing is heavy, the connector is normally implemented as a queue.
Back-end filters are usually more application specific or heavy. They should not respond directly to requests but create or update resources.
This architecture is known to have many good properties, as observed by Feynman, whose team improved its productivity many times over. Most notably, the filters can be considered as a standard form of computing and new filters can be added or extended from existing ones easily. This architecture has good user-perceived performance because responses are returned as soon as possible once a request becomes fully processed by lightweight filters. This architecture also has good security and stability because security breakage and errors can only propagate a limited number of filters. However, it is important to note that one must not put a heavyweight filter in the front-end or the system may become vulnerable to denial-of-service attacks.