mongodb运维之副本集实践
正式环境,
4台机器+一台定时任务的机器。
服务器是阿里云的ECS,
负载均衡用的是阿里云的SLB,
mysql用阿里云的RDS,
缓存用阿里云的OCS,
运维基本上是都不需要担心了,
现在的云服务已经非常完善了,
其实我们用阿里云的服务非常多,
大概有20多个类型的服务,
感谢阿里云。 而我的技术栈是nodejs + mongodb,而阿里云有k-v兼容redis协议的nosql,无mongodb,所以就要悲剧的自己运维mongodb了。
阿里的ots是非结构化存储,没有nodejs的sdk,就算有,不兼容mongodb,也没啥可玩的。
云服务
MongoDB存储服务的云平台(MongoHQ, MongoLabs 和 Mongo Machine)
国内的貌似只有 http://developer.baidu.com/wiki/index.php?title=docs/cplat/bae/mongodb
芋头推荐用pg,支持json格式存储
还有就是parse和leancloud这类面向api的。
京东和腾讯都有过,后来关闭了,不知何故
mongodb部署最佳实践
常识: replset + shard
replset是副本集,shard是分片
mongoDB的主从模式其实就是一个单副本的应用,没有很好的扩展性和容错性。而副本集具有多个副本保证了容错性,就算一个副本挂掉了还有很多副本存在,并且解决了上面第一个问题“主节点挂掉了,整个集群内会自动切换”。
比如游戏,开了某一个服,那么所有的数据都在一台服务器上,此时它要保证的是服务不挂就可以,不用考虑更多的并发上的压力,那么它首先是副本集。
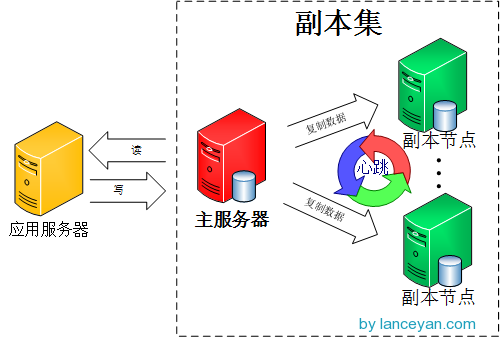
如果有节点挂了,它会重新选举新的主节点
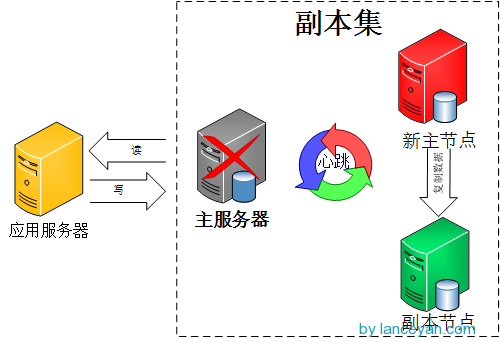
而更多的情况是,你要考虑并发,而且可能是千万,亿万并发,副本集是搞不定的。
于是shard就登场了。
分片并不是mongo独有的概念,很多数据库都有,mongodb里的分片是指通过mongos来当网关路由,分发请求到每个shard,然后每个shard会对应各自的副本集。
既然是分发请求,就会有一定的性能损耗,但好处是你能处理更多请求。所以按照场景选择
- 性能最佳,当然是一个副本集,如果能满足需求,优先
- 如果副本集不足及支撑并发,那么就选shard
准备3台阿里云主机
- 10.51.83.118
- 10.51.77.129
- 10.44.204.241
先各自ping一下,保证网络通畅。
确定我的目标是1主,2从,奇数个
这篇文字讲了Bully算法以及为啥是奇数个
http://www.lanceyan.com/tech/mongodb_repset2.html
注意点
- 服务器节点之前时间要同步
- 开启防火墙的一定要允许通过
- 开启selinux的也要进行设置
- 建立双击互信模式最好不过
格式化阿里云的新增硬盘
http://www.cnblogs.com/dudu/archive/2012/12/07/aliyun-linux-fdisk.html
然后挂载到/data目录下
配置文件
~/config/r0.config
port=27000
fork=true
logpath=/data/replset/log/r0.log
dbpath=/data/replset/r0
logappend=true
replSet=rs
#keyFile=/data/replset/key/r0 ~/config/r1.config
port=27001
fork=true
logpath=/data/replset/log/r1.log
dbpath=/data/replset/r1
logappend=true
replSet=rs
#keyFile=/data/replset/key/r1 ~/config/r2.config
port=27002
fork=true
logpath=/data/replset/log/r2.log
dbpath=/data/replset/r2
logappend=true replSet=rs
#keyFile=/data/replset/key/r2 启动
确保目录为空,杀死所有mongod进程
rm -rf /data/replset/
ps -ef|grep mongod | awk '{print $2}' | xargs kill -9
ps -ef|grep mongod 创建目录
mkdir -p /data/replset/r0
mkdir -p /data/replset/r1
mkdir -p /data/replset/r2
mkdir -p /data/replset/key
mkdir -p /data/replset/log 准备key文件
echo "replset1 key" > /data/replset/key/r0
echo "replset1 key" > /data/replset/key/r1
echo "replset1 key" > /data/replset/key/r2
chmod 600 /data/replset/key/r* 注意第一次不能用keyFile
mongod -f ~/config/r0.config &
mongod -f ~/config/r1.config &
mongod -f ~/config/r2.config & 配置文件里是fork=true,所以启动需要点时间
初始化
> rs.initiate()
{
"info2" : "no configuration explicitly specified -- making one",
"me" : "iZ25xk7uei1Z:27001",
"ok" : 1
} 擦,超级慢。。。。
使用下面语句初始化
mongo --port 27000
rs.initiate({ _id:'rs',members:[{ _id:0, host:'10.51.77.129:27000' }]}) 这个其实也很慢。。。。
待完成后,继续增加其他2个节点(一定要注意,在rs:PRIMARY即主节点上才能增加rs:SECONDARY和ARBITER。如果之前连的是其他端口,需要切换的。)
rs.add("10.51.77.129:27001")
rs.addArb("10.51.77.129:27002") 查看状态
rs.status(); 如果想移除某一个节点
rs.remove("10.51.77.129:27001")
rs.remove("10.51.77.129:27000")
rs.remove("10.51.77.129:27002") reconfig
如果想删除,重置用rs.reconfig(),这样做不一定会成功,有的时候无法切换到主节点,所以需要,删除/data/replset目录,然后重启所有mongo的进程。
rs.reconfig({ _id:'rs',members:[{ _id:1, host:'10.51.77.129:27000' }]})
rs.add("10.51.77.129:27000") rs.addArb("10.51.77.129:27002") db.oplog.rs
rs:PRIMARY> use local switched to db local
rs:PRIMARY> show collections me oplog.rs startup_log system.indexes system.replset
rs:PRIMARY>
rs:PRIMARY>
rs:PRIMARY> db.oplog.rs.find()
{
"ts" : Timestamp(1435495192, 1),
"h" : NumberLong(0),
"v" : 2,
"op" : "n",
"ns" : "",
"o" : { "msg" : "initiating set" }
}
{ "ts" : Timestamp(1435495306, 1),
"h" : NumberLong(0),
"v" : 2,
"op" : "n",
"ns" : "",
"o" : { "msg" : "Reconfig set", "version" : 2 }
}
{ "ts" : Timestamp(1435495323, 1),
"h" : NumberLong(0),
"v" : 2,
"op" : "n",
"ns" : "",
"o" : { "msg" : "Reconfig set", "version" : 3 }
} 在SECONDARY节点无法show dbs
主从启动之后,连接slave可以成功连上,但是在slave中执行 show dbs 的时候就报错了:
QUERY Error: listDatabases failed:{ "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" } 解决方法:
在报错的slave机器上执行 rs.slaveOk()方法即可。
解释一下具体slaveOk方法是什么意思?
Provides a shorthand for the following operation:
db.getMongo().setSlaveOk()
This allows the current connection to allow read operations to run on secondary members.
See the readPref() method for more fine-grained control over read preference in the mongo shell. see
- http://segmentfault.com/a/1190000002924522
- http://www.it165.net/database/html/201402/5280.html
内存问题
查看内存情况最常用的是free命令:
[deploy@iZ25xk7uei1Z config]$ free -m
total used free shared buffers cached
Mem: 7567 6821 745 8 129 6122
-/+ buffers/cache: 569 6997
Swap: 0 0 0 限制内存
所有连接消耗的内存加起来会相当惊人,推荐把Stack设置小一点,比如说1024:
ulimit -s 1024 通过调整内核参数drop_caches也可以释放缓存:
sysctl vm.drop_caches=1 有时候,出于某些原因,你可能想释放掉MongoDB占用的内存,不过前面说了,内存管理工作是由虚拟内存管理器控制的,幸好可以使用MongoDB内置的closeAllDatabases命令达到目的:
mongo> use admin
mongo> db.runCommand({closeAllDatabases:1}) 平时可以通过mongo命令行来监控MongoDB的内存使用情况,如下所示:
mongo> db.serverStatus().mem:
{
"resident" : 22346,
"virtual" : 1938524,
"mapped" : 962283
} 还可以通过mongostat命令来监控MongoDB的内存使用情况,如下所示:
shell> mongostat
mapped vsize res faults
940g 1893g 21.9g 0 其中内存相关字段的含义是:
- mapped:映射到内存的数据大小
- visze:占用的虚拟内存大小
- res:占用的物理内存大小
注:如果操作不能在内存中完成,结果faults列的数值不会是0,视大小可能有性能问题。 在上面的结果中,vsize是mapped的两倍,而mapped等于数据文件的大小,所以说vsize是数据文件的两倍,之所以会这样,是因为本例中,MongoDB开启了journal,需要在内存里多映射一次数据文件,如果关闭journal,则vsize和mapped大致相当。
see
- http://www.oschina.net/question/16840_44521
更好的做法是使用docker,一劳永逸
- 手把手教你用Docker部署一个MongoDB集群 http://dockone.io/article/181
全文完
http://my.oschina.net/nodeonly/blog/471834
欢迎关注我的公众号【node全栈】
