操作系统:基于页面置换算法的缓存原理详解(上)
概述:
作为一个学计算机的一定听过缓存(注意这里是缓存,不是缓冲)。比如我们在登录网页时,网页就可以缓存一些用户信息;比如我们在写界面代码的时候,可能就会遇到界面的绘制是基于一些缓存算法的。所以,了解一下缓存算法的原理还是有必要的。
本文链接:http://blog.csdn.net/lemon_tree12138/article/details/50463365 --Coding-Naga
--转载请注明出处
基本分析:
首先我们要做的事情是,我们知道最好的置换或者说缓存算法是,我们可以把那些最不可能会使用的资源或是作业从内存移到外存,以确保尽可能少地进行置换操作。可是,我们又要如何知道后面有哪些资源正在排队呢,或者说即将被使用呢?这里你是不是要问,我们操作系统不是有一个就绪和阻塞的进程队列么?遍历这个列表不就可以知道后面哪些资源最没可能被访问了么?是的,不可否认。如果可以这样的确还不错。可是,这个队列一定是一个动态的队列。比如,在PC上,用户想使用哪个软件都有可能,这个我们不能事先定义好。
既然不能预知,那么这种最佳的转换算法就不能实现。因为我们不能预知,所以我们就要想办法来预测。预测哪些哪些资源可能在近期不会被使用,就换出该资源。
具体算法策略:
1.先进先出(FIFO)页面置换算法
最简单的算法莫过于FIFO了,正是因为这个算法的简单,所以在效果上就并不那么让人满意了。下面是原理图:
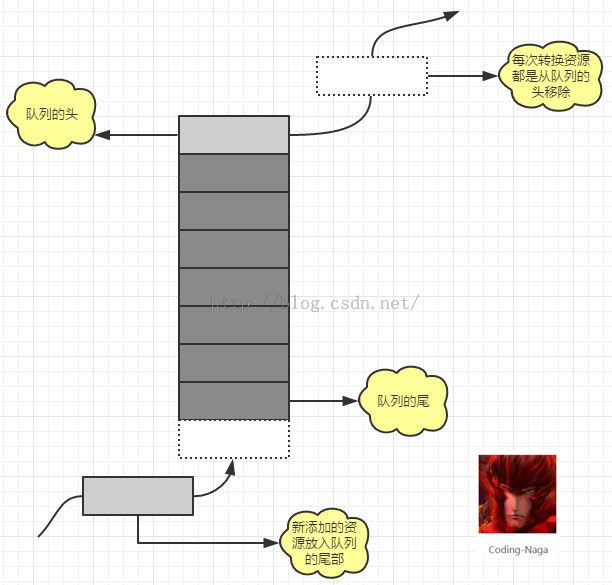
图-1 FIFO算法原理图
在FIFO的原理图中,如果队列还未满时,我们可以随意加入,当队列缓存的数据满了的时候,我们也只是简单地从队列的尾部加入,从队列的头部移除。某一个资源的使用对于资源的移除不产生任何影响。所以,图中就没有展示。代码的编写也很简单,如下:
public class FIFO implements Cacheable {
private int maxLength = 0;
private Queue<Object> mQueue = null;
public FIFO(int _maxLength) {
... ...
}
@Override
public void offer(Object object) {
if (mQueue == null) {
throw new NullPointerException("策略队列对象为空");
}
// check is need swap or not
if (mQueue.size() == maxLength) {
clean();
}
mQueue.offer(object);
}
@Override
public void visitting(Object object) {
System.out.println("Visited " + object);
}
private void clean() {
mQueue.poll();
}
}
2.最近最久未使用(LRU)置换算法

图-2 LRU算法原理图
对比FIFO原理图和LRU原理图,可以很明显地看到只是在被使用的资源部分有一些小的改动。在一般地使用过程中,和FIFO一样,如果队列还未满时,我们可以随意加入,当队列缓存的数据满了的时候,我们一样地从队列的尾部加入,从队列的头部移除了。当我们要访问一个资源的时候,就把这个资源移动到队列的尾部,让这个资源看上去就像最新添加的一样。这个就是我们LRU算法的核心了。
下面提供部分关键代码,完整代码参见文章最下方的源码下载。
public class LRU implements Cacheable {
private int maxLength = 0;
private Queue<Object> mQueue = null;
public LRU(int _maxLength) {
... ...
}
@Override
public void offer(Object object) {
if (mQueue == null) {
throw new NullPointerException("策略队列对象为空");
}
// check is need swap or not
if (mQueue.size() == maxLength) {
clean();
}
mQueue.offer(object);
}
@Override
public void visitting(Object object) {
if (mQueue == null || mQueue.isEmpty()) {
throw new NullPointerException("访问对象不存在");
}
System.out.println("Visited " + object);
displace(object);
}
// remove the longer no visit
private void clean() {
mQueue.poll();
}
// cache core code
private void displace(Object object) {
for (Object tmp : mQueue) {
if (object.equals(tmp)) {
mQueue.remove(tmp);
break;
}
}
mQueue.offer(object);
}
}
3.Clock置换算法
这里有一点需要纠正一下,当你看到“Clock”的时候,请不要把它理解成Clock算法是基于时间片之类的一种算法。Clock算法是把资源队列看成是一个类似Clock一样的,可以循环访问的这么一个特性。

图-3 Clock算法原理图
在Clock页面置换算法中,我们对对象进行了一个二次封装。在封装类中,额外加入了一个新的元素:Flag。这是一个boolean的标志位,用于指示,当前的资源或是进程是否可以被换出。当这个标志位为false的时候,就把这个标志打成true,用于下次遍历到此元素的时候,可以移除它;当这个标志位为true的时候,就把这个元素从队列中移除。当我们要访问某一个对象的时候,就把检查指针指向这个元素的下一个元素,这样下次检查的时候,可以跳过这个元素,确保了当前元素的安全性。代码过程如下(这里省略了一部分轻量级的代码,因为它相对于算法本身本言并不重要,详细代码参见最下方的GitHub源码下载链接):
public class Clock implements Cacheable {
private int maxLength = 0;
private List<ClockBean> list = null;
private int index = 0;
public Clock(int _maxLength) {
... ...
}
@Override
public void offer(Object object) {
if (list == null) {
throw new NullPointerException("策略队列对象为空");
}
if (list.size() == maxLength) {
clean();
} else {
index = (index + 1 + maxLength) % maxLength;
}
list.add((ClockBean) object);
}
@Override
public void visitting(Object object) {
if (object instanceof ClockBean) {
ClockBean bean = (ClockBean) object;
for (int i = 0; i < list.size(); i++) {
if (bean == list.get(i)) {
list.get(i).setCleanFlag(false);
index = (i + 1 + maxLength) % maxLength;
}
}
} else {
System.err.println("Error Type");
}
}
// 移除待置换的对象
private void clean() {
ClockBean bean = list.get(index);
if (bean == null) {
throw new NullPointerException();
}
if (bean.isCleanFlag()) {
list.remove(index);
return;
}
bean.setCleanFlag(true);
clean();
}
}
Ref:
《计算机操作系统》
http://flychao88.iteye.com/blog/1977653
GitHub源码下载:
https://github.com/William-Hai/LRU-Cache