Shark性能测试
按照Shark官方网站的说法,Shark在RAM的时候,比Hive快90倍,这个报告看起来很不错,但是在不同的测试环境和不同的优化条件以及不同的用例场景下,结果都是不同的,所以决定测试了一下Shark0.91搭建在Spark1.0.0和amplab Hive0.11上的性能。
一、集群环境
3台Slave
二、软件环境
Spark1.0.0 with hadoop0.20.2-cdh3u5Shark0.91 + amplab Hive0.11
对比测试VS.
Apache Hive 0.11
三、测试对象
21G 的Text File 文件建立一个表,对该表进行各种查询的性能测试。主要分为数据全部cache在内存时的性能 和 on disk 时的性能比较。
[hadoop@wh-8-210 shark]$ hadoop dfs -ls /user/hive/warehouse/log/ Found 1 items -rw-r--r-- 3 hadoop supergroup 22499035249 2014-06-16 18:32 /user/hive/warehouse/log/21gfilecreate table log
(
c1 string,
c2 string,
c3 string,
c4 string,
c5 string,
c6 string,
c7 string,
c8 string,
c9 string,
c10 string,
c11 string,
c12 string,
c13 string
) row format delimited fields terminated by '\t' stored as textfile;
load data inpath '/user/hive/warehouse/21gfile' into table log;
示例数据:
[10.1.8.210:7100] shark> select * from log_cached limit 10;
2014-05-15 101289 13836998753 2 2010-08-23 22:36:50 0 0 2010-06-02 16:55:25 2010-06-02 16:55:25 None 0
2014-05-15 104497 15936529112 2 2011-01-11 09:58:47 0 0 2011-01-11 09:58:50 2011-01-19 09:58:50 61.172.242.36 2011-01-19 08:59:47 0
2014-05-15 105470 15000037972 0 2013-07-21 11:35:26 0 0 2013-07-21 11:29:08 2013-07-21 11:29:08 2013-07-21 11:35:26 0
2014-05-15 111864 13967013250 2 2010-11-28 21:06:56 0 0 2010-11-28 21:06:57 2010-12-06 21:06:57 61.172.242.36 2010-12-06 20:08:11 0
2014-05-15 112922 13766378550 2 2010-08-23 22:36:50 0 0 2010-03-29 00:08:17 2010-03-29 00:08:17 None 0
2014-05-15 113685 15882981310 2 2011-04-28 18:24:57 0 0 2011-04-28 17:38:37 2011-04-28 17:38:37 127.0.0.1 None 0
2014-05-15 116368 15957685805 2 2011-06-27 17:05:55 0 0 2011-06-27 17:06:01 2011-07-05 17:06:01 10.129.20.108 2011-07-05 16:11:05 0
2014-05-15 136020 13504661323 2 2012-02-11 18:51:17 0 0 2012-02-11 18:51:19 2012-02-19 18:51:19 10.129.20.109 2012-03-03 14:37:05 0
2014-05-15 137597 15993791204 2 2011-12-07 00:45:03 0 0 2011-12-07 00:44:59 2011-12-15 00:44:59 10.129.20.98 2011-12-14 23:45:40 0
2014-05-15 155020 13760211160 2 2011-05-25 14:27:24 0 0 2011-05-25 14:02:54 2011-05-25 14:02:54 127.0.0.1 2011-07-28 16:42:21 0
Time taken (including network latency): 0.33 seconds
将21G数据全部cache到内存
cache rdd
sql : CREATE TABLE log_cached TBLPROPERTIES ("shark.cache" = "true") AS SELECT * from log;
Time taken (including network latency): 282.006 seconds
[10.1.8.210:7100] shark> select * from log_cached limit 1;
2014-05-15 101289 13836998753 2 2010-08-23 22:36:50 0 0 2010-06-02 16:55:25 2010-06-02 16:55:25 None 0
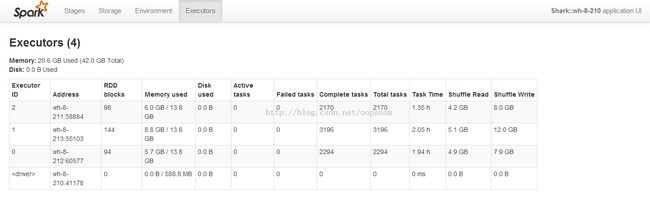
cache后如图336个partition:

四、测试用例及结果
这个测试没有对hive和shark进行任何调优,均在相同的环境下进行测试,一下是测试结果:用例:
1、测试count
2、测试sum
3、测试avg
4、测试group by
5、测试join
6、测试select
7、测试sort
8、测试一段稍微复杂的Sql
测试结果:
以下是测试结果图:
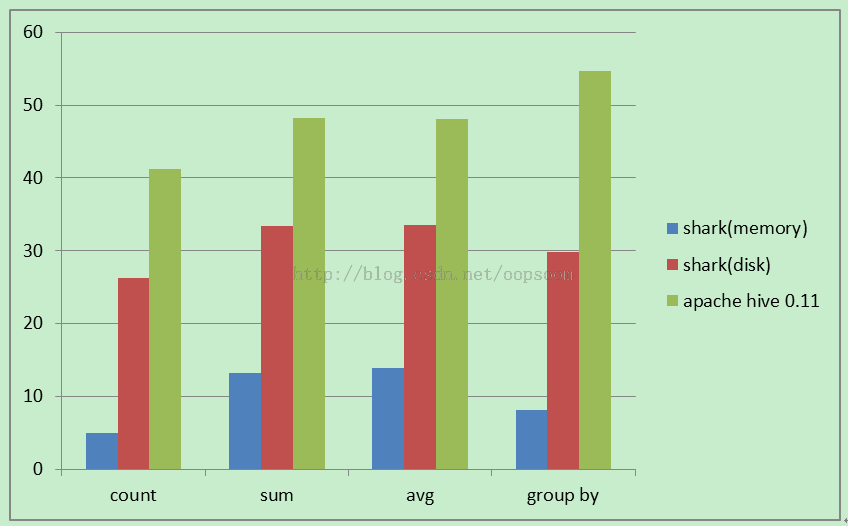
测试count、sum、avg、group by
单位(秒)
| shark(memory) |
shark(disk) |
apache hive 0.11 |
|
| count |
5.053 |
26.223 |
41.255 |
| sum |
13.207 |
33.401 |
48.204 |
| avg |
13.88 |
33.519 |
48.159 |
| group by |
8.14 |
29.852 |
54.705 |
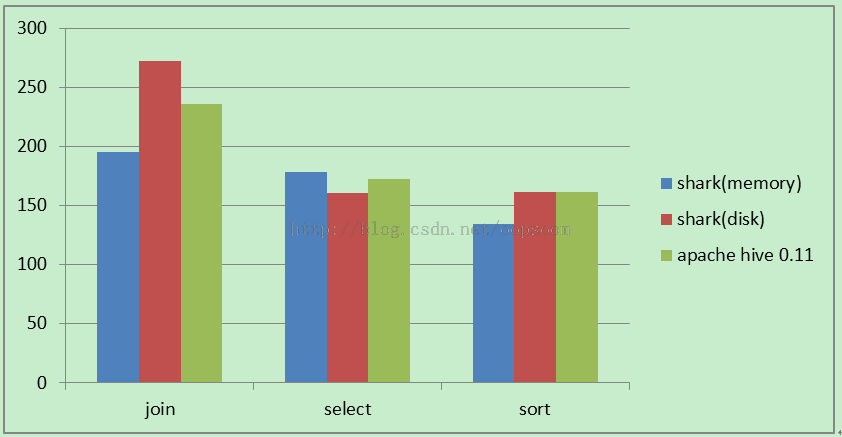
测试join,select,sort
单位(秒)
| shark(memory) |
shark(disk) |
apache hive 0.11 |
|
| join |
194.98 |
272.36 |
236.203 |
| select |
178.53 |
161.01 |
172.762 |
| sort |
134.23 |
161.07 |
161.789 |
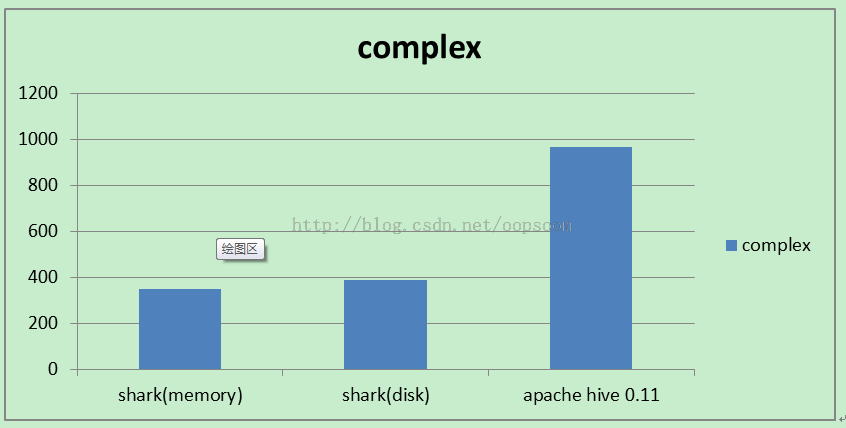
测试复杂sql
测试一段稍微复杂的Sql:
set mapred.reduce.tasks=200; create table complex as select a.c4, a.time from (select c4, max(c10) time from log_cached group by c4 ) a join (select c10 time, c11 from log_cached group by c10,c11 )b on a.time = b.time
执行该sql, hive会启动5个job
Total MapReduce jobs = 5 Launching Job 1 out of 5 Number of reduce tasks not specified.Defaulting to jobconf value of: 200 In order to change the average load for areducer (in by… Ended Job = job_201406131753_0033 Moving data to:hdfs://10.1.8.210:9000/user/hive/warehouse/complex Table default.complex stats:[num_partitions: 0, num_files: 200, num_rows: 0, total_size: 7769834233,raw_data_size: 0] 242791443 Rows loaded tohdfs://10.1.8.210:9000/tmp/hive-hadoop/hive_2014-06-20_17-05-17_199_1498492429758626519/-ext-10000 MapReduce Jobs Launched: Job 0: Map: 84 Reduce: 200 Cumulative CPU: 3709.42 sec HDFSRead: 22542324372 HDFS Write: 8287517376 SUCCESS Job 1: Map: 84 Reduce: 200 Cumulative CPU: 3015.82 sec HDFSRead: 22542324372 HDFS Write: 3528775299 SUCCESS Job 2: Map: 43 Reduce: 200 Cumulative CPU: 4442.77 sec HDFSRead: 11816414510 HDFS Write: 7769834233 SUCCESS Total MapReduce CPU Time Spent: 0 days 3hours 6 minutes 8 seconds 10 msec OK Time taken: 964.809seconds
单位(秒)
| shark(memory) |
shark(disk) |
apache hive 0.11 |
|
| complex |
349.858 |
388.844 |
964.809 |
我们知道,Shark的执行引擎是Spark, spark在执行job的时候,会有一个DAGScheduler,少了多余了IO,大大提高了执行效率。
所以在执行一段稍微复杂的sql,而不是向前面简单sql的测试,Shark的其它方面的优势也体现出来了。
总结:
1. 在简单的sql查询中,普通的函数如count,avg, sum, group by均比hive快3-5x
2. 在简单的sql查询中join,select, sort 方面shark和hive不相上下。
3. 在复杂SQL查询中,Shark的优势体现出来,几乎是hive的3x倍,越复杂的sql,hive的性能损失越多,而shark针对复杂SQL有优化。
-EOF-