OpenRisc-42-or1200的ALU模块分析
引言
computer(计算机),顾名思义,就是用来compute(计算)的。计算机体系结构在上世纪五六十年代的时候,主要就是研究如何设计运算部件,就是想办法用最少的元器件(那时元器件很贵),最快的速度,完成加减乘除。。。。。。等等这些运算。后来发现运算已经足够快了,快到已经无法提供足够的运算指令和运算的操作数了,人们才开始研究如何给运算部件提供足够的指令和数据,这就产生了cache啊,分支预测啊,流水线啊,等等技术。
本小节,我们就分析一下or1200的运算部件。
1,基础
在上世纪50年代中期以前,计算机(computer),就相当于计算器(calculator)。后来由冯诺依曼在1945年6月30号,对EDVAC计算机分析总结时,提出了采用二进制运算和在计算机中加入存储部件。后来人们把这种结构的计算机就叫冯诺依曼体系结构,运算方式也由原来的十进制改成二进制。由于冯诺依曼是普林斯顿大学的第一批终身教授,人们把冯诺依曼体系结构也叫普林斯顿体系结构。而那份分析报告,就是著名的101报告。关于101报告,其名称是First Draft of a Report on the EDVAC,内容我已上传,请参考:
http://download.csdn.net/detail/rill_zhen/5850885
从EDVAC计算机开始,运算采用二进制,于是就引入了不同的数据表示形式:原码,反码,补码。
原码:
数值前面增加了一位符号位(即最高位为符号位):正数该位为0,负数该位为1(0有两种表示:+0和-0),其余位表示数值的大小。
反码:
正数的反码与其原码相同;负数的反码是对其原码逐位取反,但符号位除外。
补码:
正数的补码,与原码相同。负数的补码,负数的补码等于其绝对值的原码各位取反,然后整个数加1的数值。
2,加法器
1>整体介绍
学过数字电路设计的人可能都知道,加法器是CPU一切运算的基础。
加法器的基本单元是:半加器(half adder),全加器(full adder)。
有这些基本单元可组成很多种不同形式的加法器:行波进位加法器,先行进位加法器,跳跃进位加法器,选择进位加法器,递增进位加法器等。其中先行进位加法器使用最广泛。
关于加法器的概念,真值表,卡诺图,逻辑表达式,表达式的化简,逻辑图,大部分介绍数字电路设计的书里都会有介绍,这里不再赘述,下面我们直接说明这些加法器的RTL描述。
如果您数电基础不是很好,请参考我之前写的一篇文章:http://blog.csdn.net/rill_zhen/article/details/7826689
2>半加器
两个1位二进制数相加,就叫半加。可以进行半加运算的器件,就是半加器。
道理简单,也容易理解,那么我们如何用verilog HDL描述一个半加器呢?如下所示:是一个1-bit的半加器
module ha(sum,c_out,x,y); //half adder
input x,y;
output sum,c_out;
assign {c_out,sum}=x+y;
endmodule // ha
3>全加器
上面说了半加,两个加数都是1-bit,实际情况下,两个加数肯定不止1-bit。两个同位的加数(加数a,加数b)和来自低位的进位(进位c),这三部分相加的运算就叫全加,实现全加运算的电路。就是全加器。
道理也比较简单,那么我们如何用verilog HDL描述一个全加器呢?如下所示:,是一个1-bit的全加器
module fa(sum,c_out,c_in,x,y); //full adder
input x,y,c_in;
output sum,c_out;
assign {c_out,sum}=x+y+c_in;
endmodule
有了半加器和全加器,我们就可以组成各种各样的加法器了。
4>减法器
一般CPU中没有专门的减法器,这是因为用补码表示的数的减法可以转换成加法,如下所示:
[A]补 - [B]补 = [A - B]补 = [A]补 + [ - B]补
所以要想进行减法运算,只要将被减数按位取反,在做加法运算即可。
3,乘法器
1>整体介绍
最老的计算机中的CPU内部是没有乘法器的,如果想要进行乘法运算,先由软件把乘法运算变换成加法运算,然后再交给CPU进行处理,来完成乘法运算。可想而知,那时的CPU的性能是如此之低,后来随着对运算速度的要求,需要硬件实现乘法器。
如何实现乘法器呢?我们最容易想到的就是把乘法变成多次加法运算,最终实现乘法。
比如,我们想计算123x456,怎么算呢?
很简单,我们把123加456次就可以了。电路简单可靠。没错,是简单可靠,但是不同的数相乘需要的时间也不同,如果我们要计算0xffff_ffff * 0xffff_ffff,每次加法需要1个cycle的话,那就得需要0xffff_ffff个cycle啊。显然不可行,怎么办呢?现在的乘法器,只需要一个cycle就能计算完毕,到底是怎么实现的呢?冰冻三尺非一日之寒,不是突然就做到的,有一个很长的过程。但是在这个过程中有两个里程碑式的进展不得不提,第一,booth算法,第二,wallace tree。
2>booth算法
booth算法是booth两口子在1950年提出来的,最开始是1-bit的booth算法,后来这对夫妻又通力合作,把2-bitbooth算法也弄出来了,现在测CPU中大量使用2-bit的booth算法。
booth算法的核心作用就是将两个多位数的乘积,变成多个部分乘积的相加,关于booth细节,我把这两口子当年写的文章也上传了,如果有兴趣,可参考:
http://download.csdn.net/detail/rill_zhen/5851245
关于booth算法的细节,可参考相关的文献,这里不再赘述。但是booth算法的verilogHDL的实现,则必须要说,如下所示,下面是4位数相乘的booth算法的实现:
module booth_encoder(mr,md,x,z);
input[3:0] mr,md;
output [3:0] x,z;
//reg [3:0] mr,md;
reg [3:0] x,z;
reg [1:0] i;
always@(mr or md)
begin
x[0]=md[0];
z[0]=md[0];
x[1]=md[1]&~md[0];
z[1]=md[1]^md[0];
x[2]=md[2]&~md[1];
z[2]=md[2]^md[1];
x[3]=md[3]&~md[2];
z[3]=md[3]^md[2];
end
endmodule // booth_encoder
3>wallace tree
乘法运算,经过booth算法处理,变成了多个数的相加,这显然还是不能满足性能要求,于是wallace这个兄弟出现了。
wallace是澳大利亚人,全名叫charis wallace,wallace 树是他在1964年提出的,之所以叫华莱士树就是因为采用wallace算法的电路外形像一棵树。华莱士树的核心思想是将多个数的相加变成两个数的相加。这样,乘法运算就大功告成了,两个数的乘法运算经booth夫妇和wallace三个人的努力变成了两个数的相加,实现了只需要一个cycle就能完成乘法运算。关于华莱士树,请参考:http://en.wikipedia.org/wiki/Wallace_tree ,这里不再赘述,那么如何用verilog HDL实现华莱士树呢,如下所示,下面是4-bit数相乘(注,经booth处理之后为8-bit)的华莱士树实现:
module wallace(r0,r1,r2,r3,result); input[7:0] r0,r1,r2,r3; output [7:0] result; wire [7:0] result; wire w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15,w16,w17,w18,w19; wire o1,o2,o3,o4,o5,o6,o7,o8,o9,o10,o11; wire tmp; //level 1 ha ha1(o1,w1,r1[2],r2[2]); fa fa2(o2,w2,r2[3],r3[3],r1[3]); fa fa3(o3,w3,r1[4],r2[4],r3[4]); fa fa4(o4,w4,r1[5],r2[5],r3[5]); fa fa5(o5,w5,r1[6],r2[6],r3[6]); fa fa17(o10,w16,r0[7],r1[7],r2[7]); //level 2 ha ha6(o6,w6,o2,r0[3]); fa fa7(o7,w7,w2,o3,r0[4]); fa fa8(o8,w8,w3,o4,r0[5]); fa fa9(o9,w9,w4,o5,r0[6]); fa fa18(o11,w17,w5,o10,r3[7]); //fast CL A not not1(w19,r0[0]); not not2(result[0],w19); ha ha10(result[1],w10,r0[1],r1[1]); fa fa11(result[2],w11,w10,r0[2],o1); fa fa12(result[3],w12,w11,w1,o6); fa fa13(result[4],w13,w12,w6,o7); fa fa14(result[5],w14,w13,w7,o8); fa fa15(result[6],w15,w14,w8,o9); fa fa16(result[7],w18,w15,w9,o11); endmodule
4,乘法器的verilog HDL实现与仿真
1>模块划分
经过前面的努力,我们是时候做一个完整的测试了。booth算法和wallace树到底灵不灵,管不管用呢?下面我们就以两个4-bit数的相乘来测试一下。
我们将整个工程分为下面几个模块:
a,半加器:ha
b,全加器:fa
c,部分积模块:partial
d,booth算法模块:booth_encoder
e,wallace树模块:wallace
f,总模块:mul_test1
g,测试激励:tb
2>电路实现
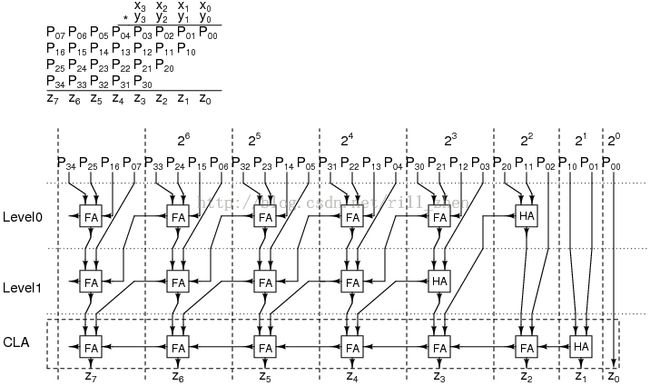
下面是4-bit乘法器的电路图,可以看出,整个乘法器只用了18个加法器(15个全加器,3个半加器)。
3>RTL实现
共七个模块,由于代码都比较简单,就没必要每个模块弄一个文件,所以,我们分成两个文件:multiply.v和tb.v。第一个文件放工作模块,第二个文件放testbench。
文件如下:
multiply.v:
/* * * rill_zhen created 2013-08-01 * [email protected] * */ module ha(sum,c_out,x,y); //half adder input x,y; output sum,c_out; assign {c_out,sum}=x+y; endmodule // ha module fa(sum,c_out,c_in,x,y); //full adder input x,y,c_in; output sum,c_out; assign {c_out,sum}=x+y+c_in; endmodule module partial(x,z,r0,r1,r2,r3,md,mr); input[3:0] x,z; input[3:0] mr,md; output [7:0] r0,r1,r2,r3; reg [7:0] r0,r1,r2,r3; reg [3:0] comp; reg [7:0] tmp; always@(x or z or mr or md) begin comp=~mr+1; tmp=comp<<1; //r0 if (~(x[0]|z[0])) r0=0; else if (~x[0]&z[0]) begin if(mr[3]) r0=mr|8'b11110000; else r0=mr; end else if (x[0]&z[0]) begin if(comp[3]) r0=comp|8'b11110000; else r0=comp; end //r1 if (~(x[1]|z[1])) r1=0; else if (~x[1]&z[1]) begin if(mr[3]) r1=(mr|8'b11110000)<<1; else r1=mr<<1; end else if (x[1]&z[1]) begin if(comp[3]) r1=(comp|8'b11110000)<<1; else r1=comp<<1; end //r2 if (~(x[2]|z[2])) r2=0; else if (~x[2]&z[2]) begin if(mr[3]==1) r2=(mr|8'b11110000)<<2; else r2=mr<<2; end else if (x[2]&z[2]) begin if(comp[3]) r2=(comp|8'b11110000)<<2; else r2=comp<<2; end //r3 if (~(x[3]|z[3])) r3=0; else if (~x[3]&z[3]) begin if(mr[3]) r3=(mr|8'b11110000)<<3; else r3=mr<<3; end else if (x[3]&z[3]) begin if(comp[3]) r3=(comp|8'b11110000)<<3; else r3=comp<<3; end end endmodule// Verilog HDL for "ee103", "partial_generator" "functional" module booth_encoder(mr,md,x,z); input[3:0] mr,md; output [3:0] x,z; //reg [3:0] mr,md; reg [3:0] x,z; reg [1:0] i; always@(mr or md) begin x[0]=md[0]; z[0]=md[0]; x[1]=md[1]&~md[0]; z[1]=md[1]^md[0]; x[2]=md[2]&~md[1]; z[2]=md[2]^md[1]; x[3]=md[3]&~md[2]; z[3]=md[3]^md[2]; end endmodule // booth_encoder // Verilog HDL for "ee103", "wallace" "functional" module wallace(r0,r1,r2,r3,result); input[7:0] r0,r1,r2,r3; output [7:0] result; wire [7:0] result; wire w1,w2,w3,w4,w5,w6,w7,w8,w9,w10,w11,w12,w13,w14,w15,w16,w17,w18,w19; wire o1,o2,o3,o4,o5,o6,o7,o8,o9,o10,o11; wire tmp; //level 1 ha ha1(o1,w1,r1[2],r2[2]); fa fa2(o2,w2,r2[3],r3[3],r1[3]); fa fa3(o3,w3,r1[4],r2[4],r3[4]); fa fa4(o4,w4,r1[5],r2[5],r3[5]); fa fa5(o5,w5,r1[6],r2[6],r3[6]); fa fa17(o10,w16,r0[7],r1[7],r2[7]); //level 2 ha ha6(o6,w6,o2,r0[3]); fa fa7(o7,w7,w2,o3,r0[4]); fa fa8(o8,w8,w3,o4,r0[5]); fa fa9(o9,w9,w4,o5,r0[6]); fa fa18(o11,w17,w5,o10,r3[7]); //fast CL A not not1(w19,r0[0]); not not2(result[0],w19); ha ha10(result[1],w10,r0[1],r1[1]); fa fa11(result[2],w11,w10,r0[2],o1); fa fa12(result[3],w12,w11,w1,o6); fa fa13(result[4],w13,w12,w6,o7); fa fa14(result[5],w14,w13,w7,o8); fa fa15(result[6],w15,w14,w8,o9); fa fa16(result[7],w18,w15,w9,o11); endmodule //`timescale 1ns/10ps module mul_test1(result,mr,md); input[3:0] mr,md; output [7:0] result; wire [3:0] x,z; wire [7:0] r0,r1,r2,r3; booth_encoder booth(mr,md,x,z); partial pp(x,z,r0,r1,r2,r3,md,mr); wallace tree(r0,r1,r2,r3,result); //$monitor("mr=%b,md=%b,result=%d",mr,md,result); endmodule
tb.v:
/*
*
* rill created 01/08/2013
*
*/
`timescale 1ns / 1ns
module tb;
reg [3:0] mr = 0;
reg [3:0] md = 0;
wire [7:0] result;
integer loop1 = 0;
integer loop2 = 0;
mul_test1 mul_test10
(
.result (result),
.mr (mr),
.md (md)
);
initial
begin
#0
mr = 4'd0;
md = 4'd0;
#10
for (loop1=0;loop1<=4'b1111;loop1=loop1+1)
begin
for (loop2=0;loop2<=4'b1111;loop2=loop2+1)
begin
#10
mr = loop1;
md = loop2;
$display("sn:0x%x-->mr:0x%x,md:0x%x,result=0x%x",loop1*loop2,mr,md,result);
end
end
#100 $stop;
end
endmodule
/************* EOF *************/
4>仿真
用modelsim对这个工程进行仿真,波形如下所示,从中我们可以看出,乘法运算是正确的。0x3 * 0x7 = 0x15。

5,除法器
除法器的verilog HDL实现,我在很早以前就曾写过一篇相关的文章,请参考:http://blog.csdn.net/rill_zhen/article/details/7961937
6,or1200的运算部件实现分析
前面我们了解了加法器,乘法器,除法器的实现,在来分析or1200的实现就容易一点了。
1>整体分析
or1200的运算模块统一由ALU单元管理,如果是简单的运算(或,异或,移位,位扩展)等有ALU自己计算输出结果,如果是乘除运算,有单独的mult_mac模块计算完成后,将结果送给ALU,然后ALU统一将结果输出到下一级流水线。
由于or1200只有一个运算单元(向量机是多个),所以要把所有要进行运算的模块选择其中的一个,所以就需要一个mux,就是operandmux模块,对应or1200_openrandmuxes.v文件。

多路选择器的核心代码如下所示:
// // Operand A register // always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) begin operand_a <= 32'd0; saved_a <= 1'b0; end else if (!ex_freeze && id_freeze && !saved_a) begin operand_a <= muxed_a; saved_a <= 1'b1; end else if (!ex_freeze && !saved_a) begin operand_a <= muxed_a; end else if (!ex_freeze && !id_freeze) saved_a <= 1'b0; end // // Operand B register // always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) begin operand_b <= 32'd0; saved_b <= 1'b0; end else if (!ex_freeze && id_freeze && !saved_b) begin operand_b <= muxed_b; saved_b <= 1'b1; end else if (!ex_freeze && !saved_b) begin operand_b <= muxed_b; end else if (!ex_freeze && !id_freeze) saved_b <= 1'b0; end // // Forwarding logic for operand A register // always @(ex_forw or wb_forw or rf_dataa or sel_a) begin `ifdef OR1200_ADDITIONAL_SYNOPSYS_DIRECTIVES casez (sel_a) // synopsys parallel_case infer_mux `else casez (sel_a) // synopsys parallel_case `endif `OR1200_SEL_EX_FORW: muxed_a = ex_forw; `OR1200_SEL_WB_FORW: muxed_a = wb_forw; default: muxed_a = rf_dataa; endcase end // // Forwarding logic for operand B register // always @(simm or ex_forw or wb_forw or rf_datab or sel_b) begin `ifdef OR1200_ADDITIONAL_SYNOPSYS_DIRECTIVES casez (sel_b) // synopsys parallel_case infer_mux `else casez (sel_b) // synopsys parallel_case `endif `OR1200_SEL_IMM: muxed_b = simm; `OR1200_SEL_EX_FORW: muxed_b = ex_forw; `OR1200_SEL_WB_FORW: muxed_b = wb_forw; default: muxed_b = rf_datab; endcase end
2>ALU模块代码分析
1》整体分析
下面是ALU模块的核心代码:
//
// Central part of the ALU
//
always @(alu_op or alu_op2 or a or b or result_sum or result_and or macrc_op
or shifted_rotated or mult_mac_result or flag or result_cust5 or carry
`ifdef OR1200_IMPL_ALU_EXT
or extended
`endif
) begin
`ifdef OR1200_CASE_DEFAULT
casez (alu_op) // synopsys parallel_case
`else
casez (alu_op) // synopsys full_case parallel_case
`endif
`ifdef OR1200_IMPL_ALU_FFL1
`OR1200_ALUOP_FFL1: begin
`ifdef OR1200_CASE_DEFAULT
casez (alu_op2) // synopsys parallel_case
`else
casez (alu_op2) // synopsys full_case parallel_case
`endif
0: begin // FF1
result = a[0] ? 1 : a[1] ? 2 : a[2] ? 3 : a[3] ? 4 : a[4] ? 5 : a[5] ? 6 : a[6] ? 7 : a[7] ? 8 : a[8] ? 9 : a[9] ? 10 : a[10] ? 11 : a[11] ? 12 : a[12] ? 13 : a[13] ? 14 : a[14] ? 15 : a[15] ? 16 : a[16] ? 17 : a[17] ? 18 : a[18] ? 19 : a[19] ? 20 : a[20] ? 21 : a[21] ? 22 : a[22] ? 23 : a[23] ? 24 : a[24] ? 25 : a[25] ? 26 : a[26] ? 27 : a[27] ? 28 : a[28] ? 29 : a[29] ? 30 : a[30] ? 31 : a[31] ? 32 : 0;
end
default: begin // FL1
result = a[31] ? 32 : a[30] ? 31 : a[29] ? 30 : a[28] ? 29 : a[27] ? 28 : a[26] ? 27 : a[25] ? 26 : a[24] ? 25 : a[23] ? 24 : a[22] ? 23 : a[21] ? 22 : a[20] ? 21 : a[19] ? 20 : a[18] ? 19 : a[17] ? 18 : a[16] ? 17 : a[15] ? 16 : a[14] ? 15 : a[13] ? 14 : a[12] ? 13 : a[11] ? 12 : a[10] ? 11 : a[9] ? 10 : a[8] ? 9 : a[7] ? 8 : a[6] ? 7 : a[5] ? 6 : a[4] ? 5 : a[3] ? 4 : a[2] ? 3 : a[1] ? 2 : a[0] ? 1 : 0 ;
end
endcase // casez (alu_op2)
end // case: `OR1200_ALUOP_FFL1
`endif // `ifdef OR1200_IMPL_ALU_FFL1
`ifdef OR1200_IMPL_ALU_CUST5
`OR1200_ALUOP_CUST5 : begin
result = result_cust5;
end
`endif
`OR1200_ALUOP_SHROT : begin
result = shifted_rotated;
end
`ifdef OR1200_IMPL_ADDC
`OR1200_ALUOP_ADDC,
`endif
`ifdef OR1200_IMPL_SUB
`OR1200_ALUOP_SUB,
`endif
`OR1200_ALUOP_ADD : begin
result = result_sum;
end
`OR1200_ALUOP_XOR : begin
result = a ^ b;
end
`OR1200_ALUOP_OR : begin
result = a | b;
end
`ifdef OR1200_IMPL_ALU_EXT
`OR1200_ALUOP_EXTHB : begin
result = extended;
end
`OR1200_ALUOP_EXTW : begin
result = extended;
end
`endif
`OR1200_ALUOP_MOVHI : begin
if (macrc_op) begin
result = mult_mac_result;
end
else begin
result = b << 16;
end
end
`ifdef OR1200_MULT_IMPLEMENTED
`ifdef OR1200_DIV_IMPLEMENTED
`OR1200_ALUOP_DIV,
`OR1200_ALUOP_DIVU,
`endif
`OR1200_ALUOP_MUL,
`OR1200_ALUOP_MULU : begin
result = mult_mac_result;
end
`endif
`OR1200_ALUOP_CMOV: begin
result = flag ? a : b;
end
`ifdef OR1200_CASE_DEFAULT
default: begin
`else
`OR1200_ALUOP_COMP, `OR1200_ALUOP_AND: begin
`endif
result=result_and;
end
endcase
end
2》各种运算的具体实现
从上面代码中我们可以看出or1200的异或,或运算都是直接使用的运算符,寻找第一个为1的位。
or1200的加法实现:
assign {cy_sum, result_sum} = (a + b_mux) + carry_in;
// Numbers either both +ve and bit 31 of result set
assign ov_sum = ((!a[width-1] & !b_mux[width-1]) & result_sum[width-1]) |
// or both -ve and bit 31 of result clear
((a[width-1] & b_mux[width-1]) & !result_sum[width-1]);
or1200的与运算实现:
assign result_and = a & b;
or1200的位扩展运算实现:
always @(alu_op or alu_op2 or a) begin
casez (alu_op2)
`OR1200_EXTHBOP_HS : extended = {{16{a[15]}},a[15:0]};
`OR1200_EXTHBOP_BS : extended = {{24{a[7]}},a[7:0]};
`OR1200_EXTHBOP_HZ : extended = {16'd0,a[15:0]};
`OR1200_EXTHBOP_BZ : extended = {24'd0,a[7:0]};
default: extended = a; // Used for l.extw instructions
endcase // casez (alu_op2)
end
or1200的循环移位运算实现:
//
// Shifts and rotation
//
always @(alu_op2 or a or b) begin
case (alu_op2) // synopsys parallel_case
`OR1200_SHROTOP_SLL :
shifted_rotated = (a << b[4:0]);
`OR1200_SHROTOP_SRL :
shifted_rotated = (a >> b[4:0]);
`ifdef OR1200_IMPL_ALU_ROTATE
`OR1200_SHROTOP_ROR :
shifted_rotated = (a << (6'd32-{1'b0,b[4:0]})) |
(a >> b[4:0]);
`endif
default:
shifted_rotated = ({32{a[31]}} <<
(6'd32-{1'b0, b[4:0]})) |
a >> b[4:0];
endcase
end
or1200的位清零和置一实现:
// Examples for move byte, set bit and clear bit
//
always @(cust5_op or cust5_limm or a or b) begin
casez (cust5_op) // synopsys parallel_case
5'h1 : begin
casez (cust5_limm[1:0])
2'h0: result_cust5 = {a[31:8], b[7:0]};
2'h1: result_cust5 = {a[31:16], b[7:0], a[7:0]};
2'h2: result_cust5 = {a[31:24], b[7:0], a[15:0]};
2'h3: result_cust5 = {b[7:0], a[23:0]};
endcase
end
5'h2 :
result_cust5 = a | (1 << cust5_limm);
5'h3 :
result_cust5 = a & (32'hffffffff ^ (1 << cust5_limm));
//
// *** Put here new l.cust5 custom instructions ***
//
default: begin
result_cust5 = a;
end
endcase
end // always @ (cust5_op or cust5_limm or a or b)
or1200的乘除运算实现:
上面说过,or1200的乘除运算有专门的模块来实现,叫or1200_mult_mac,对应or1200_mult_mac.v文件。
需要说明的是,这个模块提供了两种实现方式一种是前面我们介绍的利用booth算法,wallace树实现的,另外一种就是直接用的verilog的运算符‘*’和‘/’。
具体采用哪一个,通过编译开关OR1200_ASIC_MULTP2_32X32来控制,这个变量在or1200_define.v中有定义,如下所示,从中可以看出目前ORPSoC采用的是用运算符实现的。
// // Select between ASIC optimized and generic multiplier // //`define OR1200_ASIC_MULTP2_32X32 `define OR1200_GENERIC_MULTP2_32X32
r1200_mult_mac.v中根据定义,选择是采用booth算法还是使用运算符。
// // Instantiation of the multiplier // `ifdef OR1200_ASIC_MULTP2_32X32 or1200_amultp2_32x32 or1200_amultp2_32x32( .X(x), .Y(y), .RST(rst), .CLK(clk), .P(mul_prod) ); `else // OR1200_ASIC_MULTP2_32X32 or1200_gmultp2_32x32 or1200_gmultp2_32x32( .X(x), .Y(y), .RST(rst), .CLK(clk), .P(mul_prod) ); `endif // OR1200_ASIC_MULTP2_32X32
采用booth,wallace算法的实现对应的文件是:or1200_amultp2_32x32.v,代码全是开关级建模,一般人是看不懂的,但是我们已将了解了具体的算法,所以看不懂没关系。
采用运算符的话,就简单多了,直接写个符号,然后交给综合器生成对应的电路,对应文件是:or1200_gmultp2_32x32.v,代码如下:
`ifdef OR1200_GENERIC_MULTP2_32X32
`define OR1200_W 32
`define OR1200_WW 64
module or1200_gmultp2_32x32 ( X, Y, CLK, RST, P );
input [`OR1200_W-1:0] X;
input [`OR1200_W-1:0] Y;
input CLK;
input RST;
output [`OR1200_WW-1:0] P;
reg [`OR1200_WW-1:0] p0;
reg [`OR1200_WW-1:0] p1;
integer xi;
integer yi;
//
// Conversion unsigned to signed
//
always @(X)
xi = X;
//
// Conversion unsigned to signed
//
always @(Y)
yi = Y;
//
// First multiply stage
//
always @(posedge CLK or `OR1200_RST_EVENT RST)
if (RST == `OR1200_RST_VALUE)
p0 <= `OR1200_WW'b0;
else
p0 <= xi * yi;
//
// Second multiply stage
//
always @(posedge CLK or `OR1200_RST_EVENT RST)
if (RST == `OR1200_RST_VALUE)
p1 <= `OR1200_WW'b0;
else
p1 <= p0;
assign P = p1;
endmodule
`endif
7,小结
本小节我们了解了加法器,乘法器,除法器的一般实现算法,还用一个4-bit的乘法器做了仿真验证,最后对or1200的具体实现进行了分析。