hello,intel TBB
Intel Threading BuildingBlocks(Intel TBB)是一个使用ISO C++代码实现的多平台、可扩展并行编程库。但目前为止这方面的中文资料却很少。初步了解TBB时,并非每个人都打算看官方提供的资料,即使是Intel Threading BuildingBlocks Tutorial。
准备
l 下载编译TBB
免费版本的TBB可以从下面的链接下载
TBB的编译特别简单,如果使用visual studio,打开解压缩目录后的build目录,在msvs目录找到vs的工程文件打开就可以编译。要注意的是*_icl.sln工程是为使用了intel的编译器的vs提供的。如果使用g++,直接make即可。默认不编译test和examples,可以打开Makefile文件查看更多的选项。
l 编译示例
示例为了简短采用了lambda表达式,在vs2010和g++4.61环境编译通过。如果采用g++,记得加上选项 –std=c++0x
hello,intel TBB
例:1-1
#include <tbb/tbb.h>
#include <iostream>
using namespace tbb;
using namespace std;
int main()
{
parallel_for(0,10,[](int v){cout<<v<<'';});
return0;
}

可以看到,由于可能会并行执行,上面的输出虽然将0-9的字母都打印了出来,
但并没有按照0 1 2 3 4 的顺序。当然,这个结果只是众多结果中的一种,
也可能是下面的样子:
TBB的结构:
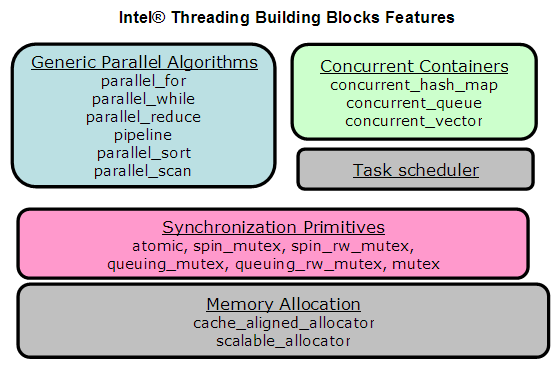
上图的内容可以分为以下几类:
- 通用并行算法 TBB提供了parallel_for,parallel_while,parallel_reduce等算法,应用于不同的并行算法场景
- 并发容器 这是对常见容器的线程安全版本的实现,同时考虑到性能要求,提供了细粒度的锁机制,TBB2.0里提供的容器包括hash map,vector,queue。
- 任务调度器:提供了task机制的封装
- 同步原语:提供了原子操作、mutex、lock等同步原语的封装
- 内存分配:提供了对cache机制更友好的支持
术语与基本概念
Ø 概念(concept)
TBB的参考手册中经常提到concept,这里的意思是满足某个类型约束的集合。这种约束可以是语法上的,也可以是语义上的。例如,“可排序”的概念可被定义为让一个数组能被排序的需求的集合。类型T如果满足以下条件就是可排序的:
l x<y 返回bool值,并且表示类型为T的项的总顺序
l swap(x,y)交换x,y
定义概念的两种途径是有效的表达式和伪签名(valid expressions andpseudo-signatures)。ISO C++ 标准采用了前者。TBB的文档使用伪签名方式,因为他们认为它简洁,通过剪切-粘贴就可以得到初步的实现。例如,下表显示了一个可排序类型的伪签名:
| 伪签名 |
语义 |
| bool operator<(const T& x, const T& y) |
比较x和y |
| void swap(T&x, T& y) |
交换x和y |
Ø 模型(model)
如果一个类型满足了概念描述的需求,那么它就是这个概念的模型。TBB中的有两个非常重要的概念:可分割(splittable)、区域(range)。
Ø 分割(splitable concept):
包含一个分割构造函数的类型是可分割的。分割构造函数原型为:
X::X(X& obj, Split)
能将实例obj分割为obj以及一个新构造的对象。其中的Split是一个哑元参数,在tbb_stddef.h中的有其定义(一个空类):
class split {
};
TBB将在以下情况使用分割构造:
将一个区域(range)分为两个子区域(subrange)以便并行处理
将一个主体(body,即函数对象)分为两个主体以便并行处理
l 区域(range concept)
描述了一种集合类型的需求,这种集合可被递归分割。区域类型R必须满足以下需求:
| 原型 |
摘要 |
| R::R(const R& ) |
构造函数 |
| R::~R() |
析构函数 |
| bool R::empty() const |
区域为空返回ture |
| bool R::is_divisible() const |
如果区域可再分,返回ture |
| R::R(R& r, split) |
将r分为两个子区域 |
TBB内置了三种区域模板:
l template<typenameValue>
class blocked_range;
l template<typenameRowValue, typename ColValue>
class blocked_range2d;
l template<typenamePageValue, typename RowValue, typename ColValue>
class blocked_range3d;
blocked_range<Value>描述了一个能被递归分割的半开放区域[I,j)。
分割器(partitioner):
指定了循环模板将其任务分割后分配给各个线程的方式。循环模板(如parallel_for、parallel_reduce、parallel_scan)的默认行为只是尽量递归将区域分割以使所有的处理器处于繁忙状态,不一定分割的尽可能合适。如下表所示,可选的分割器参数允许指定其他的行为:
| 分割器 |
循环行为 |
| const auto_partitioner& (默认) |
按负载平衡进行分割,而不是真正依照Range::is_divisible的许可。当与类(比如blocked_range)一起使用时,选择一个合适的粒度也很重要。常规可接受的性能可以通过尺寸为1的默认粒度来达到。 |
| affinity_partitioner& |
与auto_partitioner类似,但通过选择映射子区域到工作线程提高缓存的亲缘性。当一个循环体在一个相同的数据集再次执行并且该数据集与缓存相符时,能显著提高性能。 |
| const simple_partitioner& |
递归分割一个区域,直到不能再分。何时终止递归分割由函数Range::is_devisible完全决定。当与blocked_range等类一起使用时,选择合适的可并发粒度在限制开销方面至关重要。 |