【Matlab编程】哈夫曼编码的Matlab实现
在前年暑假的时候,用C实现了哈夫曼编译码的功能,见文章《哈夫曼树及编译码》。不过在通信仿真中,经常要使用到Matlab编程,所以为了方便起见,这里用Matlab实现的哈夫曼编码的功能。至于哈夫曼编译码的基本原理,我们可以参考之前的文章《哈夫曼树及编译码》,里面有详细的说明及图解过程。下面直接给出具体的Matlab实现的哈夫曼编码函数,由于程序中注释还算比较详细,在此就不予与说明:
function [ h,e ] = Huffman_code( p )
%p为概率分布,此函数功能是进行哈夫曼编码
% 此处显示详细说明
% h为各个元素的麻子
% e为输出的平均码长
if length(find(p<0))~=0
error('概率不应该小于0!')
end
if abs(sum(p)-1)>10e-10
error('概率之和大于1,请检查输入!')
end
n=length(p);
p=sort(p)
q=p;
m=zeros(n-1,n);
for i=1:n-1
[q,e]=sort(q);
m(i,:)=[e(1:n-i+1),zeros(1,i-1)]; %由数组l 构建一个矩阵,该矩阵表明概率合并时的顺序,用于后面的编码
q=[q(1)+q(2),q(3:n),1];
end
for i=1:n-1
c(i,1:n*n)=blanks(n*n); %c 矩阵用于进行huffman 编码
end
c(n-1,n)='1'; %由于a 矩阵的第n-1 行的前两个元素为进行huffman 编码加和运算时所得的最后两个概率(在本例中为0.02、0.08),因此其值为0 或1
c(n-1,2*n)='0';
for i=2:n-1
c(n-i,1:n-1)=c(n-i+1,n*(find(m(n-i+1,:)==1))-(n-2):n*(find(m(n-i+1,:)==1))); %矩阵c 的第n-i 的第一个元素的n-1 的字符赋值为对应于a 矩阵中第n-i+1 行中值为1 的位置在c 矩阵中的编码值
c(n-i,n)='0';
c(n-i,n+1:2*n-1)=c(n-i,1:n-1); %矩阵c 的第n-i 的第二个元素的n-1 的字符与第n-i 行的第一个元素的前n-1 个符号相同,因为其根节点相同
c(n-i,2*n)='1';
for j=1:i-1
c(n-i,(j+1)*n+1:(j+2)*n)=c(n-i+1,n*(find(m(n-i+1,:)==j+1)-1)+1:n*find(m(n-i+1,:)==j+1));
%矩阵c 中第n-i 行第j+1 列的值等于对应于a 矩阵中第n-i+1 行中值为j+1 的前面一个元素的位置在c 矩阵中的编码值
end
end
for i=1:n
h(i,1:n)=c(1,n*(find(m(1,:)==i)-1)+1:find(m(1,:)==i)*n); %用h表示最后的huffman 编码
len(i)=length(find(abs(h(i,:))~=32)); %计算每一个编码的长度
end
e=sum(p.*len); %计算平均码长
在Matlab窗口中执行如下命令得到结果:
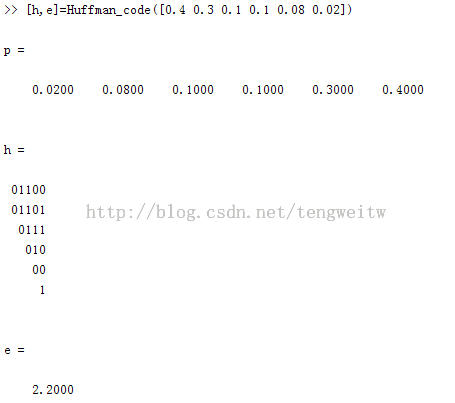
其中,p为权值,h表示和p中权值对应的编码,e代表平均码长。注意:哈夫曼编码的结果不唯一,它与左节点和右节点设置0 1 的方式有关。
原文:http://blog.csdn.net/tengweitw/article/details/45478497
作者:nineheadedbird