JavaSE第八十九讲:JavaIO流深入详解
1. Java I/O 系统课程目标
1)理解Java I/O系统
2) 熟练使用java.io包中的相关类与接口进行I/O编程
3) 掌握Java I/O的设计原则与使用的设计模式对程序语言设计者来说,设计一个令人满意的I/O(输入输出)系统,是件极艰巨的任务-----------------------摘自《Thinking in Java》
2.流类
1)流的概念
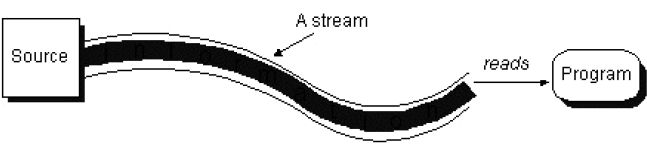
(1)Java程序通过流来完成输入/输出。流是生产或消费信息的抽象。流通过Java的输入/输出系统与物理设备[物理设备包括键盘,网络等]链接。尽管与它们链接的物理设备不尽相同,所有流的行为具有同样的方式。这样,相同的输入/输出类和方法适用于所有类型的外部设备。这意味着一个输入流能够抽象多种不同类型的输入:从磁盘文件,从键盘或从网络套接字。同样,一个输出流可以输出到控制台,磁盘文件或相连的网络。流是处理输入/输出的一个洁净的方法,例如它不需要代码理解键盘和网络的不同。Java中流的实现是在java.io包定义的类层次结构内部的。
2.输入/输出流概念
1)输入/输出时,数据在通信通道中流动。所谓“数据流(stream)”指的是所有数据通信通道之中,数据的起点和终点。信息的通道就是一个数据流。只要是数据从一个地方“流”到另外一个地方,这种数据流动的通道都可以称为数据流。
2) 输入/输出是相对于程序来说的。程序在使用数据时所扮演的角色有两个:一个是源,一个是目的。若程序是数据流的源,即数据的提供者,这个数据流对程序来说就是一个“输出数据流”(数据从程序流出)。若程序是数据流的终点,这个数据流对程序而言就是一个“输入数据流”(数据从程序外流向程序)[输入和输出是根据参照物你写的程序和你操纵的内存来的,数据从外部流到你的程序就是输入,从你的程序流到外部就是输出]
3. 输入/输出类
1) 在java.io包中提供了60多个类(流)。
2) 从功能上分为两大类:输入流和输出流。
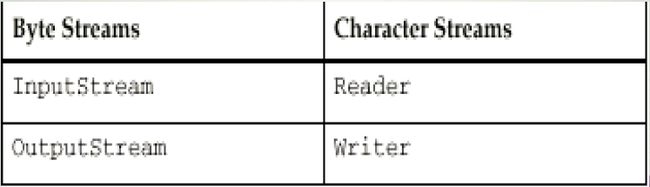
3) 从流结构上可分为字节流(以字节为处理单位或称面向字节)和字符流(以字符为处理单位或称面向字符)。
4) 字节流的输入流和输出流基础是InputStream和OutputStream这两个抽象类,字节流的输入输出操作由这两个类的子类实现。字符流是Java1.1版后新增加的以字符为单位进行输入输出处理的流,字符流输入输出的基础是抽象类Reader和Writer[注意不管是字节流还是字符流,他们底层都是用字节流来实现的,字符流就是在字节流的基础上做了一次封装,也就是直接操纵字符,而不需要对底层字节进行操作了]
4. 字节流和字符流 [流的第一种分类方式]
1)Java 2 定义了两种类型的流:字节流和字符流。字节流(byte stream)为处理字节的输入和输出提供了方便的方法。例如使用字节流读取或写入二进制数据。字符流(character stream)为字符的输入和输出处理提供了方便。它们采用了统一的编码标准,因而可以国际化。当然,在某些场合,字符流比字节流更有效
2)Java的原始版本(Java 1.0)不包括字符流,因此所有的输入和输出都是以字节为单位的。Java 1.1中加入了字符流的功能
3) 需要声明:在最底层,所有的输入/输出都是字节形式的。基于字符的流只为处理字符提供方便有效的方法4)字节流类(Byte Streams)字节流类用于向字节流读写8位二进制的字节。一般地,字节流类主要用于读写诸如图象或声音等的二进制数据。
5) 字符流类(Character Streams)字符流类用于向字符流读写16位二进制字符。
5. 流的分类 [流的第二种分类方式]
两种基本的流是:输入流(Input Stream)和输出流(Output Stream)。可从中读出一系列字节的对象称为输入流。而能向其中写入一系列字节的对象称为输出流。
1) 输入流: 读数据的逻辑为:
open a stream
while more information
read information
close the stream[打开流,判断这个流是否有更多信息,有的话继续读这个流,一直到没有了,关闭这个流]
2) 输出流: 写数据的逻辑为:
open a stream
while more information
write information
close the stream[打开流,判断这个流是否有更多信息,有的话继续写这个流,一直到没有了,关闭这个流]
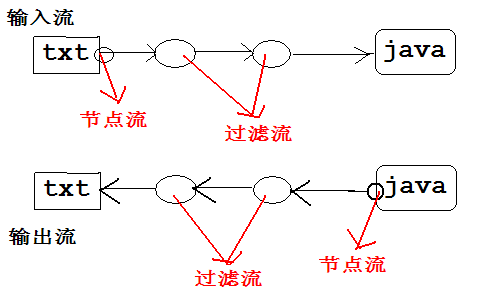
6. 节点流和过滤流[流的第三种分类方式]
节点流:从特定的地方读写的流类,例如:磁盘或一块内存区域。
过滤流:使用节点流作为输入或输出。过滤流是使用一个已经存在的输入流或输出流连接创建的。
[节点流总是与特定的目标打交道,而过滤流总是与节点流或者其他的过滤流打交道,画一个简单的例子如下图所示]

7. 字节流
1) 字节流类为处理字节式输入/输出提供了丰富的环境。一个字节流可以和其他任何类型的对象并用,包括二进制数据。这样的多功能性使得字节流对很多类型的程序都很重要。
2)字节流类以InputStream和OutputStream为顶层类,他们都是抽象类(abstract)
3) 抽象类InputStream和OutputStream定义了实现其他流类的关键方法。最重要的两种方法是read()和write(),它们分别对数据的字节进行读写。两种方法都在InputStream和OutputStream中被定义为抽象方法。它们被派生的流类重写。
4) 每个抽象类都有多个具体的子类,这些子类对不同的外设进行处理,例如磁盘文件,网络连接,甚至是内存缓冲区。
5) 要使用流类,必须导入java.io包
8.InputStream
1) 三个基本的读方法,如下图所示
abstractint read():读取一个字节数据,并返回读到的数据,如果返回-1,表示读到了输入流的末尾。
int read(byte[]b):将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。
int read(byte[]b, intoff, intlen):将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。off指定在数组b中存放数据的起始偏移位置;len指定读取的最大字节数。
2) 思考:为什么只有第一个read方法是抽象的,而其余两个read方法都是具体的?
因为两个具体的方法都是通过那个抽象的方法来去实现的。第二个read方法依靠第三个read方法来实现,而第三个read方法又依靠第一个read方法来实现,所以说只有第一个read方法是与具体的I/O设备相关的,它需要InputStream的子类来实现。
[这个子类可以好多个,比如可以处理文件的子类,也可以处理字节数组的子类,处理文件或者处理字节数组都是不一样的,所以不同的子类需要有不同的read()方法来实现的,这边我们可以查看read()方法的源代码。]
查看io.InputStream
public abstract int read() throws IOException;第一个read()抽象方法
public int read(byte b[]) throws IOException { return read(b, 0, b.length); }第二个read()方法,调用第三个的read()方法
public int read(byte b[], int off, int len) throws IOException { if (b == null) { throw new NullPointerException(); } else if (off < 0 || len < 0 || len > b.length - off) { throw new IndexOutOfBoundsException(); } else if (len == 0) { return 0; } int c = read();可以看出它也是依靠第一个read()方法来实现的。
程序demo:将c盘根目录下的hello.txt文件内容读到程序控制台里面
package com.ahuier.io2; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.InputStream; /* * 从外部文件读取数组到程序里面 * JDK 提供了类FileInputStream类,这个类继承InputStream,它是专门用来处理文件的读操作的。 */ public class InputStreamTest1 { /* * 读数据的逻辑流程,注意这是读数据的一种固定模式写法,希望我们自己会独立写出来 * open a stream * while more information * read information * close the stream */ public static void main(String[] args) throws Exception { /* * 查看JDK中,FileInputStream的构造方法,我们经常用以下两种 * FileInputStream(File file) 接受一个file对象,指向我们我读取的文件所对应的file对象 * FileInputStream(String name) 接受一个String 对象,接受文件所在的路径 * 这两种本质上一样 */ InputStream is = new FileInputStream("c:/hello.txt"); /* * 查看read()方法,我们使用最多的public int read(byte[] b, int off, int len) * 第一参数是字节数组,将外面的字节读取保存在这个数组里面 * 第二参数off 表示从目标文件哪个位置开始读取 * 第三个参数len 表示每次做多读取多少 * 方法返回 -1 表示程序读取完毕,否则的话会返回实际读取的自己数目 */ byte[] buffer = new byte[200]; //定义一个字节数组 buffer 来存储读取的字节,数组最多接受200个 int length = 0; //用来接受read()方法返回的值,或是 -1 或是实际读取的数目 //这边是每次最多读取200,实际读取的是length,最多的读取量是 <= buffer数组长度 while(-1 != (length = is.read(buffer, 0, 200))){ /* * 查看String类里面的构造方法,由字节数组装换为字符串的方法public String(byte[] bytes, int offset, int length) * 第一个参数目标字节数组,第二参数从哪个位置转,第三个参数每次转多少 * 注意这边每次转多少应该是实际的字节量 */ String str = new String(buffer, 0, length); System.out.println(str); } is.close(); } }编译执行结果:
3) 其它方法
long skip(longn):在输入流中跳过n个字节,并返回实际跳过的字节数。
int available(): 返回在不发生阻塞的情况下,可读取的字节数。
void close(): 关闭输入流,释放和这个流相关的系统资源。
void mark(intreadlimit):在输入流的当前位置放置一个标记,如果读取的字节数多于readlimit设置的值,则流忽略这个标记。
void reset(): 返回到上一个标记。
boolean markSupported():测试当前流是否支持mark和reset方法。如果支持,返回true,否则返回false。4) 该类的所有方法在出错条件下引发一个IOException 异常
通过打开一个到数据源(文件、内存或网络端口上的数据)的输入流,程序可以从数据源上顺序读取数据。