Storm (实时分布式大数据处理系统) 简介
相比Hadoop的批处理,Storm的特点就是实时性。
组件
Storm集群主要由一个主节点和一群工作节点(worker node)组成,通过 Zookeeper进行协调。主节点
主节点通常运行一个后台程序 —— Nimbus,用于响应分布在集群中的节点,分配任务和监测故障。这个很类似于Hadoop中的Job Tracker。
工作节点
工作节点叫worker,一般就是集群中的一个节点,也就是一个计算机。它同样会运行一个后台程序 ——Supervisor,用于收听工作指派并基于要求运行工作进程。每个工作节点都是topology中一个子集的实现。而Nimbus和Supervisor之间的协调则通过Zookeeper系统或者集群。
topology
[tə'pɒlədʒɪ]
topology是一组由Spouts(数据源)和Bolts(数据操作)通过Stream Groupings进行连接的图。也就是我们的整个应用程序。
Zookeeper
Zookeeper是完成Supervisor和Nimbus之间协调的服务。而应用程序实现实时的逻辑则被封装进Storm中的“topology”。
Spout
[spaʊt] n. 喷水口
简而言之,Spout从来源处读取数据并放入topology。Spout分成可靠和不可靠两种;当Storm接收失败时,可靠的Spout会对tuple(元组,数据项组成的列表)进行重发;而不可靠的Spout不会考虑接收成功与否只发射一次。而Spout中最主要的方法就是nextTuple(),该方法会发射一个新的tuple到topology,如果没有新tuple发射则会简单的返回。
Bolt
[bəʊlt] n.门闩
Topology中所有的处理都由Bolt完成。Bolt可以完成任何事,比如:连接的过滤、聚合、访问文件/数据库、等等。Bolt从Spout中接收数据并进行处理,如果遇到复杂流的处理也可能将tuple发送给另一个Bolt进行处理。而Bolt中最重要的方法是execute(),以新的tuple作为参数接收。不管是Spout还是Bolt,如果将tuple发射成多个流,这些流都可以通过declareStream()来声明。
并行参数
worker,进程数。
Executor,线程总数。
Task,具体的spout和bolt的实例个数。一个Executor可以负责1个或多个task。一般地,task数等于executor数。
tuple分组策略
分布式处理的主要思想就是把大的任务划分成多个子任务,它们在不同的机器或线程中并行处理,最后汇合。以统计班上同学的平均成绩为例,说明问题。
![]() bolt如何设计?
bolt如何设计?
因为分布式的原因,同一bolt类的多个线程之间不能有数据共享。分十个机器,编号为i的机器统计学号末尾为i的同学数和他们的总成绩,最后汇总。
![]() 如何控制每一个bolt实例接收哪些学号的数据呢?
如何控制每一个bolt实例接收哪些学号的数据呢?
结合上文,编号为i的bolt实例只接受学号末尾为i的数据。可以按照tuple的字段分组。
tuple传递是通过序列化,套接字传输,反序列化实现的。
所谓的grouping策略就是在Spout与Bolt、Bolt与Bolt之间传递Tuple的方式。总共有七种方式:
1)shuffleGrouping(随机分组)
2)fieldsGrouping(按照字段分组,在这里即是同一个单词只能发送给一个Bolt)
//declare与emit是一一对应的。
declarer.declareStream("http", new Fields("event", "key"));
collector.emit("http", new Values(new MyClass(), key));
//设置bolt的时候指定按照哪个字段散列
builder.setBolt("httpCount", new AnalyseBolt()).fieldsGrouping("XX", "http", new Fields("key"));
//接收到tuple时按指定字段取值
public void process(Tuple tuple, BasicOutputCollector collector) {
tuple.getValueByField("event") instanceof MyClass
}
3)allGrouping(广播发送,即每一个Tuple,每一个Bolt都会收到)
4)globalGrouping(全局分组,将Tuple分配到task id值最低的task里面)
5)noneGrouping(随机分派)
6)directGrouping(直接分组,指定Tuple与Bolt的对应发送关系)
7)Local or shuffle Grouping
8)customGrouping (自定义的Grouping)
消息可靠性交付
要理解这个问题,需要看一下tuple在离开spout之后的生命周期。作为参考,下面是spout实现的接口
public interface ISpout extendsSerializable {
void open(Map conf, TopologyContext context,SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
首先,Storm会通过Spout的 nextTuple()方法从Spout申请一个tuple。在open方法中,Spout使用此方法提供的SpoutOutputCollector去发射一个tuple到输出streams中去。当发射一个tuple时,Spout会提供一个“message id”,用来后面区分不同的tuple。例如, KestrelSpout从kestrel队列中读取消息,然后在发射时会将Kestrel为消息提供的id作为“message id”。发射一条消息到SpoutOutputCollector,如下所示:
_collector. emit(newValues("field1", "field2", 3), msgId);
然后,这个tuple会发送到消费bolts,同时Storm会跟踪已被创建的消息树状图。如果Storm检测到一个tuple已被“fully processed”, Storm将会原始的Spout task(即发射这个tuple的Spout)上调用ack()方法,参数msgId就是这个Spout提供给Storm的“message id”。类似的,如果这个tuple超时了, Storm会在原始的Spout task上调用fail()方法。注意, 一个tuple只能被创建它的Spouttask进行acked或者failed。因此,即使一个Spout在集群上正在执行很多tasks,一个tuple也只能被创建它的task进行acked或failed,而其他的task则不行。
storm UI
storm自带的一个仪表盘,见图1.
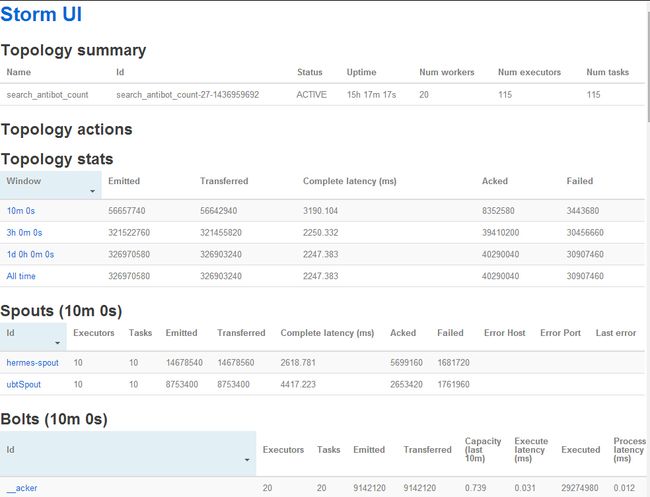
图1 storm自带的一个仪表盘
emitted,发射的tuple数。
transferred,若一个tuple被其他bolt读取,则transferred+1。
acked,tuple被完整处理。
failed,在处理过程中出现错误或超时的tuple数。超时参数可以设置。