hadoop学习笔记-5-最高气温示例MaxTemperature
学会了基本的配置,我们运行一下Hadoop in action中的第一个示例,求各年度的最高气温
编写步骤
1. 创建Mapreduce应用
2. 编写代码(见代码部分)
3. 上传原始数据文件(数据可以从这里下载:http://download.csdn.net/detail/fufengrui/4722996)
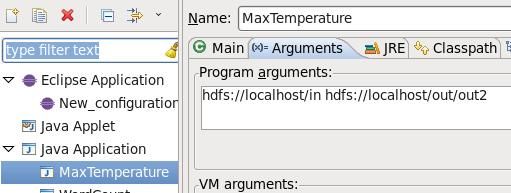
4. 配置运行参数
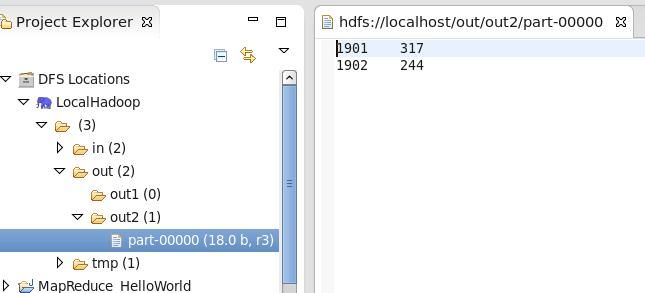
5. 运行程序
注意:
1. 运行程序前需要启动hadoop,将数据传入hdfs中,使用命令或者eclipse中直接操作都行。命令是:hadoop fs –copyFromLocal *** /in,或者直接在eclipse中右击左侧导航的HDFS进行上传。
2. 如果出现:由于是safemode,不能写入数据的异常的时候,执行以下命令:
hadoop dfsadmin -safemodeleave
源代码
Mapper类:
package cn.kepu.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
@SuppressWarnings("deprecation")
public class MaxTemperatureMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException{
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if(line.charAt(87) == '+'){
airTemperature = Integer.parseInt(line.substring(88, 92));
}else{
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if(airTemperature != MISSING && quality.matches("[01459]")){
output.collect(new Text(year), new IntWritable(airTemperature));
}
}
}
Reducer类:
package cn.kepu.hadoop;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
@SuppressWarnings("deprecation")
public class MaxTemperatureReducer extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int maxValue = Integer.MIN_VALUE;
while(value.hasNext()){
maxValue = Math.max(maxValue, value.next().get());
}
output.collect(key, new IntWritable(maxValue));
}
}
Main类:
package cn.kepu.hadoop;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
public class MaxTemperature{
@SuppressWarnings("deprecation")
public static void main(String[] args) throws IOException{
if(args.length != 2){
System.err.println("Usage : MaxTemperature <input path><output path>");
System.exit(-1);
}
JobConf conf = new JobConf(MaxTemperature.class);
conf.setJobName("max temperature");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setMapperClass(MaxTemperatureMapper.class);
conf.setReducerClass(MaxTemperatureReducer.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
JobClient.runJob(conf);
}
}