hadoop学习笔记-4-eclipse运行MapReduce
Eclipse安装
1. 下载eclipse安装包:eclipse-SDK-4.2.1-Linux.tar.gz
2. 解压到指定目录:例如/usr/local
3. 运行./eclipse即可
使用Eclipse开发MapReduce程序
1. 将hadoop安装目录的contribute/eclipse-plugin中的jar包拷贝至eclipse安装目录下的plugins中
2. 重新启动eclipse
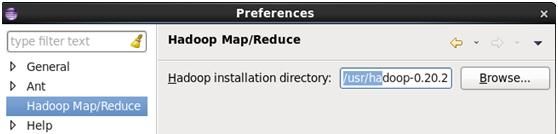
3. 在Windows-preference中有Hadoop-MapReduce的配置路径,配置其中的hadoop安装目录,点击ok
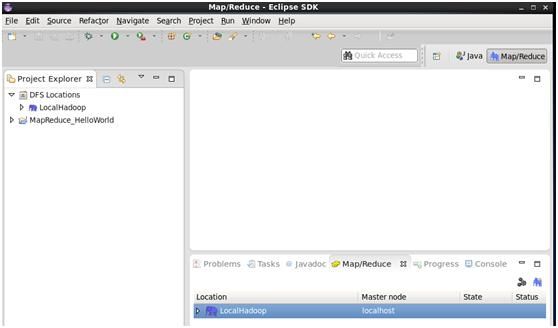
4. 配置MapReduce,选择map/reduce视图,选择下方的MapReduce这个栏目,选中大象,右击,编辑,其中DFSMaster配置对应于hadoop配置文件的core-site.xml,MapReduct Master配置对应于map-red-core.xml中配置的端口信息,下方的User name用于免账号ssh登录时候的用户名。
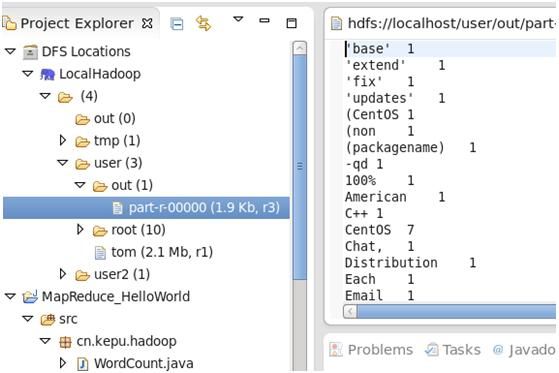
5. 点击确定之后,可以在eclipse的左侧导航看到文件系统中的目录和文件。

注意:
1. 如果不能看到文件系统中的文件,尝试以下步骤,重新格式化文件系统:
stop-all.sh,hadoop namenode –format,start-all.sh
(伪分布式环境,每次重新启动系统的时候需要重新格式化文件系统,否则会出现链接失败的情况,Call to localhost/127.0.0.1:8021 failed on connection exception:java net ConnectException)
Eclipse运行hadoop程序
需要注意MapReduct程序都是对文件系统中的文件进行操作,所以一般在运行的时候需要将文件拷贝至hdfs,并且指定运行参数(比如输入和输出目录)。
1. 新建Project – MapReduct Project
2. 创建包和类
3. 将hadoop安装目录中的wordcount程序内容拷贝过来(安装目录/src/examples/中)
4. 右击要运行的类,Run—Run Configuration,配置输入和输出目录
5. 指定输入目录和输出目录,下图所示。
6. 其中其中的hdfs://localhost是在core-site.xml配置文件的里定义的fs.default.name的值,下图表示输入目录为in2,输入目录为out

运行结果: