Python pickle模块学习
pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。
------------------------------------------
pickle.dump(obj, file[, protocol])
序列化对象,并将结果数据流写入到文件对象中。参数protocol是序列化模式,默认值为0,表示以文本的形式序列化。protocol的值还可以是1或2,表示以二进制的形式序列化。
------------------------------------------
pickle.load(file)
反序列化对象。将文件中的数据解析为一个Python对象。
其中要注意的是,在load(file)的时候,要让python能够找到类的定义,否则会报错:
比如下面的例子
import pickle
class Person:
def __init__(self,n,a):
self.name=n
self.age=a
def show(self):
print self.name+"_"+str(self.age)
aa = Person("JGood", 2)
aa.show()
f=open('d:\\p.txt','w')
pickle.dump(aa,f,0)
f.close()
#del Person
f=open('d:\\p.txt','r')
bb=pickle.load(f)
f.close()
bb.show()
如果不注释掉del Person的话,那么会报错如下:
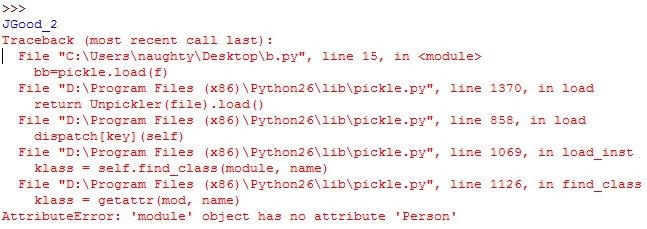
意思就是当前模块找不到类的定义了。
--------------------------------------------------
clear_memo()
清空pickler的“备忘”。使用Pickler实例在序列化对象的时候,它会“记住”已经被序列化的对象引用,所以对同一对象多次调用dump(obj),pickler不会“傻傻”的去多次序列化。
看下面的例子:
import StringIO
import pickle
class Person:
def __init__(self,n,a):
self.name=n
self.age=a
def show(self):
print self.name+"_"+str(self.age)
aa = Person("JGood", 2)
aa.show()
fle = StringIO.StringIO()
pick = pickle.Pickler(fle)
pick.dump(aa)
val1=fle.getvalue()
print len(val1)
pick.clear_memo()
pick.dump(aa)
val2=fle.getvalue()
print len(val2)
fle.close()
上面的代码运行如下:

如果不注释掉,则运行结果是第一个。如果注释掉,那么运行结果是第二个。
主要是因为,python的pickle如果不clear_memo,则不会多次去序列化对象。