Spark 1.5.0 远程调试
Spark 1.5.0 远程调试
作者:摇摆少年梦
微信号:zhouzhihubeyond
先决条件
- 已安装好Spark集群,本例子中使用的是spark-1.5.0. 安装方法参见:http://blog.csdn.net/lovehuangjiaju/article/details/48494737
- 已经安装好Intellij IDEA,本例中使用的是Intellij IDEA 14.1.4,具体安装方法参见:http://blog.csdn.net/lovehuangjiaju/article/details/48577281
远程调试过程描述
打开Intellij IDEA,File->New ->Project
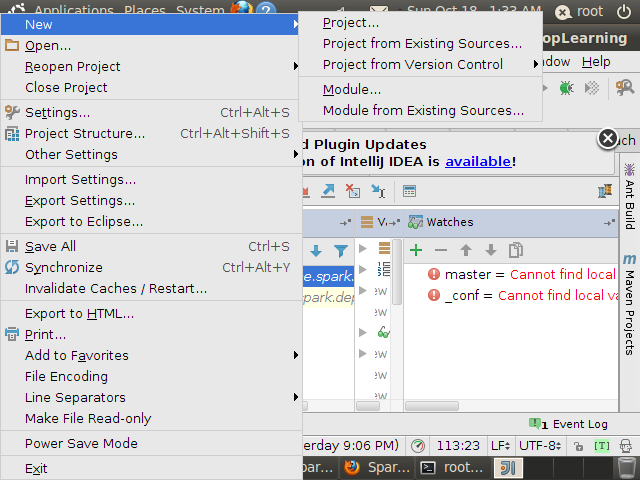
选择Scala,然后next
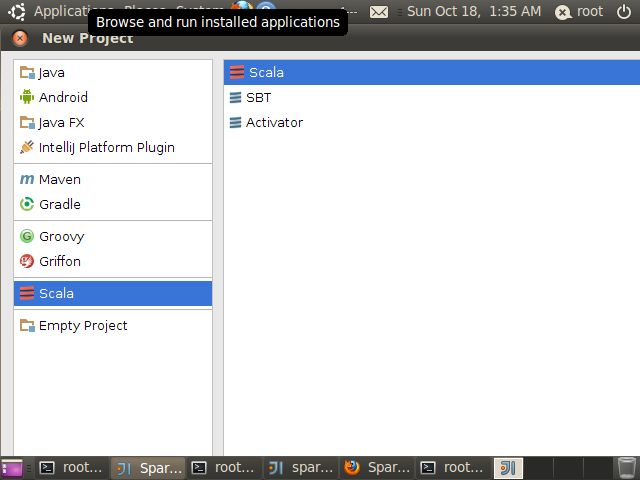
配置好JDK、Scala版本,填入项目名称,然后Finish

4.导入spark-assembly-1.5.0-hadoop2.4.0.jar
File->Prject Structure->Library


点”+”号->选择JAVA
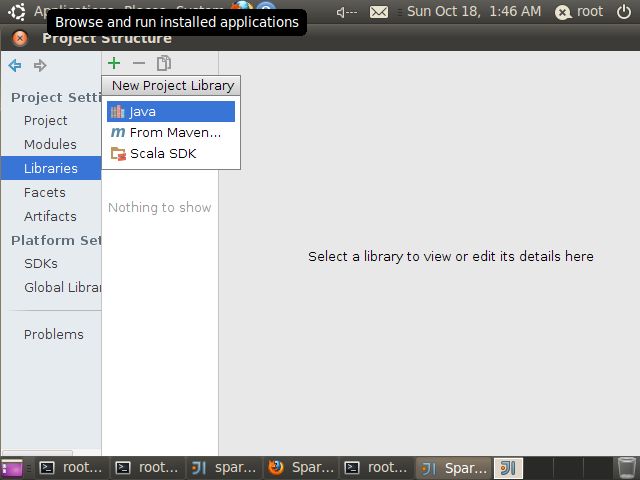
找到spark-1.5.0安装目录,选择spark-assembly-1.5.0-hadoop2.4.0.jar,我的机器上jar包目录为
/hadoopLearning/spark-1.5.0-bin-hadoop2.4/lib/spark-assembly-1.5.0-hadoop2.4.0.jar,然后Finish


最后点击“OK”完成导入
5.关联spark-1.5.0源代码
在Extended Library中展开spark-assembly-1.5.0-hadoop2.4.0.jar
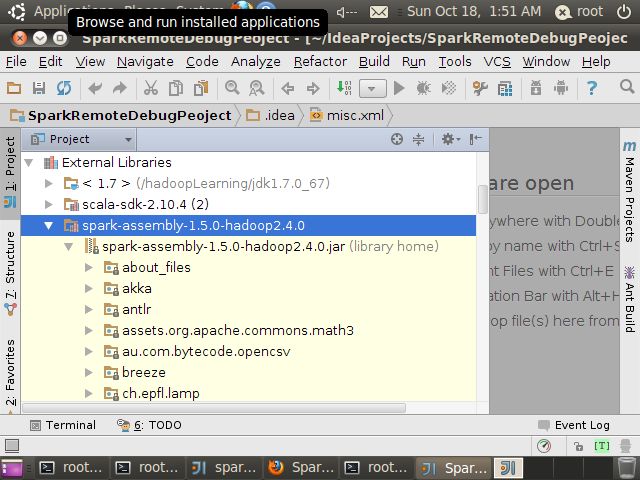
找到org->apache->spark
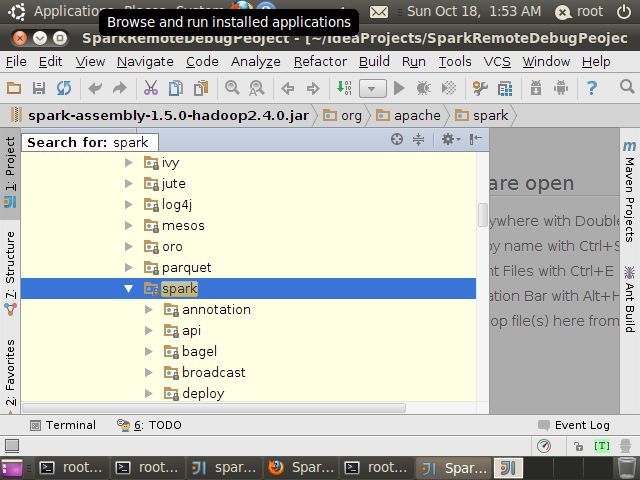
点开下面包中的任意源文件,我在本机上选择”SparkContext.class”文件,默认情况下Intellij IDEA会为我们反编译.class文件,但源码里面没有注释,可以选择右上角的”Attach Sources”
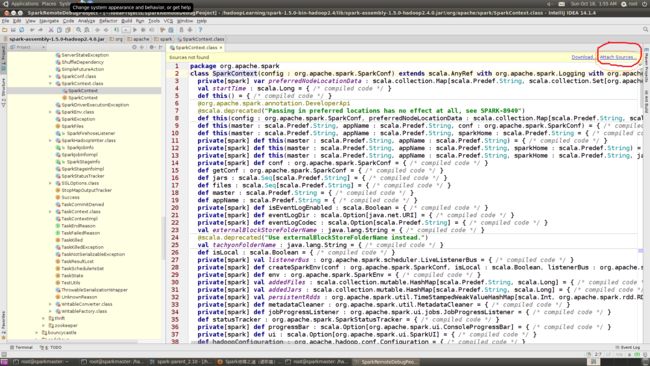
选择源码文件目录,我的机器上源码解压在/hadoopLearning/spark-1.5.0目录,完成后“OK”
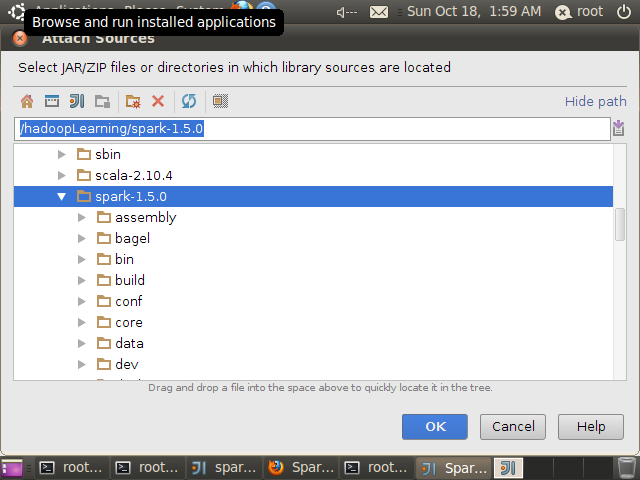
完成后会提示根目录
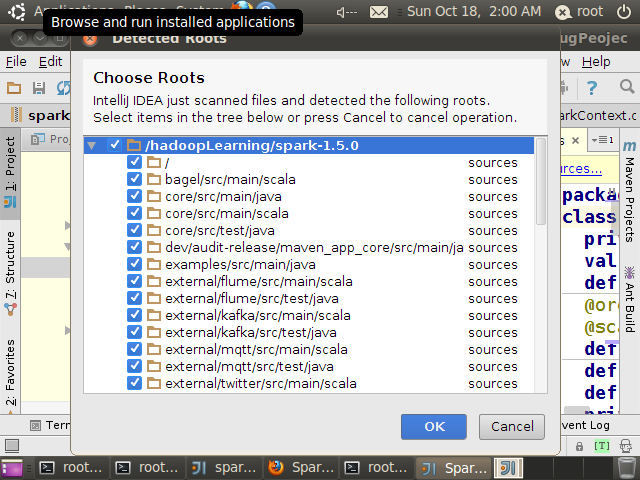
全部选择后点击“OK”,此时显示的不是反编译后的代码,而是关联源代码后的代码,你会发现多了很多注释
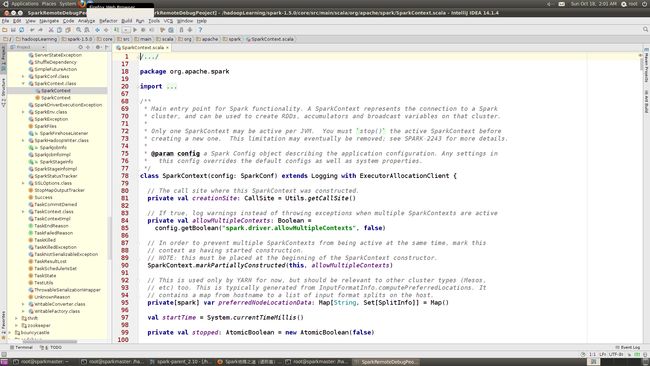
至此源码阅读环境构建完毕。
6.启动spark-1.5.0集群
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/sbin# ./start-all.sh
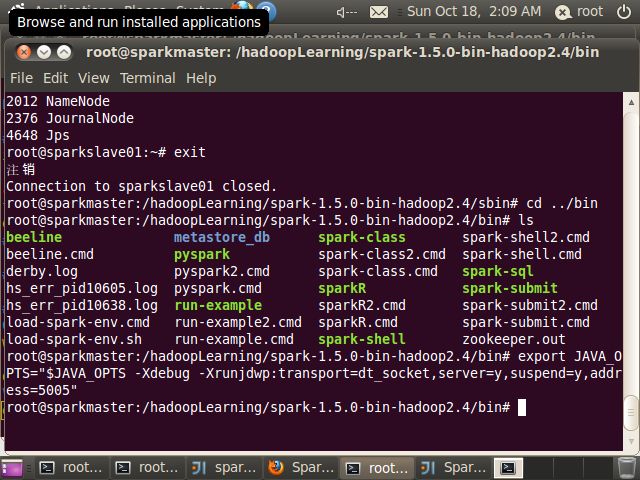
7.修改spark-class脚本
本机器上的spark-class脚本位于/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin目录
将脚本中的内容
done < <("$RUNNER" -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@")修改为
done < <("$RUNNER" -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main $JAVA_OPTS "$@")
然后在命令行中执行下列语句
export JAVA_OPTS="$JAVA_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005"
- 创建用于测试的Spark应用程序
选择项目中的src文件,然后右键 New->Scala Class
然后选择Object
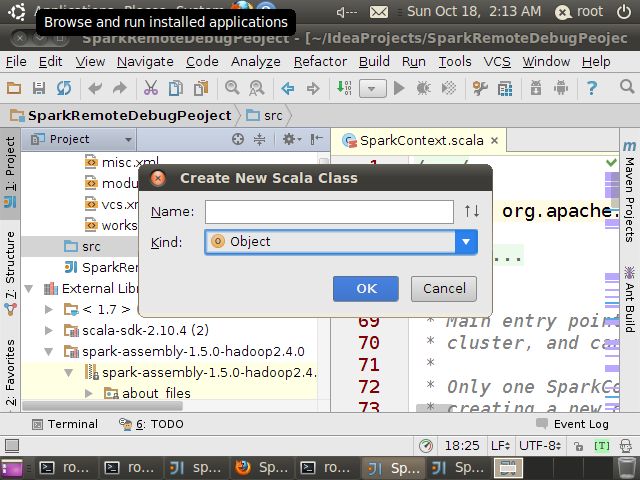
命名为SparkWordCount,然后点击OK,输入如下内容
import org.apache.spark.SparkContext._
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount{
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SparkWordCount <inputfile> <outputfile>")
System.exit(1)
}
val conf = new SparkConf().setAppName("SparkWordCount")
val sc = new SparkContext(conf)
val file=sc.textFile("file:///hadoopLearning/spark-1.5.1-bin-hadoop2.4/README.md")
val counts=file.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.reduceByKey(_+_)
counts.saveAsTextFile("file:///hadoopLearning/spark-1.5.1-bin-hadoop2.4/countReslut.txt")
}
}9 将Spark应用程序打包
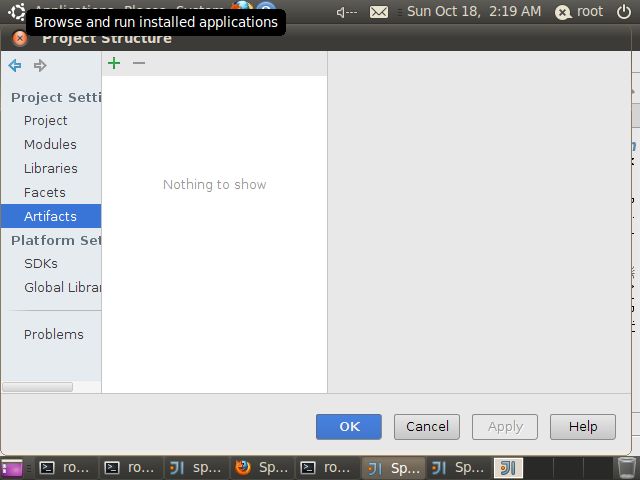
选择项目,File->Project Structure

选择 Artifacts
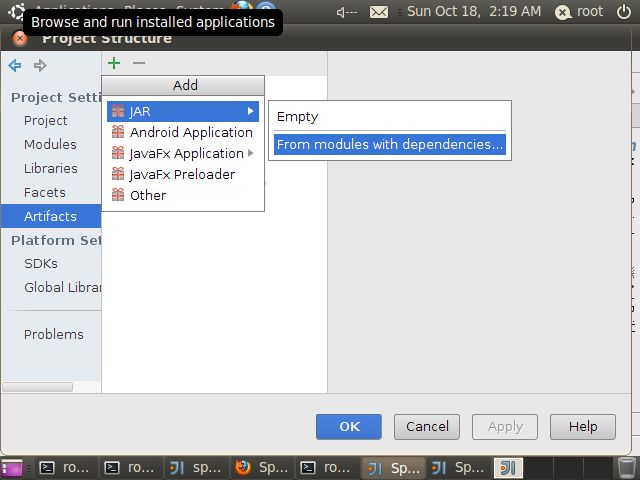
点击“+”号,然后选择”Jar”->”From modules with dependencies”
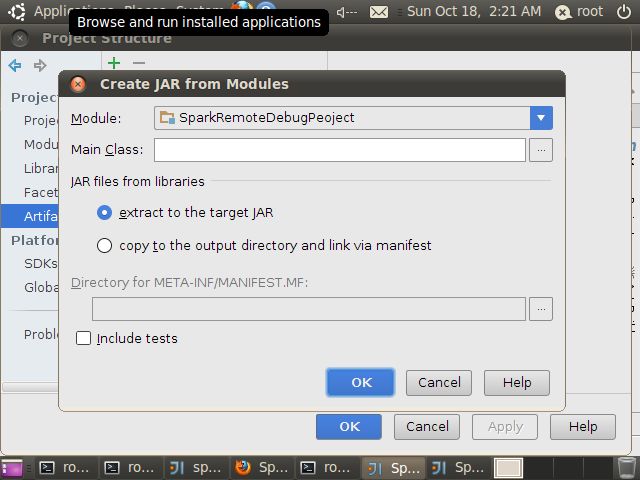
选择SparkWordCount作为MainClass


Spark应用程序在运行是会自动加载spark-assembly-1.5.0-hadoop2.4.0.jar等jar包,为减少后期Jar包的体积,可以将spark-assembly-1.5.0-hadoop2.4.0.jar等jar包删除,这样打包时不会被打包进去。

完成后点击”OK”
再选择”Build”->”Build Artifacts”

Action中选择“Build”
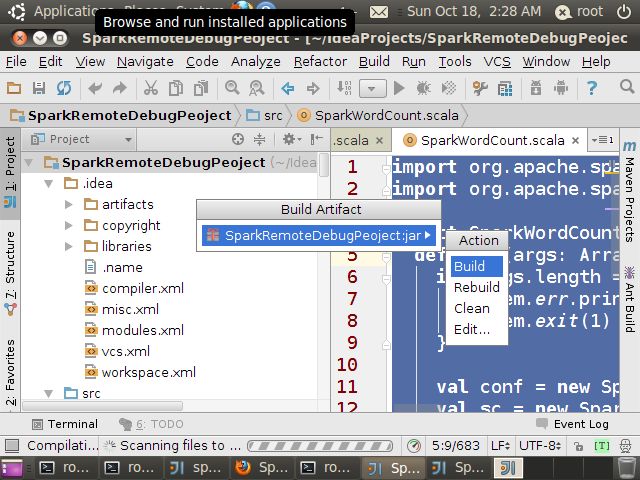
编译后在对应目录中可以看到生成的jar包文件,本机器上的目录是:
/root/IdeaProjects/SparkRemoteDebugPeoject/out/artifacts/SparkRemoteDebugPeoject_jar

10 将代码利用spark-submit提交到集群
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin# ./spark-submit --master spark://sparkmaster:7077 --class SparkWordCount --executor-memory 1g /root/IdeaProjects/SparkRemoteDebugPeoject/out/artifacts/SparkRemoteDebugPeoject_jar hdfs://ns1/README.md hdfs://ns1/SparkWordCountResult
//注意这一行语句
Listening for transport dt_socket at address: 5005
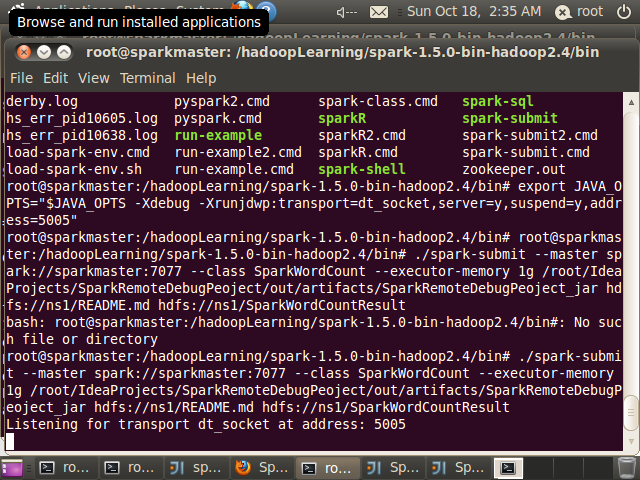
11 Intellij IDEA中配置远程调试
Run->Edit Configuration
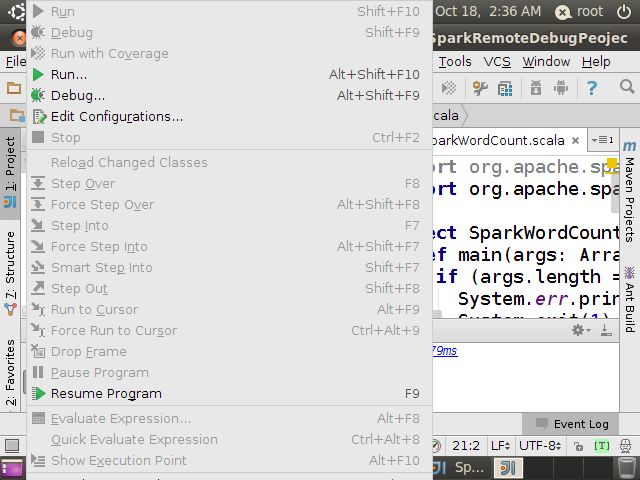
找到Remote

点击”+“号,命名为Spark_Remote_Debug,其它配置默认,Intellij IDEA已为我们默认配置
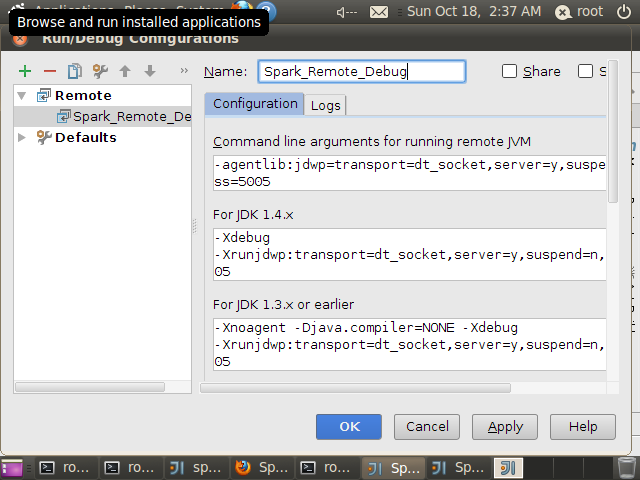
完成后,点击OK
12 正式启动远程调试
在源码中设置断点,本例中选择在SparkSubmit.scala文件中设置断点

然后按 F9

选择Spark_Remote_Debug
Spark控制台出现:Connected to the target VM, address: ‘localhost:5005’, transport: ‘socket’,如下图

在Debugger上可以看到
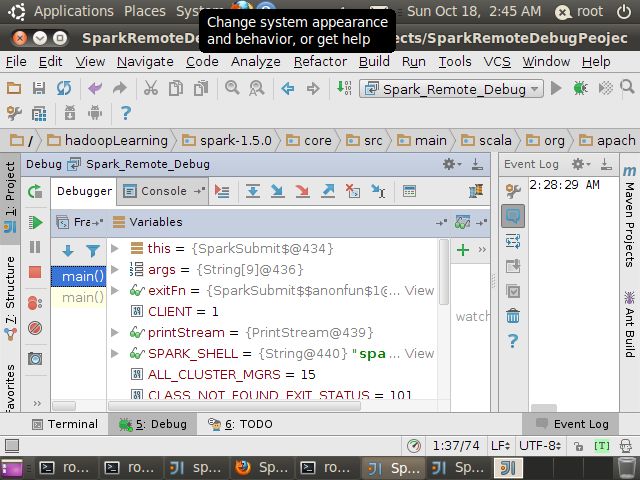
程序在运行SparkSubmit源码中设置断点处
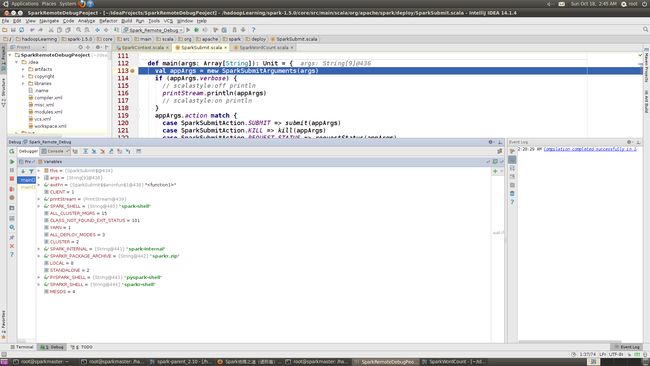
至此,远程调试正式开始,请畅游Spark源代码吧
最后说明一下调试参数:
参见:http://www.thebigdata.cn/QiTa/12370.html
-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005 参数说明:
-Xdebug 启用调试特性 -Xrunjdwp 启用JDWP实现,包含若干子选项: transport=dt_socket JPDA front-end和back-end之间的传输方法。dt_socket表示使用套接字传输。
address=5005 JVM在5005端口上监听请求,这个设定为一个不冲突的端口即可。
server=y y表示启动的JVM是被调试者。如果为n,则表示启动的JVM是调试器。
suspend=y y表示启动的JVM会暂停等待,直到调试器连接上才继续执行。suspend=n,则JVM不会暂停等待。