内存管理-高端内存
进程可以寻址4G,其中0~3G为用户态,3G~4G为内核态。如果内存不超过1G那么最后这1G线性空间足够映射物理内存了,如果物理内存大于1G,为了使内核空间的1G线性地址可以访问到大于1G的物理内存,把物理内存分为两部分,0~896MB的进行直接内存映射,也就是说存在一个线性关系:virtual address = physical address + PAGE_OFFSET,这里的PAGE_OFFSET为3G。还剩下一个128MB的空间,这个空间作为一个窗口动态进行映射,这样就可以访问大于1G的内存,但是同一时刻内核空间还是只有1G的线性地址,只是不同时刻可以映射到不同的地方。综上,大于896MB的物理内存就是高端内存,内核引入高端内存这个概念是为了通过128MB这个窗口访问大于1G的物理内存。
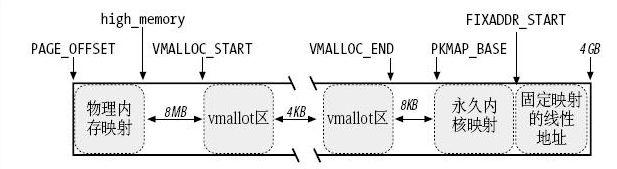
上图是内核空间1G线性地址的布局,直接映射区为PAGE_OFFSET~PAGE_OFFSET+ 896MB,直接映射的物理地址末尾对应的线性地址保存在high_memory变量中。直接映射区后边有一个8MB的保护区,目的是用来"捕获"对内存的越界访问。然后是非连续内存区,范围从VMALLOC_START~VMALLOC_END,出于同样的原因,每个非连续内存区之间隔着4KB。永久内核映射区从PKMAP_BASE开始,大小为2MB(启动PAE)或4MB。后边是固定映射区,范围是FIXADDR_START~FIXADDR_TOP,至于临时内核映射区是永久内核映射区里的一部分,在后边会做详细解析。
下边来详细介绍高端内存的三种访问方式:非连续内存区访问,永久内核映射,临时内核映射。
非连续内存区访问:
非连续内存区访问会使用一个vm_struct结构来描述每个非连续内存区:
- struct vm_struct {
- void *addr; //内存区内第一个内存单元的线性地址
- unsigned long size; //内存区的大小加4096(内存区之间的安全区间的大小)
- unsigned long flags; //非连续的内存区映射的内存类型
- struct page **pages; //指向nr_pages数组的指针,该数组由指向页描述符的
- //指针组成
- unsigned int nr_pages; //内存区填充的页的个数
- unsigned long phys_addr; //该字段为0,除非内存已被创建来映射一个硬件设备的
- //I/O共享内存
- struct vm_struct *next; //指向下一个vm_struct结构的指针
- };
vm_struct与vmalloc()分配的非连续线性区有如下关系:
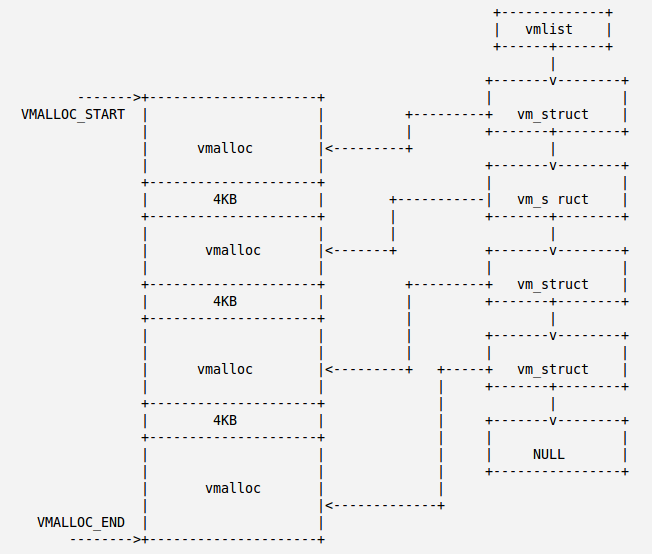
下边来看非连续内存区的分配,分配调用了vmalloc()函数:
- void *vmalloc(unsigned long size)
- {
- return __vmalloc(size, GFP_KERNEL | __GFP_HIGHMEM, PAGE_KERNEL);
- }
flags标志中设置了从high memory分配。
- void *__vmalloc(unsigned long size, int gfp_mask, pgprot_t prot)
- {
- struct vm_struct *area;
- struct page **pages;
- unsigned int nr_pages, array_size, i;
- /*需要分配的大小页对齐*/
- size = PAGE_ALIGN(size);
- /*需要分配的大小不能为0,也不能大于物理页的总数量*/
- if (!size || (size >> PAGE_SHIFT) > num_physpages)
- return NULL;
- /*找到一个线性区,并获得vm_struct描述符,描述符的flags字段被初始化为VM_ALLOC标志,
- 该标志意味着通过使用vmalloc()函数*/
- area = get_vm_area(size, VM_ALLOC);
- if (!area)
- return NULL;
- /*需要分配页的数量*/
- nr_pages = size >> PAGE_SHIFT;
- /*数组的大小*/
- array_size = (nr_pages * sizeof(struct page *));
- area->nr_pages = nr_pages;
- /* Please note that the recursion is strictly bounded. */
- /*如果数组的大小大于页的大小就从非连续内存区分配,否则从kmalloc分配*/
- if (array_size > PAGE_SIZE)
- pages = __vmalloc(array_size, gfp_mask, PAGE_KERNEL);
- else
- pages = kmalloc(array_size, (gfp_mask & ~__GFP_HIGHMEM));
- area->pages = pages;
- /*如果这个数组没有分配到内存,就释放vm_struct描述符,返回*/
- if (!area->pages) {
- remove_vm_area(area->addr);
- kfree(area);
- return NULL;
- }
- /*清空*/
- memset(area->pages, 0, array_size);
- /*从高端内存非配每一个物理页,将描述符的pages字段的每一项指向得到的物理页的page结构*/
- for (i = 0; i < area->nr_pages; i++) {
- area->pages[i] = alloc_page(gfp_mask);
- if (unlikely(!area->pages[i])) {
- /* Successfully allocated i pages, free them in __vunmap() */
- area->nr_pages = i;
- goto fail;
- }
- }
- /*建立页表与物理页之间的映射,一级一级的很复杂*/
- if (map_vm_area(area, prot, &pages))
- goto fail;
- return area->addr;
- fail:
- vfree(area->addr);
- return NULL;
- }
1. 调用kmalloc()为vm_struct类型的新描述符获得一个内存区。
2. 为写得到vmlist_lock()锁,并扫描类型为vm_struct的描述符链表来查找线性地址一个空闲区域,至少覆盖size + 4096个地址。
3. 如果存在这样一个区间,函数就初始化描述符的字段,释放vmlist_lock锁,并以返回这个非连续内存区的起始地址而结束。
4. 否则,get_vm_area()释放先前得到的描述符,释放vmlist_lock,然后返回NULL。
调用map_vm_area()建立页表与物理页之间的映射:
- int map_vm_area(struct vm_struct *area, pgprot_t prot, struct page ***pages)
- {
- unsigned long address = (unsigned long) area->addr;
- unsigned long end = address + (area->size-PAGE_SIZE);
- unsigned long next;
- pgd_t *pgd;
- int err = 0;
- int i;
- /*得到主内核页表中pgd中的相应项的线性地址*/
- pgd = pgd_offset_k(address);
- /*获得主内核页表自旋锁*/
- spin_lock(&init_mm.page_table_lock);
- for (i = pgd_index(address); i <= pgd_index(end-1); i++) {
- /*调用pud_alloc分配页上级目录*/
- pud_t *pud = pud_alloc(&init_mm, pgd, address);
- if (!pud) {
- err = -ENOMEM;
- break;
- }
- /*跨越一个pgd所对应内存的大小*/
- next = (address + PGDIR_SIZE) & PGDIR_MASK;
- if (next < address || next > end)
- next = end;
- /*建立这个页上级目录所对应的所有页中间目录*/
- if (map_area_pud(pud, address, next, prot, pages)) {
- err = -ENOMEM;
- break;
- }
- address = next;
- pgd++;
- }
- spin_unlock(&init_mm.page_table_lock);
- flush_cache_vmap((unsigned long) area->addr, end);
- return err;
- }
map_area_pud也就是反复调用map_area_pmd来填充各级页目录,页表。map_area_pte()的主循环如下:
- do {
- struct page *page = **pages;
- WARN_ON(!pte_none(*pte));
- if (!page)
- return -ENOMEM;
- set_pte(pte, mk_pte(page, prot));
- address += PAGE_SIZE;
- pte++;
- (*pages)++;
- } while (address < end);
调用set_pte设置将相应页的页描述符地址设置到相应的页表项。非连续内存区的释放:
- #define mk_pte(page, pgprot) pfn_pte(page_to_pfn(page), (pgprot))
- #define pfn_pte(pfn, prot) __pte(((pfn) << PAGE_SHIFT) | pgprot_val(prot))
- #define set_pte(pteptr, pteval) (*(pteptr) = pteval)
非连续内存区的释放:
调用vfree()函数:
- void vfree(void *addr)
- {
- BUG_ON(in_interrupt());
- __vunmap(addr, 1);
- }
- do {
- pte_t page;
- page = ptep_get_and_clear(pte);
- address += PAGE_SIZE;
- pte++;
- if (pte_none(page))
- continue;
- if (pte_present(page))
- continue;
- printk(KERN_CRIT "Whee.. Swapped out page in kernel page table\n");
- } while (address < end);
注意,在调用vmalloc()时建立的映射是在物理内存和主内核页表之间的,并没有涉及到进程的页表。当内核态的进程访问非连续内存区时,缺页发生,因为该内存区所对应的进程页表中的表项为空。然而,缺页处理程序要检查这个缺页线性地址是否在主内核页表中。一旦处理程序发现一个主内核页表含有这个线性地址的非空项,就把它的值拷贝到相应的进程页表项中,并恢复进程的正常执行。在调用vfree时,与vmalloc()一样,内核修改主内核页全局目录和它的子页表中相应的项,但是映射第4个GB的进程页表的项保持不变。unmap_area_pte()函数只是清除页表中的项(不回收页表本身)。进程对已释放非连续内存区的进一步访问必将由于空的页表项而触发缺页异常。
永久内核映射:
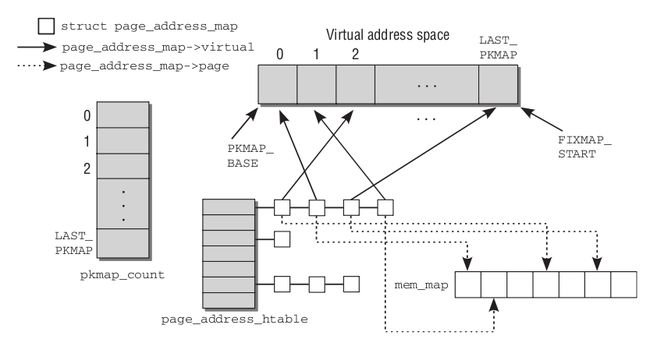
永久内核映射使用主内核页表中一个专门的页表,其地址存放在pkmap_page_table变量中,页表中的表项数由LAST_PKMAP宏产生,因此内核一次访问2MB(启动PAE)或4MB的高端内存。该页表映射的线性地址从PKMAP_BASE开始,pkmap_count数组包含LAST_PKMAPGE个计数器,pkmap_page_table页表中每一项都有一个。
计数器为0
对应的页表项没有映射任何高端内存页框,并且是可用的。
计数器为1
对应的页表项没有映射任何高端内存页框,但是它不能使用,因为此从他最后一次使用以来,其相应的TLB表项还未被刷新。
计数器为2
相应的页表项映射一个高端内存页框,这意味着正好有n-1个内核成分在使用这个页框。
- struct page_address_map {
- struct page *page;
- void *virtual;
- struct list_head list;
- };
- static struct page_address_slot {
- struct list_head lh; /* List of page_address_maps */
- spinlock_t lock; /* Protect this bucket's list */
- } ____cacheline_aligned_in_smp page_address_htable[1<<PA_HASH_ORDER];<span style="font-family: Arial, Verdana, sans-serif; font-size: 18px; white-space: normal; "> </span>
- static struct page_address_slot *page_slot(struct page *page)
- {
- return &page_address_htable[hash_ptr(page, PA_HASH_ORDER)];
- }
为了记录高端内存页框与永久内核映射的线性地址之间的联系,内核使用了page_address_htable散列表,该表包含一个page_address_htable结构,该表包含一个page_address_map数据结构,用于为高端内存每一个页框进行当前映射。而该数据结构还包含一个指向页描述符的指针和分配给该页框的线性地址。page是一个指向全局mem_map数组中的page实例的指针,virtual指定了该页在内核虚拟地址空间中分配的位置。为了便于组织,映射保存在散列表中,结构中的链表元素用于建立溢出的链表,以处理散列碰撞。散列表为page_address_htable,散列函数是page_slot,根据page实例确定页的虚拟地址。如果page是在普通内存中的,则根据page在mem_map数组中的位置计算。
进行永久内核映射需要调用kmap()函数:
- void *kmap(struct page *page)
- {
- might_sleep();
- if (!PageHighMem(page))
- return page_address(page);
- return kmap_high(page);
- }
- void fastcall *kmap_high(struct page *page)
- {
- unsigned long vaddr;
- /*
- * For highmem pages, we can't trust "virtual" until
- * after we have the lock.
- *
- * We cannot call this from interrupts, as it may block
- */
- spin_lock(&kmap_lock);
- vaddr = (unsigned long)page_address(page);
- if (!vaddr)
- vaddr = map_new_virtual(page);
- pkmap_count[PKMAP_NR(vaddr)]++;
- if (pkmap_count[PKMAP_NR(vaddr)] < 2)
- BUG();
- spin_unlock(&kmap_lock);
- return (void*) vaddr;
- }
- static inline unsigned long map_new_virtual(struct page *page)
- {
- unsigned long vaddr;
- int count;
- start:
- count = LAST_PKMAP;
- /* Find an empty entry */
- for (;;) {
- last_pkmap_nr = (last_pkmap_nr + 1) & LAST_PKMAP_MASK;
- if (!last_pkmap_nr) {
- flush_all_zero_pkmaps();
- count = LAST_PKMAP;
- }
- if (!pkmap_count[last_pkmap_nr])
- break; /* Found a usable entry */
- if (--count)
- continue;
- /*
- * Sleep for somebody else to unmap their entries
- */
- {
- DECLARE_WAITQUEUE(wait, current);
- __set_current_state(TASK_UNINTERRUPTIBLE);
- add_wait_queue(&pkmap_map_wait, &wait);
- spin_unlock(&kmap_lock);
- schedule();
- remove_wait_queue(&pkmap_map_wait, &wait);
- spin_lock(&kmap_lock);
- /* Somebody else might have mapped it while we slept */
- if (page_address(page))
- return (unsigned long)page_address(page);
- /* Re-start */
- goto start;
- }
- }
- vaddr = PKMAP_ADDR(last_pkmap_nr);
- set_pte(&(pkmap_page_table[last_pkmap_nr]), mk_pte(page, kmap_prot));
- kmap_count[last_pkmap_nr] = 1;
- set_page_address(page, (void *)vaddr);
- return vaddr;
- }
- void kunmap(struct page *page)
- {
- if (in_interrupt())
- BUG();
- if (!PageHighMem(page))
- return;
- kunmap_high(page);
- }
- void fastcall kunmap_high(struct page *page)
- {
- unsigned long vaddr;
- unsigned long nr;
- int need_wakeup;
- spin_lock(&kmap_lock);
- vaddr = (unsigned long)page_address(page);
- if (!vaddr)
- BUG();
- nr = PKMAP_NR(vaddr);
- /*
- * A count must never go down to zero
- * without a TLB flush!
- */
- need_wakeup = 0;
- switch (--pkmap_count[nr]) {
- case 0:
- BUG();
- case 1:
- need_wakeup = waitqueue_active(&pkmap_map_wait);
- }
- spin_unlock(&kmap_lock);
- /* do wake-up, if needed, race-free outside of the spin lock */
- if (need_wakeup)
- wake_up(&pkmap_map_wait);
临时内核映射:
固定映射的线性区从FIXADDR_START~FIXADDR_TOP,而临时内核映射区只是固定映射的线性区的一部分。固定映射用fixed_addresses中的索引从0xfffff000开始倒着往前分配固定地址的映射区。而临时内核映射其实就是永久映射的原子实现版本,它使用固定映射中FIX_KMAP_BEGIN到FIX_KMAP_END(它们都是的fixed_addresses中的枚举类型)这段区间。为了把一个物理地址与固定映射的线性地址关联起来,内核使用set_fixmap(idx, phys)和set_fixmap_nocache(idx, phys)宏。这两个函数都把fix_to_virt(idx)线性地址对应的一个页表项初始化为物理地址phys。
- enum fixed_addresses {
- FIX_HOLE,
- FIX_VSYSCALL,
- #ifdef CONFIG_X86_LOCAL_APIC
- FIX_APIC_BASE, /* local (CPU) APIC) -- required for SMP or not */
- #endif
- #ifdef CONFIG_X86_IO_APIC
- FIX_IO_APIC_BASE_0,
- FIX_IO_APIC_BASE_END = FIX_IO_APIC_BASE_0 + MAX_IO_APICS-1,
- #endif
- #ifdef CONFIG_X86_VISWS_APIC
- FIX_CO_CPU, /* Cobalt timer */
- FIX_CO_APIC, /* Cobalt APIC Redirection Table */
- FIX_LI_PCIA, /* Lithium PCI Bridge A */
- FIX_LI_PCIB, /* Lithium PCI Bridge B */
- #endif
- #ifdef CONFIG_X86_F00F_BUG
- FIX_F00F_IDT, /* Virtual mapping for IDT */
- #endif
- #ifdef CONFIG_X86_CYCLONE_TIMER
- FIX_CYCLONE_TIMER, /*cyclone timer register*/
- #endif
- #ifdef CONFIG_HIGHMEM
- FIX_KMAP_BEGIN, /* reserved pte's for temporary kernel mappings */
- FIX_KMAP_END = FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1,
- #endif
- #ifdef CONFIG_ACPI_BOOT
- FIX_ACPI_BEGIN,
- FIX_ACPI_END = FIX_ACPI_BEGIN + FIX_ACPI_PAGES - 1,
- #endif
- #ifdef CONFIG_PCI_MMCONFIG
- FIX_PCIE_MCFG,
- #endif
- __end_of_permanent_fixed_addresses,
- /* temporary boot-time mappings, used before ioremap() is functional */
- #define NR_FIX_BTMAPS 16
- FIX_BTMAP_END = __end_of_permanent_fixed_addresses,
- FIX_BTMAP_BEGIN = FIX_BTMAP_END + NR_FIX_BTMAPS - 1,
- FIX_WP_TEST,
- __end_of_fixed_addresses
- };
/*固定映射线性区的结束地址,距4G只有4KB*/
- #define FIXADDR_TOP ((unsigned long)__FIXADDR_TOP)
- #define __FIXADDR_SIZE (__end_of_permanent_fixed_addresses << PAGE_SHIFT)
- #define FIXADDR_START (FIXADDR_TOP - __FIXADDR_SIZE)
- #define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
- #define __virt_to_fix(x) ((FIXADDR_TOP - ((x)&PAGE_MASK)) >> PAGE_SHIFT)
所以,每个索引对应的线性地址是不变的,但是可以通过set_fixmap和set_fixmap_nocache映射到不同的物理地址。
临时内核映射的枚举结构:
- enum km_type {
- D(0) KM_BOUNCE_READ,
- D(1) KM_SKB_SUNRPC_DATA,
- D(2) KM_SKB_DATA_SOFTIRQ,
- D(3) KM_USER0,
- D(4) KM_USER1,
- D(5) KM_BIO_SRC_IRQ,
- D(6) KM_BIO_DST_IRQ,
- D(7) KM_PTE0,
- D(8) KM_PTE1,
- D(9) KM_IRQ0,
- D(10) KM_IRQ1,
- D(11) KM_SOFTIRQ0,
- D(12) KM_SOFTIRQ1,
- D(13) KM_TYPE_NR
- };
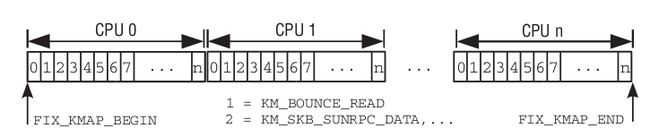
建立临时内核映射调用kmap_atomic:
- void *kmap_atomic(struct page *page, enum km_type type)
- {
- enum fixed_addresses idx;
- unsigned long vaddr;
- /* even !CONFIG_PREEMPT needs this, for in_atomic in do_page_fault */
- inc_preempt_count();
- if (!PageHighMem(page))
- return page_address(page);
- idx = type + KM_TYPE_NR*smp_processor_id();
- vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
- #ifdef CONFIG_DEBUG_HIGHMEM
- if (!pte_none(*(kmap_pte-idx)))
- BUG();
- #endif
- set_pte(kmap_pte-idx, mk_pte(page, kmap_prot));
- __flush_tlb_one(vaddr);
- return (void*) vaddr;
- }
这里先判断是否是高端内存,如果不是就直接返回page对应的线性地址。否则,通过type和CPU标识符smp_processor_id()来确定在固定映射地址中的索引值。获得这个索引值对应的线性地址,设置相应的页表项,然后返回线性地址。这里会让人产生思考的地方是,为什么是kmap_pte-idx而不是kmap_pte+idx呢?先来看一下kmap_pte的初始化在内核启动的时候:
- void __init kmap_init(void)
- {
- unsigned long kmap_vstart;
- /* cache the first kmap pte */
- kmap_vstart = __fix_to_virt(FIX_KMAP_BEGIN);
- kmap_pte = kmap_get_fixmap_pte(kmap_vstart);
- kmap_prot = PAGE_KERNEL;
- }
- #define kmap_get_fixmap_pte(vaddr) \
- pte_offset_kernel(pmd_offset(pud_offset(pgd_offset_k(vaddr), vaddr), (vaddr)), (vaddr))
通过对照上边的宏可以看出来,kmap_pte是FIX_KMAP_BEGIN对应的线性地址所在的页表的页表的线性地址。由于使用的是__fix_to_virt宏,所以kmap_pte应该是接近FIXADDR_TOP而不是接近FIXADDR_START的。也就是说fixed_addresses与km_type中索引大的接近FIXADDR_START,索引小的接近FIXADDR_TOP。所以set_pte的时候是kmap_pte- idx。
撤销临时内核映射调用kmap_atomic:
- void kunmap_atomic(void *kvaddr, enum km_type type)
- {
- #ifdef CONFIG_DEBUG_HIGHMEM
- unsigned long vaddr = (unsigned long) kvaddr & PAGE_MASK;
- enum fixed_addresses idx = type + KM_TYPE_NR*smp_processor_id();
- if (vaddr < FIXADDR_START) { // FIXME
- dec_preempt_count();
- preempt_check_resched();
- return;
- }
- if (vaddr != __fix_to_virt(FIX_KMAP_BEGIN+idx))
- BUG();
- /*
- * force other mappings to Oops if they'll try to access
- * this pte without first remap it
- */
- pte_clear(kmap_pte-idx);
- __flush_tlb_one(vaddr);
- #endif
- dec_preempt_count();
- preempt_check_resched();
- } <span style="line-height: 26px; "> </span>
撤销的时候清除了相应的页表项。
综上,kernel中的高端内存已经研究完了。总结一下:高端内存的引入是为了kernel可以访问大于1G的物理内存(不是同一时刻),划出一个128MB的窗口来自由映射大于1G的内存。vmalloc()主要是建立动态分配和释放的内存区,但是建立和释放的过程非常复杂,需要对pgd,pud,pmd,pte进行修改。这里是修改masterkernel page globaldirectory,进程的内核页部分需要在访问时产生缺页异常然后再同步。而永久内核映射就简单的多,如果没有开PAE,则有4MB的线性地址可以用来映射,4MB当然是只有一个页表就够用了,这个专门的页表地址存放在pkmap_page_table变量中。只需要设置这个页表中相应的表项就可以了,一共1024个表项,每个对应一个4KB的页,因为页比较少,如果页耗尽的时候会导致进程阻塞,这样就不能用在中断处理程序中。而临时内核映射则更加简单了,其实就是永久内核映射的原子实现版,它利用固定内核映射中的一段空间,为每个CPU保存13个窗口,每个窗口的功能是固定的,不同进程需要分配同一个窗口的时候就进行覆盖,所以不会导致进程阻塞,可以用于中断处理程序和可延迟函数的内部。