神经网络那些事儿(二)
在上一篇中,我们看到了神经网络是怎样使用梯度下降算法来学习它们的权值和偏置。然而,我们还有一些没有解释:我们没有讨论怎样计算损失函数的梯度。本篇中将解释著名的BP算法,它是一个快速计算梯度的算法。
反向传播算法(Backpropagation algorithm,BP)是在1970s提出的,但是它的重要性直到一篇著名的1986年的论文才被接受。论文是David Rumelhart,Geoffrey Hinton,以及Ronald Williams合写的。这篇论文描述了几种神经网络,其中的反向传播算法工作得更快比早期的学习算法,这使得使用神经网络能够解决之前不能解决的问题。今天,反向传播算法已经是神经网络中最核心的算法。
BP算法的核心是网络中的损失函数C分别关于任何权值w(或者偏置b)的偏导数![]() 的表达式。这个表达式告诉我们当我们改变权值和偏置的时候损失函数变化得有多快。BP算法不仅是一个快速学习的算法,它实际上给出了更细节的关于权值和偏置改变网络的全部行为是怎样变化的。
的表达式。这个表达式告诉我们当我们改变权值和偏置的时候损失函数变化得有多快。BP算法不仅是一个快速学习的算法,它实际上给出了更细节的关于权值和偏置改变网络的全部行为是怎样变化的。
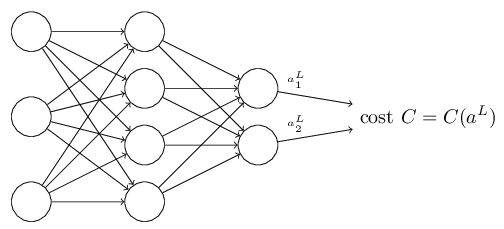
热身:一个基于矩阵快速计算神经网络输出的方法
在讨论反向传播之前,让我们先热身一下,看一下一个快速基于矩阵的计算神经网络输出的算法。我们实际上已经简短地看见了这个算法在上一张快结束的时候。特别地,这是熟悉在反向传播中用到的符号的一种很自然的方法。
我们将使用![]() 来表示第(l-1)层的第k个神经元到第l层的第j个神经元之间连接的权值。例如下图中的
来表示第(l-1)层的第k个神经元到第l层的第j个神经元之间连接的权值。例如下图中的![]() 表示第3层的第2个神经元与第2层的第4个神经元之间的连接的权值:
表示第3层的第2个神经元与第2层的第4个神经元之间的连接的权值:

那么,对于偏置和激活,我们使用一个相似的符号。显然地,我们使用![]() 表示第l层的第j个神经元。并且,我们使用
表示第l层的第j个神经元。并且,我们使用![]() 来表示第l层的第j个神经元的激活。就像下图一样:
来表示第l层的第j个神经元的激活。就像下图一样:

我们能发现第l层的第j个神经元的激活![]() 和第l-1层的激活有关系,正如下面的式子:
和第l-1层的激活有关系,正如下面的式子:
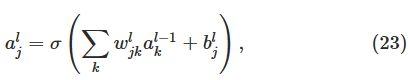
这里的和表示第l-1层的所有神经元k。为了把表达式写成一个矩阵形式,我们为每层l定义了一个权值矩阵![]() 。权值矩阵
。权值矩阵![]() 的元素仅仅是和第l层的神经元连接的权值,即,第j行和第j列的元素是
的元素仅仅是和第l层的神经元连接的权值,即,第j行和第j列的元素是![]() 。类似地,对于每一层l,我们定义一个偏置向量
。类似地,对于每一层l,我们定义一个偏置向量![]() 。偏置向量的元素仅仅是值
。偏置向量的元素仅仅是值![]() ,第l层的每个神经元的一个元素。最后,我们定义了一个激活向量
,第l层的每个神经元的一个元素。最后,我们定义了一个激活向量![]() ,它的组成是激活
,它的组成是激活![]() 。接下来我们要做的是向量化一个函数,例如
。接下来我们要做的是向量化一个函数,例如![]() 。简单地说,如果我们有函数
。简单地说,如果我们有函数![]() ,那么f的向量化形式有这样的结果:
,那么f的向量化形式有这样的结果:

所以我们能够把(23)式写成:

这样写不仅在符号上简单许多,而且有助于你从总体上理解这个式子:第l层的激活就是等于前一层(l-1)的激活和与l层神经元相连接的权值的积再加上该层的偏置,然后应用sigmoid函数。最关键的是,许多线性代数库计算基于矩阵的形式会非常快。
当使用等式(25)来计算![]() ,我们计算了一个中间量
,我们计算了一个中间量![]() 沿着这种方式。这个量表明是足够有用的而值得重新命名:我们把
沿着这种方式。这个量表明是足够有用的而值得重新命名:我们把![]() 称作到第l层神经元的权重输入(weighted input)。等式(25)有时候会写成权重输入(weighted input)的形式,正如
称作到第l层神经元的权重输入(weighted input)。等式(25)有时候会写成权重输入(weighted input)的形式,正如![]() 。然后需要注意的是:
。然后需要注意的是:![]() 有
有![]() 这样的组成,即,
这样的组成,即,![]() 只是第l层的神经元j的到激活函数的权重输入。
只是第l层的神经元j的到激活函数的权重输入。
关于损失函数我们需要的两个假设
BP算法的目标就是计算损失函数C关于任何网络中的权重w或者偏置b的偏导数![]() 和
和![]() 。这里还是以二次损失函数为例子。即:
。这里还是以二次损失函数为例子。即:
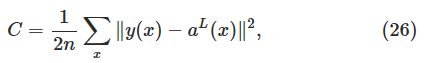
这里的n是训练样本的总数;对所有单个训练样本x取和;y=y(x)是相应的期望输出;L表示层数;![]() 是输入为x的网络的激活向量
是输入为x的网络的激活向量![]() 。
。
第一个假设就是损失函数可以被写成![]() ,单个的训练样本的损失函数为
,单个的训练样本的损失函数为![]() 。我们始终遵循这种假设。
。我们始终遵循这种假设。
我们需要这个假设的理由是因为反向传播实际上让我们做的是计算单个的训练样本的偏导数![]() 和
和![]() 。然后通过平均所有的训练样本来计算
。然后通过平均所有的训练样本来计算![]() 和
和![]() 。实际上,我们可以假设训练样本x已经被固定,然后丢弃x下标,把损失
。实际上,我们可以假设训练样本x已经被固定,然后丢弃x下标,把损失![]() 写成
写成![]() 。
。
第2个假设是损失可以被写成一个神经网络的输出的函数:
例如,二次损失函数满足这个需求,因为单个训练样本x的二次损失可能被写成:

Hadamard积,
反向传播算法是基于普通的线性代数操作-像向量相加,用矩阵乘以一个向量。但是其中有一个操作用的比较少。假设s和t是两个维数一样的向量。那么我们使用![]() 来表示两个元素的按位相乘。因此,
来表示两个元素的按位相乘。因此,![]() 的组成为
的组成为![]() 。例如:
。例如:
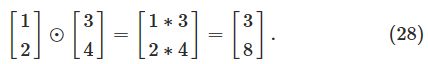
这种按位相乘有时被称为Hadamard 积。好的矩阵库通常提供了Hadamard积的快速的实现,这对于实现反向传播信手拈来。
反向传播背后的四个等式
反向传播是关于理解在一个网络改变损失函数时,权重和偏置是怎样变化的。最终,这个意味着计算偏导数![]() 和
和![]() 。但是为了计算那些,我们首先引进一个中间变量,
。但是为了计算那些,我们首先引进一个中间变量,![]() ,我们把它称为第l层的第j个神经元的error。BP将给出一个计算error
,我们把它称为第l层的第j个神经元的error。BP将给出一个计算error ![]() 的过程,然后关联
的过程,然后关联![]() 和
和![]() 与
与![]() 。
。
为了理解error是如何定义的,想象我们的神经网络中有一个精灵:

这个精灵坐在第l层的第j个神经元上。当神经元的输入进来时,精灵扰乱神经元的操作。它增加了一个小的变化![]() 到神经元的权重输入,所以输出不再是
到神经元的权重输入,所以输出不再是![]() ,而是
,而是![]() 。这个变化传播到网络中后面的层,最终导致损失函数改变了一个量
。这个变化传播到网络中后面的层,最终导致损失函数改变了一个量![]() 。
。
现在,这个精灵是一个好的精灵,并且正在帮助你改进损失函数,也就是他们正尝试找到一个![]() 使得损失函数更小。假设
使得损失函数更小。假设![]() 有一个很大的值(要么是正的要么是负的,指绝对值)。那么,精灵能够通过选择
有一个很大的值(要么是正的要么是负的,指绝对值)。那么,精灵能够通过选择![]() 有和
有和![]() 相反的符号来使损失函数减小得十分多。相反,如果
相反的符号来使损失函数减小得十分多。相反,如果![]() 接近于0,那么精灵就不能通过扰乱权重输入
接近于0,那么精灵就不能通过扰乱权重输入![]() 来改进损失函数。到目前为止,精灵能够告诉我们,神经元已经相当接近最优了。因此,存在一个启发式
来改进损失函数。到目前为止,精灵能够告诉我们,神经元已经相当接近最优了。因此,存在一个启发式![]() 是神经元的error的一个度量。于是我们定义层l的的神经元j的error
是神经元的error的一个度量。于是我们定义层l的的神经元j的error ![]() 为:
为:

按照我们的传统,我们使用![]() 来表示和层l关联的error向量。反向传播将告诉我们计算每层的
来表示和层l关联的error向量。反向传播将告诉我们计算每层的![]() 方法,然后把这些errors关联到我们真实感兴趣的量
方法,然后把这些errors关联到我们真实感兴趣的量![]() 和
和![]() 。
。
你可能想知道为什么精灵正在改变权重输入![]() 。当然,想象精灵正在改变输出激活
。当然,想象精灵正在改变输出激活![]() ,然后使用
,然后使用![]() 来度量我们的error,这样也许会更自然。事实上,如果你这样做了将和下面的讨论的结果是差不多的。但是,它将使陈述BP变得稍微有点代数上更复杂。因此,我们将坚持
来度量我们的error,这样也许会更自然。事实上,如果你这样做了将和下面的讨论的结果是差不多的。但是,它将使陈述BP变得稍微有点代数上更复杂。因此,我们将坚持![]() 作为我们error的度量。
作为我们error的度量。
攻克计划:
BP是基于四个基础的等式。这些等式一起给了我们一个计算error(你可以将其翻译为残差)![]() 和损失函数的梯度的方法。
和损失函数的梯度的方法。
输出层残差 的一个等式
的一个等式
:![]() 的组成由下面的式子给定:
的组成由下面的式子给定:
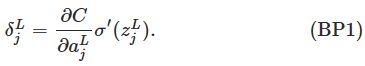
这是一个很自然的式子。右边的第一项,![]() ,仅仅是度量作为第j个输出激活的一个函数,损失函数变化得有多快。例如,如果C不依赖于一个特定输出神经元j很多的话,那么
,仅仅是度量作为第j个输出激活的一个函数,损失函数变化得有多快。例如,如果C不依赖于一个特定输出神经元j很多的话,那么![]() 将是很小的,这也正是我们所期望的。右边的第二项,
将是很小的,这也正是我们所期望的。右边的第二项,![]() 是度量激活函数
是度量激活函数![]() 在点
在点![]() 上改变得有多快。我们能够发现,(BP1)中的所有项都很容易计算。特别是,我们计算
上改变得有多快。我们能够发现,(BP1)中的所有项都很容易计算。特别是,我们计算![]() 同时也在计算网络的行为,并且计算
同时也在计算网络的行为,并且计算![]() 也只是一个很小的花费。
也只是一个很小的花费。![]() 的真实形式将取决于损失函数的形式。然而,被提供的损失函数是已知的,会存在一点小麻烦在计算
的真实形式将取决于损失函数的形式。然而,被提供的损失函数是已知的,会存在一点小麻烦在计算![]() 的时候。例如,如果我们使用二次损失函数,那么
的时候。例如,如果我们使用二次损失函数,那么![]() ,因此
,因此![]() ,它是很容易被计算的。
,它是很容易被计算的。
等式(BP1)是一个![]() 分量方式的表达式。它是一个完美的表达式,但是不是我们想要的基于矩阵的BP表达式。然而,把它写成一个矩阵的形式也是简单的:
分量方式的表达式。它是一个完美的表达式,但是不是我们想要的基于矩阵的BP表达式。然而,把它写成一个矩阵的形式也是简单的:
![]()
这里,![]() 被定义为偏导数
被定义为偏导数![]() 组成的一个向量。你可以把它想象成表达C关于输出激活的一个变化率。所以,
组成的一个向量。你可以把它想象成表达C关于输出激活的一个变化率。所以,![]() ,最后基于矩阵的形式为:
,最后基于矩阵的形式为:
![]()
用下一层中的残差 表示的残差
表示的残差 的一个等式
的一个等式
:特别地
![]()
假设我们知道残差![]() 在第
在第![]() 层。当我们应用转置权值矩阵
层。当我们应用转置权值矩阵![]() 时,我们可以直观地把这个想成让残差向后穿过网络,从而给了我们某种度量第l层的输出的残差的方法。当使用Hadamard积
时,我们可以直观地把这个想成让残差向后穿过网络,从而给了我们某种度量第l层的输出的残差的方法。当使用Hadamard积![]() 时,它通过第l层的激活函数把残差向后移动,给出了到达l层的权重输入的残差
时,它通过第l层的激活函数把残差向后移动,给出了到达l层的权重输入的残差![]() 。
。
组合BP2和BP1,我们能计算网络中的任何层的残差![]() 。我们首先通过BP1来计算
。我们首先通过BP1来计算![]() ,然后应用等式BP2来计算
,然后应用等式BP2来计算![]() ,然后再次使用等式BP2计算
,然后再次使用等式BP2计算![]() ,等等,用这样的方式反向穿过网络。
,等等,用这样的方式反向穿过网络。
网络中损失函数关于任何偏置的变化率的一个等式:
特别地:

也就是,残差![]() 实际上等于变化率
实际上等于变化率![]() 。这个信息很有用,因为BP1和BP2已经告诉我们怎样计算
。这个信息很有用,因为BP1和BP2已经告诉我们怎样计算![]() 。我们能够重写BP3:
。我们能够重写BP3:

损失函数关于任何权值的变化率的一个等式:
特别地:

这告诉我们怎样利用量![]() 和
和![]() 来计算偏导数
来计算偏导数![]() ,前面两个量我们已经知道怎么计算了。可以重写为下面的形式:
,前面两个量我们已经知道怎么计算了。可以重写为下面的形式:

其中![]() 是权重为w输入的神经元的激活,
是权重为w输入的神经元的激活,![]() 是从权重w的神经元的输出残差。可以简化为下面的图形:
是从权重w的神经元的输出残差。可以简化为下面的图形:

等式(32)的一个很好的结果是当激活![]() 很小的时候,
很小的时候,![]() ,梯度项
,梯度项![]() 也将趋向于很小。在这种情况下,我们将说权重学习得很慢,意味着在梯度下降过程中改变得很多。换句话说,BP4的一个结果就是从低-激活神经元输出的权重学习得很慢。
也将趋向于很小。在这种情况下,我们将说权重学习得很慢,意味着在梯度下降过程中改变得很多。换句话说,BP4的一个结果就是从低-激活神经元输出的权重学习得很慢。
从BP1-BP4中也可以看到其他的信息。先看看输出层。考虑(BP1)中的![]() 项。回忆上一章中的sigmoid函数的图,当
项。回忆上一章中的sigmoid函数的图,当![]() 接近0或1的时候,
接近0或1的时候,![]() 函数变得很平坦。当这个发生的时候,我们可以得到
函数变得很平坦。当这个发生的时候,我们可以得到![]() 。所以如果输出神经元是低激活(
。所以如果输出神经元是低激活(![]() )或者高激活(
)或者高激活(![]() ),那么最后一层中的权重将学习得很慢。这种情况下,通常是说输出神经元已经饱和了,并且权重已经停止学习了(或者学习得很慢)。相似的结论对于输出神经元中的偏置也是成立的。
),那么最后一层中的权重将学习得很慢。这种情况下,通常是说输出神经元已经饱和了,并且权重已经停止学习了(或者学习得很慢)。相似的结论对于输出神经元中的偏置也是成立的。
对于非输出层我们也能获得一些相似的信息。特别是,注意BP2中的项![]() 。这意味着如果神经元接近饱和,则
。这意味着如果神经元接近饱和,则![]() 可能变小。反过来,这也意味着输入到一个饱和神经元的任何权重也将学习得很慢。
可能变小。反过来,这也意味着输入到一个饱和神经元的任何权重也将学习得很慢。
可以总结出来,我们已经知道,如果输入神经元是低-激活或者输出神经元已经饱和了,也就是要么是高激活,要么是低激活,那么一个权重将学习得很慢。刚才观测到的这些信息没有太多的让人惊讶。但是,它们依旧帮助提升当一个神经网络学习的时候发生了什么我们的思维模型。
四个基础等式的证明
我们将证明四个基础等式(BP1)-(BP4)。所有四个等式都是多元微积分的链式法则的结果。首先看(BP1)等式吧,它给出的是输出残差,![]() 。为了证明这个等式,回忆定义:
。为了证明这个等式,回忆定义:

应用链式法则,我们可以重写使用关于输出激活的偏导数来表示
上面的偏导数:
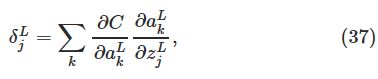
和表示所有输出层中的神经元k。当然,第k个神经元仅仅取决于当k=j时的第j个神经元的输入权值![]() 的输出激活
的输出激活![]() 。因此当
。因此当![]() 时,
时,![]() 项就消失了。所以可以简化前面的等式为:
项就消失了。所以可以简化前面的等式为:

因为![]() ,右边的第2项能够被写成
,右边的第2项能够被写成![]() ,等式就变成:
,等式就变成:
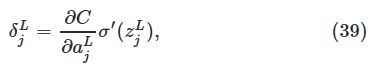
这便是BP1的形式。接下来BP2和BP3的证明留给读者自己思考。
反向传播算法
BP算法为我们提供了一个计算损失函数梯度的方法。写成一个算法的形式:
-
输入 x:为输入层设置相应的激活
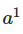 。
。
-
前向:对于每个l=2,3,…,L计算
 以及
以及
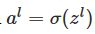 。
。
-
输出残差
 :计算向量
:计算向量
 。
。
-
反向传播残差:对于每个l=L-1,L-2,…,2计算
 。
。
-
输出:损失函数的梯度为
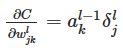 和
和
 。
。
我们从最后一层开始向后计算残差向量![]() ,这可能看起来我们正在向后穿过网络是奇怪的。但是,如果你思考反向传播的证明,反向移动是由于损失是网络的输出的一个函数的事实所导致的。为了理解损失怎样随着早先的权重和偏置变化的,我们需要重复应用链式法则,层层向后计算来获得可用表达式信息。反向传播算法计算的是单个训练样本的梯度,即
,这可能看起来我们正在向后穿过网络是奇怪的。但是,如果你思考反向传播的证明,反向移动是由于损失是网络的输出的一个函数的事实所导致的。为了理解损失怎样随着早先的权重和偏置变化的,我们需要重复应用链式法则,层层向后计算来获得可用表达式信息。反向传播算法计算的是单个训练样本的梯度,即![]() 。实践中,通常把反向传播和一个像随机梯度这样的学习算法组合,在随机梯度算法中我们计算许多训练样本的梯度。特别地,给定一个含有m个训练样本的mini-batch,下面的算法应用了一个基于mini-batch的梯度下降学习算法:
。实践中,通常把反向传播和一个像随机梯度这样的学习算法组合,在随机梯度算法中我们计算许多训练样本的梯度。特别地,给定一个含有m个训练样本的mini-batch,下面的算法应用了一个基于mini-batch的梯度下降学习算法:
-
输入一个训练样本的集合
-
对于每个训练样本x:设置相应的输入激活
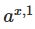 ,然后执行下面的步骤:
,然后执行下面的步骤:
-
前向:对于每个l=2,3,…,L计算
 以及
以及
 。
。
-
输出残差
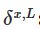 :计算向量
:计算向量
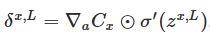 。
。
-
反向传播残差:对于每个l=L-1,L-2,…,2计算

-
-
梯度下降:对于每个l=L,L-1,…,2依据规则
 更新权重,依据规则
更新权重,依据规则
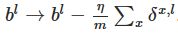 更近偏置。
更近偏置。
当然,实践中为了实现随机梯度下降,你也需要一个外层循环来产生训练样本的mini-batches,以及一个外层循环单步执行训练的多个epochs。
反向传播代码实现:
关于代码的分析,请看我的下一篇文章《神经网络代码分析》。
转载 http://www.gumpcs.com/index.php/archives/962