Oracle DB 移动数据
• 描述移动数据的方式
• 创建和使用目录对象
• 使用SQL*Loader 加载非Oracle DB(或用户文件)
中的数据
• 使用外部表并通过与平台无关的文件移动数据
• 说明Oracle 数据泵的一般体系结构
• 使用数据泵的导出和导入实用程序在Oracle DB 之间
移动数据
- 移动数据:一般体系结构
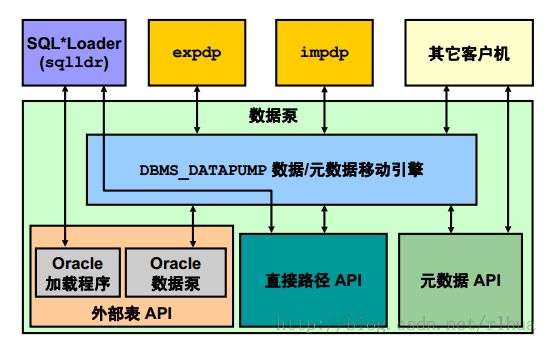
移动数据:一般体系结构
主要功能组件:
• DBMS_DATAPUMP:包括高速导出与导入实用程序的API,可用于成批地移动数据和
元数据。
• 直接路径API (DPAPI):Oracle Database 11g支持直接路径API 接口,可在卸载和
加载时将数据转换与语法分析工作量降至最低。
• DBMS_METADATA:Worker 进程使用该组件卸载或加载所有元数据。数据库对象定
义是使用XML 存储的,而不是SQL。
• 外部表API:使用ORACLE_DATAPUMP和ORACLE_LOADER访问驱动程序,可将
数据存储在外部表中(即与平台无关的文件中)。使用SELECT语句可读取外部表,
就像外部表存储在Oracle DB 中一样。
• SQL*Loader:与外部表集成在一起,因此可为外部表访问参数提供自动移植加载
程序控制文件的功能。
• expdp和impdp:瘦客户机层,可通过调用DBMS_DATAPUMP程序包启动和监视
数据泵操作。
• 其它客户机:得益于此基础结构的应用程序(如Database Control、复制应用程序、
可传输表空间应用程序和用户应用程序)。SQL*Plus 也可用作DBMS_DATAPUMP的
一个客户机,但只提供实时操作的简单状态查询。
- Oracle 数据泵:概览
作为一个基于服务器的用于高速移动数据与元数据的工具,
Oracle 数据泵具有以下特点:
• 可通过DBMS_DATAPUMP调用
• 可提供以下工具:
– expdp
– impdp
– 基于Web 的界面
• 提供四种数据移动方法:
– 数据文件复制
– 直接路径
– 外部表
– 网络链接支持
• 可与长时间运行的作业分离后再重新挂接
• 可重新启动数据泵作业
使用Oracle 数据泵可快速加载或卸载Oracle DB 的数据与元数据。数据泵基础结构是通过
DBMS_DATAPUMP PL/SQL 程序包调用的。因此,通过使用数据泵可构建定制的数据移动
实用程序。
Oracle Database 11g提供以下工具:
• 命令行导出与导入客户机,分别称为expdp和impdp
• 基于Web 的导出与导入界面,可通过Database Control 访问
数据泵会自动确定要使用的数据访问方法;访问方法可能是直接路径或外部表。如果表结
构允许使用直接路径加载和卸载,而且希望单个流性能达到最大时,数据泵会使用直接路
径加载和卸载。但是,如果存在聚簇表、引用完整性约束条件、加密列或一些其它项,数
据泵会使用外部表(而不是直接路径)来移动数据。
因为数据泵能够在与长时间运行的作业分离后重新挂接而不影响作业本身,所以你可以监
视多个位置正在运行的作业。只要元信息未受干扰,就可重新启动所有停止的数据泵作业
而不会丢失数据。无论作业是自发停止的,还是由于崩溃而非自发停止的,都无关紧要。
- Oracle 数据泵:优点
与早期的数据移动工具相比,数据泵具有许多优点并提供了
一些新的功能,如:
• 细粒度级的对象和数据选择
• 显式指定数据库版本
• 并行执行
• 估计导出作业占用的空间
• 在分布式环境中支持网络模式
• 重新映射功能
• 数据取样率和元数据压缩
• 在数据泵导出期间压缩数据
• 通过加密增强安全性
• 能够将XMLType 数据作为CLOB 导出
• 在旧模式下支持旧的导入和导出文件
Oracle 数据泵:优点
EXCLUDE、INCLUDE和CONTENT参数
用于细粒度级的对象和数据选择。
可以通过指定要移动对象的数据库版本(使用VERSION参数)来创建与支持数据泵的
低版本Oracle DB 兼容的转储文件集。
可以使用PARALLEL参数
指定代表导出作业而运行的活动执行服务器的最大线程数。
使用ESTIMATE_ONLY
参数可估计导出作业占用的空间量(但实际上并不执行导出)。
使用网络模式可从远程数据库直接导出到转储文件集。使用指向源系统的数据库链接可
完成此操作。
在导入过程中,可以更改目标数据文件名、方案和表空间。
此外,还可指定执行数据泵导出时,要从源数据库取样和卸载的数据的百分比。指定
SAMPLE参数可完成此操作。
使用COMPRESSION参数
可指示是否在导出转储文件中压缩元数据,以便占用更少的磁盘
空间。如果压缩了元数据,导入过程中会自动执行解压缩。
在Oracle Database 11g中新增了一些功能,使你可以:
• 在导出期间同时压缩数据和元数据,仅压缩数据,仅压缩元数据或者不压缩数据。
• 指定以下几个方面的附加加密选项:
- 可选择在导出期间同时加密数据和元数据,仅加密数据,仅加密元数据,不加
密数据或仅加密列。
- 可指定要在导出期间使用的特定加密算法。
- 可指定在导出期间要用于执行加密和解密的安全类型。例如,转储文件集可能
会导入到其它数据库或远程数据库,而在传输过程中必须保障其安全性。另外,
转储文件集可能会使用Oracle Encryption Wallet 进行本地导入,但也可能需要在
无法使用Oracle Encryption Wallet 的情况下进行异地导入。
• 使用可移动方法执行表模式导出和导入;指定在执行导入操作期间应如何处理分区表。
• 在导出操作期间覆盖现有转储文件。
• 在执行导入操作期间重命名表。
• 指定即使遇到违反非延迟约束条件的情况,也应继续执行数据加载(这仅适用于使用
外部表访问方法的导入操作)。
• 指定无论为XMLType 列定义了何种XMLType 存储格式,都要以未压缩的CLOB 格
式导出这些列。
• 在导出期间指定重新映射功能,将指定列的原始值视为源,然后返回一个重新映射值,
此值将替换转储文件中的原始值。
• 在将数据导入到新数据库时重新映射数据。
• 在旧模式下支持使用原有的导出(exp) 和导入(imp) 脚本。
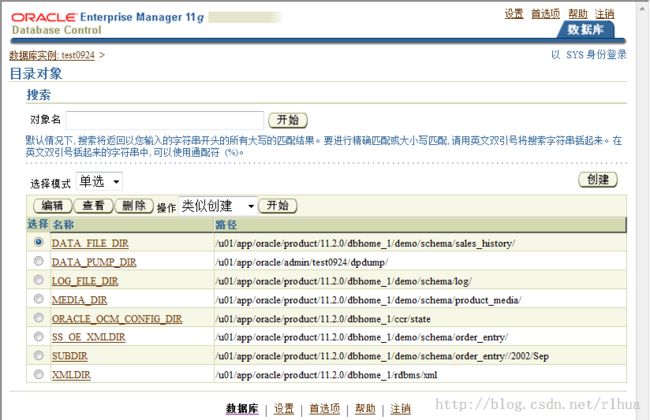
- 数据泵的目录对象
目录对象是一些代表服务器文件系统上的物理目录的逻辑结构。这些对象包含了特定操作
系统目录的位置。可以在Enterprise Manager 中使用此目录对象名,这样就不必对目录路
径规范进行硬编码,从而获得更大的文件管理灵活性。目录对象由SYS用户拥有。目录
名在数据库中是唯一的,因为所有目录都位于一个名称空间(即SYS)中。
为数据泵指定文件位置时,需要用到目录对象。这是因为数据泵访问的文件在服务器上,
而不是在客户机上。
在Enterprise Manager 中,选择“Schema > Database Objects > Directory Objects(方案>
数据库对象> 目录对象)”。
要编辑或删除一个目录对象,请选择该对象,然后单击相应的按钮。
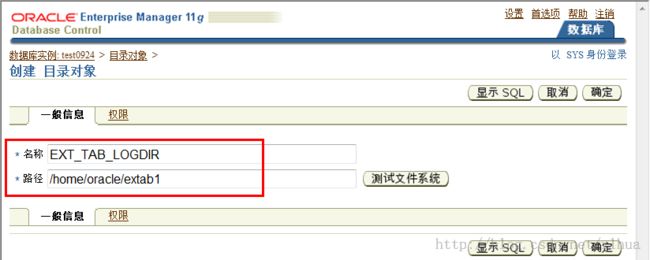
- 创建目录对象
1. 在“Directory Objects(目录对象)”页中,单击“Create(创建)”按钮。
2. 输入目录对象的名称及目录对象映射到的操作系统路径。应先创建操作系统目录,
之后才能使用这些目录。你可以单击“Test File System(测试文件系统)”按钮对此
进行测试。为了进行测试,请提供主机登录身份证明(即有权限对此操作系统目录
进行操作的操作系统用户)。
CREATE
DIRECTORY
"EXT_TAB_LOGDIR"
AS
'/home/oracle/extab1'
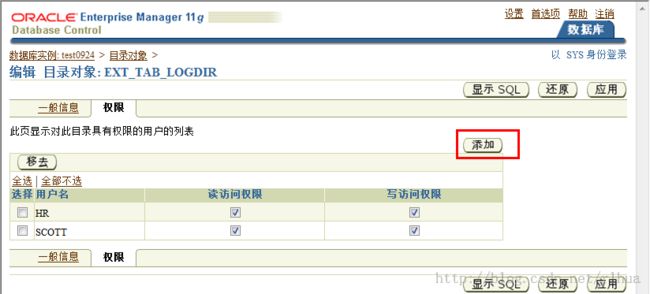
3. 目录对象的权限不同于服务器文件系统物理目录的操作系统权限。你可以管理各个
目录对象的用户权限。这样做提高了安全级别,同时还允许你对这些对象进行粒度
级控制。在“Privileges(权限)”页中,单击“Add(添加)”,选择要向其授予
读权限、写权限或读写权限的用户。
GRANT
READ
ON
DIRECTORY
"EXT_TAB_LOGDIR"
TO
"HR"
,
"SCOTT"
GRANT WRITE ON DIRECTORY "EXT_TAB_LOGDIR" TO "HR" , "SCOTT"
GRANT WRITE ON DIRECTORY "EXT_TAB_LOGDIR" TO "HR" , "SCOTT"
4. 单击“Show SQL(显示SQL)”查看基础语句。完成后单击“Return(返回)”。
5. 单击“OK(确定)”创建对象。
- 数据泵导出与导入客户机:概览
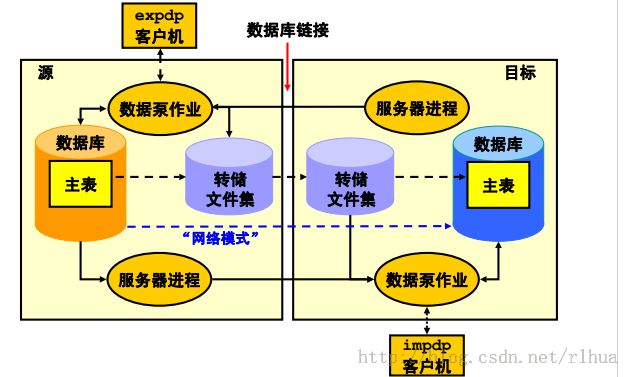
数据泵导出与导入客户机:概览
数据泵导出实用程序是这样一种实用程序,它可以将数据和元数据卸载到名为“转储文件
集”的操作系统文件集中。数据泵导入实用程序则用于将导出转储文件集中存储的元数据
和数据加载到目标系统。
数据泵API 访问位于服务器上的相应文件,而非客户机上的文件。
上述这两种实用程序还可以用于从远程数据库直接导出到转储文件集,或者从源数据库直
接加载目标数据库,而无需使用任何干预文件。这被称为“网络模式”。从只读源数据库
导出数据时,此模式尤其有用。
每个数据泵操作的核心为主表(MT),这是在运行数据泵作业的用户方案中创建的表。MT
中保存着作业的各个方面。MT 是在执行基于文件的导出作业期间构建的,在导出操作的
最后一步会写入转储文件集。与之相反,将MT 加载到当前用户的方案中是基于文件的导
入操作的第一步,用于确定所有导入对象的创建顺序。
注:如果作业出现计划内或计划外停止的情况,MT 是数据泵重新启动作业功能的关键。
数据泵作业正常完成后,MT 即会删除。
- 数据泵实用程序:界面与模式
• 数据泵导出与导入界面:
– 命令行
– 参数文件
– 交互式命令行
– Enterprise Manager
• 数据泵导出与导入模式:
– 全部
– 方案
– 表
– 表空间
– 可移动表空间
数据泵实用程序:界面与模式
你可以使用下列界面之一与数据泵导出和导入实用程序进行交互:
• 命令行界面:使你可以直接在命令行上指定大多数导出参数。
• 参数文件界面:使你可以在参数文件中指定所有命令行参数。唯一例外是PARFILE
参数。
• 交互式命令界面:停止登录到终端并显示导出或导入提示符,在这些提示符下可输
入各种命令。在使用命令行接口或参数文件接口启动导出操作过程中,按[Ctrl] + [C]
可启用这种模式。另外,挂接到正在执行的作业或已停止的作业时,也能启用交互
式命令模式。
• Web 界面:在Database Control 主页上,单击“Data Movement(数据移动)”选项
卡,然后从“Move Row Data(移动行数据)”区域选择下列链接之一:“Export to
Export Files(导出到导出文件)”、“Import from Export Files(从导出文件导入)”
或“Import from Database(从数据库导入)”。
数据泵导出与导入针对卸载或加载数据库的不同部分提供了不同的模式。在命令行上使用
相应参数可指定提供的模式。可用的模式已在上图中列出,它们与原有导出和导入实用
程序中的模式相同。
- 使用Database Control 进行数据泵导出
Enterprise Manager Database Control 提供了一个向导程序来指导您完成执行数据泵导出与
导入的整个流程。以上示例显示的是数据泵导出。
在“Database Instance(数据库实例)”主页中,单击“Data Movement(数据移动)”选
项卡,定位到Web 页的“Move Row Data(移动行数据)”部分的数据泵导出与导入选项。
单击“Export to Export Files(导出到导出文件)”开始数据泵导出会话。
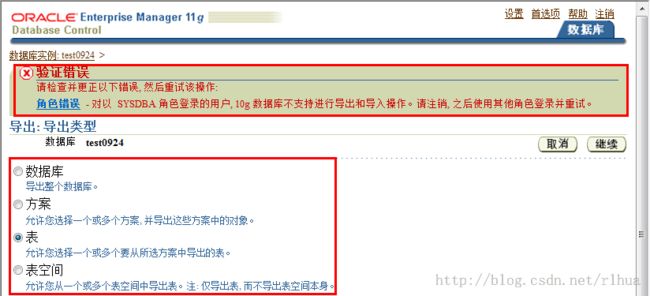
接下来将显示选择导出类型窗口。如果一个已授权用户连接到数据库实例,则导出类型包
括以下内容:
• 数据库
• 方案
• 表
• 表空间
如果使用的是非管理帐户,则导出类型列表仅限以下类型:
• 方案
• 表
单击“Continue(继续)”继续执行导出操作。
这里需要注意,使用system账号普通身份登陆,导出数据文件。注意填写主机身份证明。
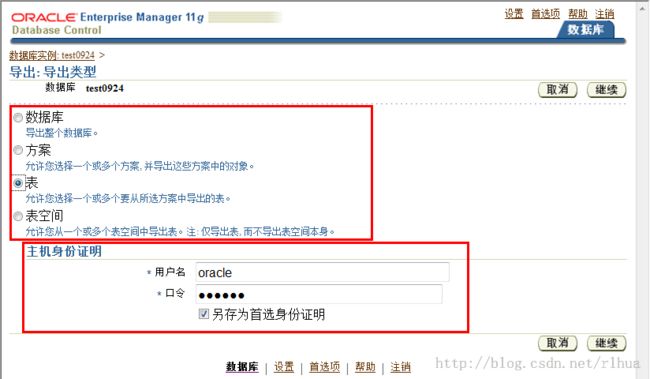
- 数据泵导出示例:基本选项
上图点击继续后,点击添加需要导出的。
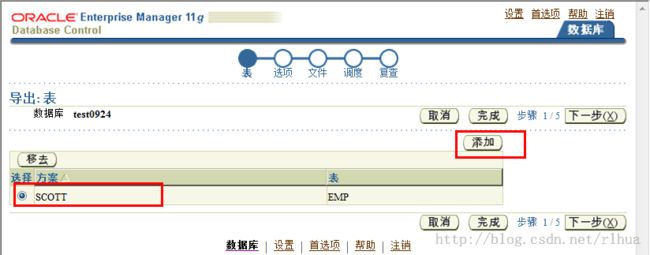
“Options(选项)”页显示数据泵导出作业的可配置选项。
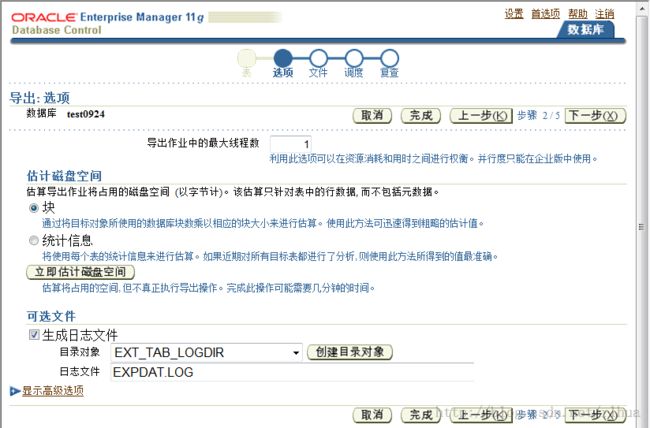
“Maximum Number of
Threads in Export Job(导出作业中的最大线程数)”条目对应于命令行中的PARALLEL
参数。指定的值应小于或等于转储文件集中的文件数。此选项决定了所使用的并行I/O
服务器进程的数目,但在并行查询操作中充当查询协调程序的主控制进程和Worker 进程
不计入该总数。
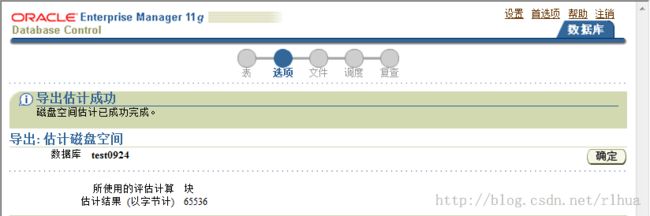
导出作业要占用的磁盘空间的估计值(字节)将输出至标准输出和日志文件。估计值可
根据块计数乘以块大小得出,也可基于最近的统计信息分析。此选项对应于ESTIMATE
命令行参数。
可以为导出作业指定一个可选的日志文件,用于记录与正在进行的工作、已完成的工作和
遇到的错误有关的消息。执行导出的用户需要对为日志文件指定的目录对象享有写权限。
如果要指定的日志文件已存在,则会覆盖该文件。此选项对应于命令行的LOGFILE参数。
- 数据泵导出示例:高级选项
单击“Show Advanced Options(显示高级选项)”链接即可显示高级选项。
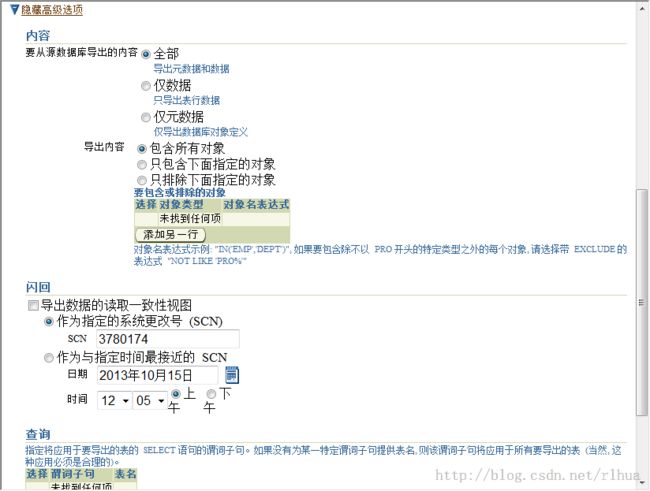
页面的“Content(内容)”部分允许你过滤导出所卸载的内容:仅数据、仅元数据或者
这两者。此选项对应于
CONTENT
命令行参数。“Content(内容)”部分还允许指定
INCLUDE
和
EXCLUDE
命令行参数。
使用
EXCLUDE参数可从导出或导入操作中排除任何数据库对象类型。使用可选的名称
限定符,你可以在指定的每个对象类型中进行更细的选择,如下面几个示例所示:
EXCLUDE=VIEW
EXCLUDE=PACKAGE
EXCLUDE=INDEX:"LIKE 'EMP%'"
INCLUDE参数可在操作中只包含指定的对象类型和对象。
语法:INCLUDE = object_type[:"name_expr"]
导出数据时可使用闪回查询。
QUERY参数与原有导出实用程序的工作方式相似,但前者具有两个重要的增强功能:一个
功能是此参数可以通过一个表名称来加以限定,从而使其只适用于该表;另一个功能是此
参数还可以在导入过程中使用。下面是一个示例:
QUERY=hr.employees:"WHERE department_id in (10,20)
- 数据泵导出示例:文件
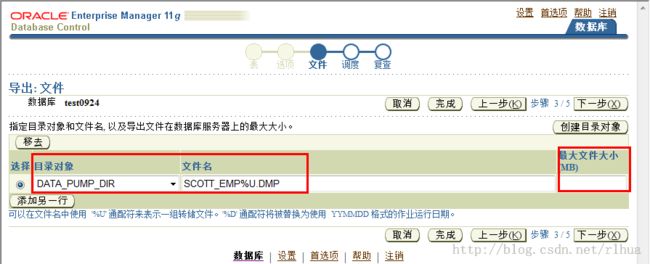
DUMPFILE参数指定了基于磁盘的转储文件的名称和(可选)目录。可采用逗号分隔的
列表的形式或者单个DUMPFILE参数规范的形式提供多个文件规范。文件名可包含替代
变量%U,此变量表示可生成多个文件。在生成的文件名中,%U被扩展为双字符、固定
宽度、从01开始单调递增的整数。如果未指定DUMPFILE,则默认情况下使用
expdat.dmp。默认情况下,创建的转储文件会自动扩展。
如果指定了
FILESIZE,则每个文件的大小为FILESIZE字节且不可扩展。如果需要更
多的转储空间,并且提供了带%U的模板,则会自动创建具有FILESIZE字节的新文件;
否则,客户机会收到要添加新文件的消息。
如果指定了带%U的模板,则最初创建的文件数目等于PARALLEL参数。
默认情况下,不会覆盖与所生成文件名匹配的预先存在的文件,而是会导致错误并导致
作业中止。如果希望覆盖文件,可设置REUSE_DUMPFILES=Y。单击“Next(下一步)”
继续执行导出操作。
注:如果提供了多个转储文件模板,则会循环使用这些模板生成转储文件。
• 在使用数据泵导出之前,你不需要手动创建目录对象。已经为每个数据库创建了一个
名为DATA_PUMP_DIR的默认目录对象,无论数据库是新建的,还是由UNIX 或
Windows 平台上的脚本升级后得到的。系统会自动将访问DATA_PUMP_DIR目录的
权限授予给EXP_FULL_DATABASE和IMP_FULL_DATABASE角色。
DATA_PUMP_DIR目录是在下列位置之一创建的:
- <ORACLE_BASE>/admin/DB_UNIQUE_NAME/dpdump
- <ORACLE_HOME>/admin/DB_UNIQUE_NAME/dpdump
DATA_PUMP_DIR的确切目录路径规范取决于ORACLE_BASE和ORACLE_HOME系
统环境变量值,以及是否存在DATA_PUMP_DIR子目录。如果在目标系统上定义了
ORACLE_BASE,则使用该值。否则,使用ORACLE_HOME值。如果因某种原因而未
找到DATA_PUMP_DIR子目录,则使用以下默认路径:
ORACLE_HOME/rdbms/log
注:在任何情况下,必须具有对目录对象的适当访问权限才能执行所尝试的操作。要执行
导出,需要有所有文件的写权限;导入时,需要有转储文件的读权限以及日志文件和SQL
文件的写权限。
- 数据泵导出示例:调度
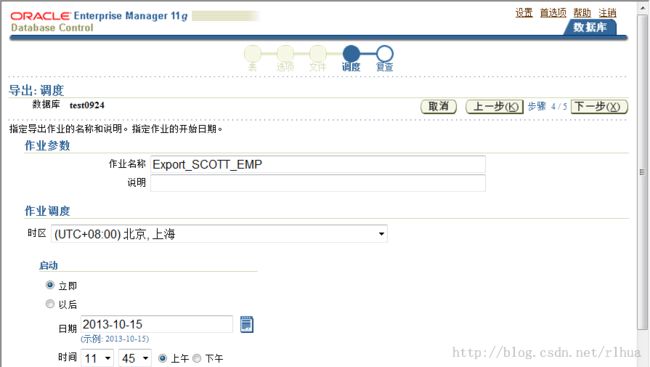
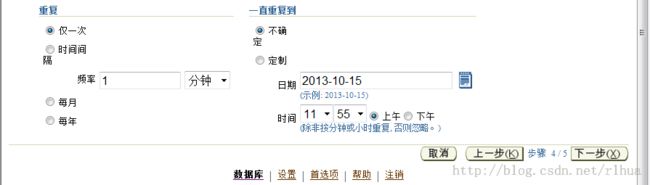
Oracle Enterprise Manager Database Control 可将数据泵作业(通过此向导创建的)调度为
可重复执行的作业。如果未指定“Job Name(作业名)”,则会使用系统生成的名称。
单击“Next(下一步)”继续执行导出操作。
- 数据泵导出示例:复查
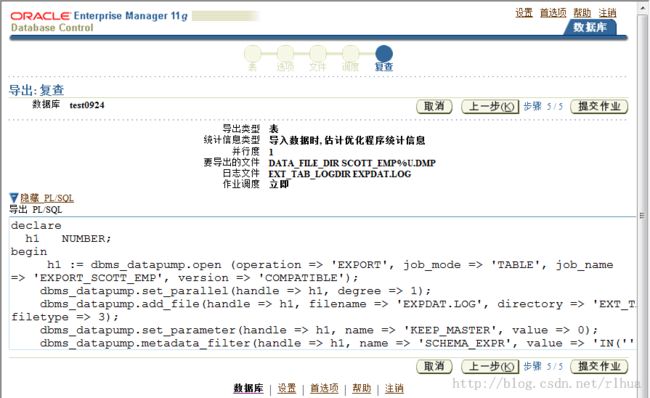
declare
h1 NUMBER;
begin
h1 := dbms_datapump.open (operation => 'EXPORT', job_mode => 'TABLE', job_name => 'EXPORT_SCOTT_EMP', version => 'COMPATIBLE');
dbms_datapump.set_parallel(handle => h1, degree => 1);
dbms_datapump.add_file(handle => h1, filename => 'EXPDAT.LOG', directory => 'EXT_TAB_LOGDIR', filetype => 3);
dbms_datapump.set_parameter(handle => h1, name => 'KEEP_MASTER', value => 0);
dbms_datapump.metadata_filter(handle => h1, name => 'SCHEMA_EXPR', value => 'IN(''SCOTT'')');
dbms_datapump.metadata_filter(handle => h1, name => 'NAME_EXPR', value => 'IN(''EMP'')');
dbms_datapump.add_file(handle => h1, filename => 'SCOTT_EMP%U.DMP', directory => 'DATA_FILE_DIR', filetype => 1);
dbms_datapump.set_parameter(handle => h1, name => 'INCLUDE_METADATA', value => 1);
dbms_datapump.set_parameter(handle => h1, name => 'DATA_ACCESS_METHOD', value => 'AUTOMATIC');
dbms_datapump.set_parameter(handle => h1, name => 'ESTIMATE', value => 'BLOCKS');
dbms_datapump.start_job(handle => h1, skip_current => 0, abort_step => 0);
dbms_datapump.detach(handle => h1);
end;
/
“Review(复查)”页显示的是已输入信息的概要,通过该页可查看将用于导出作业的
PL/SQL 过程语法。单击“Submit Job(提交作业)”按钮继续操作。作业提交后无法取
消,关闭浏览器不会有不利影响。
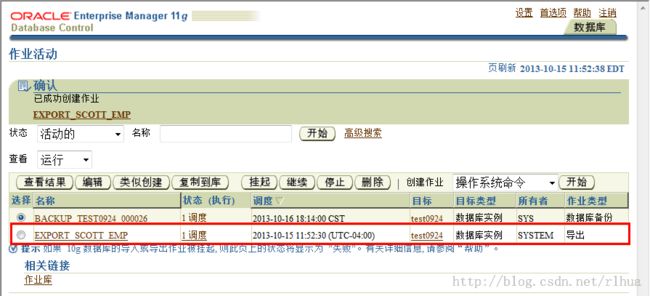
- 数据泵导入示例:impdp
数据泵可以通过命令行调用,以便进一步指定命令行选项。
$ impdp hr DIRECTORY=DATA_PUMP_DIR \
DUMPFILE=HR_SCHEMA.DMP \
PARALLEL=1 \
CONTENT=ALL \
TABLES="EMPLOYEES" \
LOGFILE=DATA_PUMP_DIR:import_hr_employees.log \
JOB_NAME=importHR \
TRANSFORM=STORAGE:n
数据泵导入示例:impdp
数据泵提供了用于执行导入和导出操作的命令行客户机。以上示例描述的是如何使用
impdp实用程序进行数据泵导入。使用命令行运行数据泵时,提供的选项更多一些。
- 数据泵导入:转换
你可以:
• 使用REMAP_DATAFILE重新映射数据文件
• 使用REMAP_TABLESPACE重新映射表空间
• 使用REMAP_SCHEMA重新映射方案
• 使用REMAP_TABLE重新映射表
• 使用REMAP_DATA重新映射数据
REMAP_TABLE= 'EMPLOYEES':'EMP'
数据泵导入:转换
由于对象元数据是以XML 的形式存储在转储文件集中,因此,在导入过程中形成DDL
时比较容易进行转换。数据泵导入支持多种转换:
• 在具有不同文件系统语义的平台之间移动数据库时,REMAP_DATAFILE十分有用。
• 使用REMAP_TABLESPACE可将对象从一个表空间移至另一个表空间。
• REMAP_SCHEMA提供原有的FROMUSER/TOUSER功能,可用于更改对象所有权。
• REMAP_TABLE可用于重命名整个表。
• REMAP_DATA可用于在插入数据时重新映射数据。
- 使用Oracle Enterprise Manager 监视数据泵作业

可以使用Enterprise Manager 图形用户界面(GUI) 监视所有数据泵作业,包括使用
expdp或impdp命令行界面创建的作业,或使用DBMS_DATAPUMP程序包创建的作业。
可以查看作业的当前状态,还可将状态更改为EXECUTE、STOP或SUSPEND。
要访问“Export and Import Jobs(导出和导入作业)”页,请在“Maintenance(维护)”
页的“Move Row Data(移动行数据)”区域中单击“Monitor Export and Import Jobs
(监视导出和导入作业)”链接。
- 以数据泵旧模式提供移植支持
• 辅助用户从imp和exp实用程序过渡到impdp和
expdp实用程序
由于导入脚本和导出脚本的使用很广泛,Oracle Database 11g发行版2 引入了数据泵旧
模式,辅助用户进行移植。数据泵实用程序:
1. 如果在命令行或脚本中出现了exp/imp特有的参数,则进入旧模式
2. 如果可行,则将旧参数映射到等效的expdp或impdp参数
3. 显示转换后的命令,以便您查看新语法并在时间允许的情况下修改脚本
4. 如果旧参数和新参数混杂出现,则退出旧模式(数据泵参数中混杂原有导出参数或
导入参数将导致数据泵直接退出,而不执行所需任务。)
最佳实践提示:Oracle 强烈建议查看新语法,并在时间
允许的情况下更改脚本。
- 数据泵旧模式
数据泵导出和导入实用程序:
• 仅读写数据泵格式的文件
• 在旧模式下,接受exp和imp实用程序命令
• 其中包括的旧模式参数具有下述特点:
– 可能与新语法完全相同:
FILESIZE=integer[B | K | M | G]
– 可能与新语法相类似:
QUERY= query_clause
– 如果命令已被数据泵默认值取代,则参数被忽略
BUFFER=integer
COMPRESS={y|n}
DIRECT={y|n}
– 如果新旧语法混杂,则将引发错误
数据泵旧模式
数据泵实用程序只处理数据泵格式的文件。(exp实用程序创建的文件必须由imp实用
程序来读取。)在数据泵实用程序中,采用数据泵旧模式可继续使用现有的脚本。但是,
如果要访问数据库的新功能,则必须使用新的数据泵语法。
实用程序如果发现exp或imp特有的参数,则进入旧模式。
• 使用的参数完全相同时,将不会对其进行任何更改。示例:
FILESIZE=integer[B | K | M | G]参数指定了转储文件的最大大小。
• QUERY=query_clause参数不会导致任何转换,但是请注意,与已经废弃的导出
实用程序相比,expdp实用程序处理查询时的限制要少一些。所以查询结果可能会
略有不同。
• 由于某些参数已被新的默认值取代,所以会被忽略。示例:
- BUFFER=integer参数将被忽略,因为expdp实用程序中不包含常规路径
模式。
- COMPRESS={y|n}参数将被忽略,因为expdp实用程序中不包含等效的参数。
- DIRECT={y|n}参数将被忽略,因为expdp实用程序将判断请求的导出操作
应使用直接路径还是外部表模式。
• exp/imp参数与数据泵参数混杂在一起会导致作业失败。
• 旧模式参数:
– 如果可行,则映射到数据泵参数:
consistent={y|n} -> FLASHBACK_TIME
GRANTS=n -> EXCLUDE=CONSTRAINTS
INDEXES=n -> EXCLUDE=INDEX
LOG=filename -> LOGFILE=filename
FILE=filename -> dumpfile=directory-object:filename
– 可能与新语法相类似,但不完全相同:
FEEDBACK=integer -> STATUS
– 如果与新数据泵不兼容,则会出错:
VOLSIZE=integer
使用数据泵旧模式可将废弃的脚本转换为当前版本。以下几个参数可以映射到新语法:
• 数据泵可识别当前时间并将CONSISTENT={y|n}参数映射到FLASHBACK_TIME
参数。
• 将GRANTS=n参数重新映射到EXCLUDE=GRANT。
• 将INDEXES=n参数重新映射到EXCLUDE=INDEX。
• 将LOG=filename参数重新映射到LOGFILE=filename。日志文件内容(包括
参考性消息和错误消息)皆为expdp格式。
• 将FILE=filename参数重新映射到dumpfile=directory-object:filename。
但是如果expdp实用程序无法找到指向现有目录对象的路径,则将中止。
参数可以映射,但新功能与以前的不同。将FEEDBACK=integer参数重新映射到
STATUS。由于返回的不仅仅是处理的行数,还包括导出作业的状态,因此该映射不是
一种直接映射。
如果参数与数据泵不兼容,则会导致作业中止。exp实用程序的VOLSIZE=integer
参数指定了磁带卷大小。数据泵不使用磁带机,磁带由Oracle Secure Backup 负责管理。
- 管理文件位置
• 原有的exp和imp实用程序:全限定的文件名
• 用于指定文件位置的数据泵目录对象
– 默认值(早期版本):DATA_PUMP_DIR参数
– 新增可选DATA_PUMP_DIR_schema-name目录对象
– 使用CREATE DIRECTORY和GRANTSQL 命令进行管理
– 出现以下情况时,为默认位置(与是否在旧模式下无关):
— 命令行中不包含DIRECTORY参数
— 用户不具备EXP_FULL_DATABASE权限
管理文件位置
原有实用程序与数据泵实用程序处理文件位置的方式之所以不同,是因为原有实用程序是
基于客户机的(文件名皆为全限定的文件名)。
而数据泵实用程序则是基于服务器的。数据泵实用程序要求在指定文件位置时使用目录对
象。所使用的目录对象必须是方案可访问的对象。在早期版本中,由DATA_PUMP_DIR
初始化参数来设置默认位置。
此功能并未引入DBA 必须执行的新任务,而是引入了一个可选的
DATA_PUMP_DIR_<schema-name>目录对象。
如果选择使用CREATE DIRECTORY和
GRANTSQL 命令创建该目录对象,则指定的方案即可使用数据泵导出或导入实用程序
(而这会影响到常规服务器资源,如CPU、内存使用量和磁盘使用量)。
如果未在命令行中指定参数,且用户不具备EXP_FULL_DATABASE权限,则数据泵实用
程序将使用此目录对象。无论是否在旧模式下,数据泵实用程序都采用此方式。
- SQL*Loader:概览
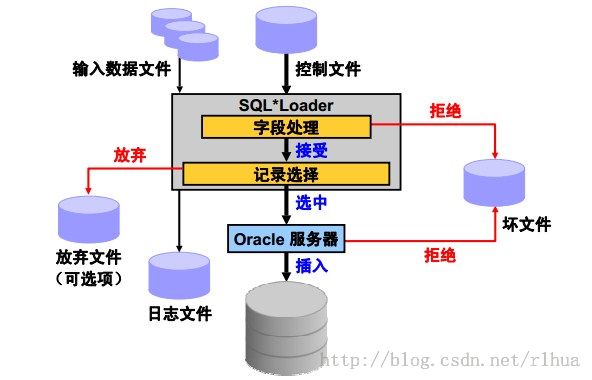
SQL*Loader 可将外部文件中的数据加载到Oracle DB 的表中。它具有一个功能强大的数
据分析引擎,因此对数据文件中数据的格式没有什么限制。
SQL*Loader 使用以下文件:
输入数据文件:SQL*Loader 从控
制文件中指定的一个或多个文件(或操作系统的等效文
件)中读取数据。从SQL*Loader 的角度看,数据文件中的数据是按记录组织的。一个
特定的数据文件可采用固定记录格式、可变记录格式或流记录格式。可通过控制文件中
的INFILE参数指定记录格式。如果未指定记录格式,默认格式为流记录格式。
控制文件:控制文件是一个文本文件,它是使用SQL*Loader 可识别的语言编写的。控制
文件指示SQL*Loader 在何处查找数据、如何分析和解释数据以及在何处插入数据等等。
尽管不能精确地定义,但可认为控制文件包含三个段。
• 第一段包含如下所示的会话范围信息:
- 全局选项,如输入数据文件名和要跳过的记录
- 用于指定输入数据位置的INFILE子句
- 要加载的数据
• 第二个段包括一个或多个INTO TABLE块。其中每一个块都包含要在其中加载数据
的表的信息(如表名和表列)。
• 第三个段是可选段,如果存在,则其中包含输入数据。
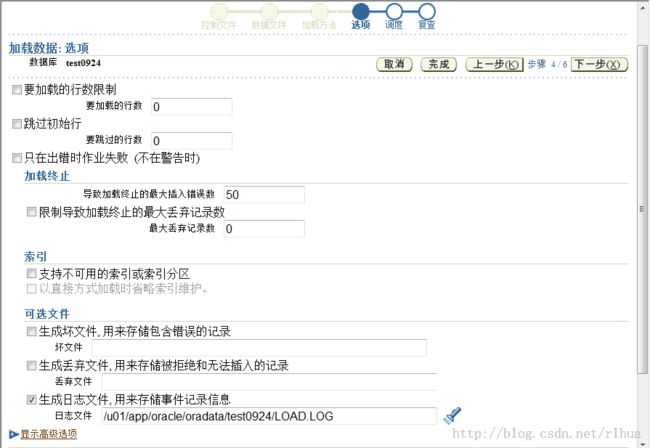
日志文件:SQL*Loader 开始执行时,会创建日志文件。如果不能创建日志文件,执行就
会终止。日志文件包含加载操作的详细说明,包括加载过程中发生的任何错误的说明。
坏文件:坏文件中包含被SQL*Loader 或Oracle DB 拒绝的记录。当输入格式无效时,
SQL*Loader 就会拒绝数据文件记录。SQL*Loader 接受处理某一数据文件记录后,会将该
数据文件记录发送到Oracle DB,以便能够作为一行插入到表中。如果Oracle DB 确定该
行有效,就会将该行插入到表中;如果确定该行无效,则会拒绝该记录,然后
SQL*Loader 会将该记录放入坏文件中。
放弃文件:仅当需要这种文件并且指定了应启用放弃文件时,才会创建此文件。放弃文件
中包含的记录是因不符合控制文件指定的任何记录选择标准而从加载中过滤掉的记录。
- 使用SQL*Loader 加载数据
使用“Load Data from User Files(从用户文件加载数据)”向导,可将平面文件中的数据
加载到Oracle DB 中。
要显示该向导,请选择Enterprise Manager 中的“Data Movement > Move Row Data > Load
Data from User Files(数据移动> 移动行数据> 从用户文件加载数据)”。

- SQL*Loader 控制文件
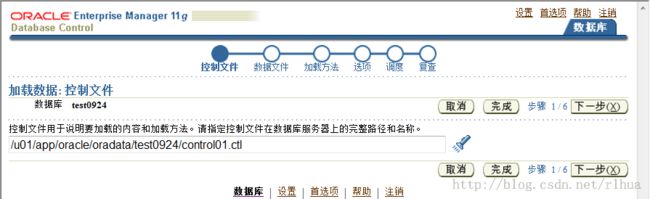
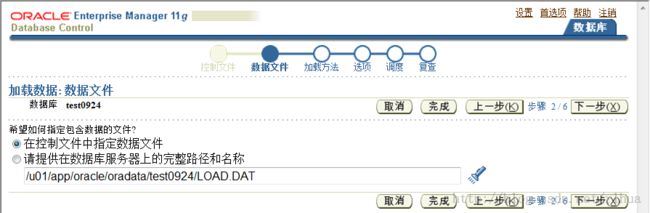
SQL*Loader 控制文件通知SQL*Loader 以下信息:
• 要加载数据的位置
• 数据格式
• 配置详细资料:
– 内存管理
– 记录拒绝
– 中断的加载处理详细资料
• 数据操纵详细资料
SQL*Loader 控制文件
SQL*Loader 控制文件是一个文本文件,其中包含数据定义语言(DDL) 指令。DDL 用来控
制SQL*Loader 会话的以下方面:
• SQL*Loader 在何处查找要加载的数据
• SQL*Loader 希望如何确定数据的格式
• SQL*Loader 在加载数据时采用了哪些配置(包括内存管理、选择与拒绝标准、中断
的加载处理等等)
• SQL*Loader 如何处理正在加载的数据
1 -- This is a sample control file
2 LOAD DATA
3 INFILE 'SAMPLE.DAT'
4 BADFILE 'sample.bad'
5 DISCARDFILE 'sample.dsc'
6 APPEND
7 INTO TABLE emp
8 WHEN (57) = '.'
9 TRAILING NULLCOLS
10 (hiredate SYSDATE,
deptno POSITION(1:2) INTEGER EXTERNAL(3)
NULLIF deptno=BLANKS,
job POSITION(7:14) CHAR TERMINATED BY WHITESPACE
NULLIF job=BLANKS "UPPER(:job)",
mgr POSITION(28:31) INTEGER EXTERNAL
TERMINATED BY WHITESPACE, NULLIF mgr=BLANKS,
ename POSITION(34:41) CHAR
TERMINATED BY WHITESPACE "UPPER(:ename)",
empno POSITION(45) INTEGER EXTERNAL
TERMINATED BY WHITESPACE,
sal POSITION(51) CHAR TERMINATED BY WHITESPACE
"TO_NUMBER(:sal, '$99,999.99')",
comm INTEGER EXTERNAL ENCLOSED BY '(' AND '%'
":comm * 100"
)
此示例控制文件的说明(按行号)如下所示:
1. 注释可出现在文件命令段中的任何位置,但绝不能出现在数据内部。任何注释之前
都有两个连字符。双连字符右边的所有文本(直至行尾)都会被忽略。
2. LOAD DATA语句通知SQL*Loader 开始新数据加载操作。如果要继续执行已中断的
加载操作,请使用CONTINUE LOAD DATA语句。
3. INFILE关键字指定含有待加载数据的数据文件的名称。
4. BADFILE关键字指定要在其中放置拒绝记录的文件的名称。
5. DISCARDFILE关键字指定要在其中放置放弃记录的文件的名称。
6. APPEND关键字是将数据加载到非空表时可以使用的选项之一。要将数据加载到空表
中,请使用INSERT关键字。
7. 使用INTO TABLE关键字可标识表、字段和数据类型。此关键字定义了数据文件记
录与数据库表之间的关系。
8. WHEN子句指定在SQL*Loader 加载数据之前每条记录必须匹配的一个或多个字段条
件。在此示例中,SQL*Loader 仅当第57 个字符为小数点时才加载记录。这个小数点
用于分隔字段中的美元和美分,如果SAL不包含任何值,这个小数点会导致记录被
拒绝。
9. TRAILING NULLCOLS子句提示SQL*Loader 将记录中不存在的任何相关占位列视
为空列。
10.控制文件的余下部分包含一些字段列表,用于提供正在加载的表中列格式的信息。
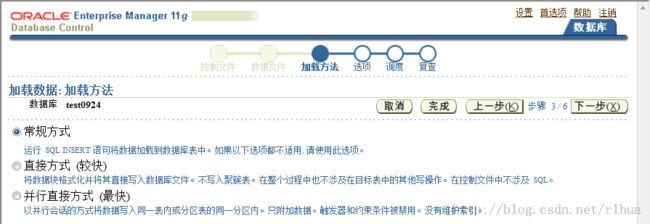
- 加载方法
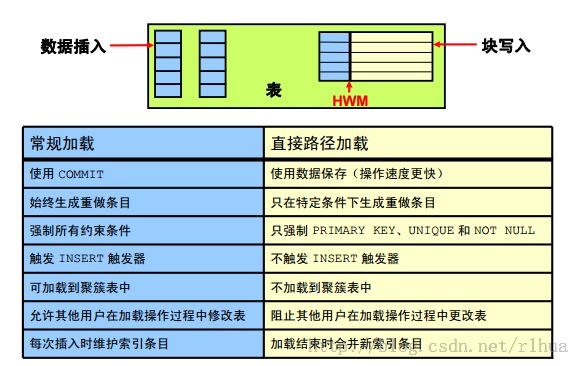
直接路径加载与常规路径加载的比较
保存数据的方法
常规路径加载通过执行SQL INSERT语句,将表填充到Oracle DB 中。直接路径加载通
过格式化Oracle 数据块并将其直接写入数据库文件,消除了大部分Oracle DB 开销。直接
加载不与其他用户争用数据库资源,因此其数据加载速度通常与磁盘速度相差无几。常规
路径加载使用SQL 处理和数据库COMMIT操作来保存数据。插入记录数组后要执行
COMMIT操作。每次数据加载可能涉及多个事务处理。
直接路径加载使用数据保存将数据块写入Oracle 数据文件。这就是为什么直接路径加载
比常规路径加载快很多的原因。
通过以下特性可区分数据保存与COMMIT的差异:
• 在数据保存期间,只有完整的数据库块才写入数据库中。
• 这些块是在按照表的高水位标记(HWM) 写入的。
• 完成数据保存后,HWM 会移动。
• 完成数据保存后不会释放内部资源。
• 完成数据保存不会结束事务处理。
• 每次执行数据保存时不会更新索引。
- 外部表
外部表是以文件形式存储在Oracle DB 外的操作系统上的
只读表。
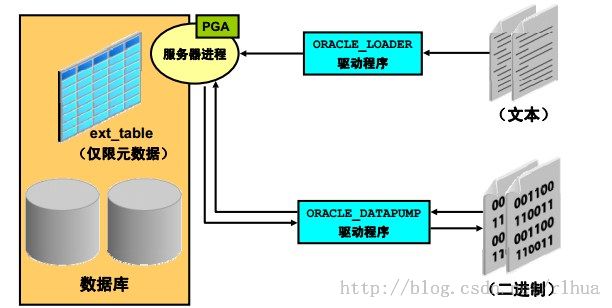
外部表
外部表访问外部源中的数据时,就好像该数据位于数据库内的表中一样。你可以连接到数
据库并使用DDL 创建外部表的元数据。外部表的DDL 由两部分组成:一部分描述Oracle
DB 的列类型,另一部分描述如何将外部数据映射到Oracle DB 的数据列。
外部表不描述数据库中存储的任何数据,也不描述数据如何存储在外部源中。而是描述外
部表层怎样向服务器提供数据。访问驱动程序和外部表层会对外部文件中的数据进行必要
的转换,使这些数据与外部表定义相符,这是访问驱动程序和外部表层的责任。外部表为
只读表,因此无法执行DML 操作,也不能对其创建索引。
外部表使用两种访问驱动程序。ORACLE_LOADER访问驱动程序只能用于读取外部表中的
表数据并将其载入数据库。它使用
文本文件
作为数据源。ORACLE_DATAPUMP访问驱动程
序既可以将表数据从外部文件载入数据库中,也可以将数据从数据库卸载到外部文件中。
它使用
二进制文件作为外部文件。这些二进制文件与impdp和expdp实用程序所用文件
的格式相同,并可与之互换。
- 外部表的优点
• 可直接使用外部文件中的数据或将数据加载到另一个
数据库。
• 可以同时查询外部数据和数据库中驻留的表,并可将
外部数据与数据库中的表直接联接,而不必先加载外
部数据。
• 复杂查询的结果可卸载到外部文件中。
• 可组合来自不同源的已生成文件在加载中使用。
外部表的优点
为外部表创建的数据文件是可移动的数据文件,可用作同一数据库或不同数据库中另一外
部表的数据文件。可以同时查询外部数据和数据库中驻留的表,并可将外部数据与数据库
中的表直接联接,而不必先加载外部数据。可选择让应用程序使用SELECT命令直接访问
外部表,也可选择先将数据加载到目标数据库。
复杂查询的结果可使用ORACLE_DATAPUMP访问驱动程序卸载到外部文件中。
可在另一外部表的LOCATION子句中指定由不同外部表填充的所有数据文件。这样,可
轻松地将多个源的数据汇集到一起。唯一的限制是,所有外部表的元数据必须完全相同。
- 使用ORACLE_LOADER定义外部表
CREATE TABLE
extab_employees
(employee_id NUMBER(4),
first_name VARCHAR2(20),
last_name VARCHAR2(25),
hire_date DATE)
ORGANIZATION EXTERNAL
( TYPE
ORACLE_LOADER
DEFAULT DIRECTORY extab_dat_dir
ACCESS PARAMETERS
( records delimited by newline
badfile extab_bad_dir:'empxt%a_%p.bad'
logfile extab_log_dir:'empxt%a_%p.log'
fields terminated by ','
missing field values are null
( employee_id, first_name, last_name,
hire_date char date_format date mask "dd-mon-yyyy"))
LOCATION ('empxt1.dat', 'empxt2.dat') )
PARALLEL REJECT LIMIT UNLIMITED;
使用ORACLE_LOADER定义外部表
外部表的元数据是使用SQL 语言在数据库中创建的。ORACLE_LOADER访问驱动程序使
用SQL*Loader 语法来定义外部表。此命令并不创建外部文本文件。
示例显示创建了三个目录对象(extab_dat_dir、extab_bad_dir和
extab_log_dir),并且这三个目录对象已映射到用户有权访问的现有操作系统目录。
访问extab_employees表时,将使用SQL*Loader 功能来加载该表,并由此创建相应
日志文件和坏文件。
最佳实践提示:如果有大量数据要加载,请为加载操作启用PARALLEL:
ALTER SESSION ENABLE PARALLEL DML;
- 使用ORACLE_DATAPUMP填充外部表
CREATE TABLE
ext_emp_query_results
(first_name, last_name,department_name)
ORGANIZATION EXTERNAL
(
TYPE
ORACLE_DATAPUMP
DEFAULT DIRECTORY ext_dir
LOCATION ('emp1.exp','emp2.exp','emp3.exp')
)
PARALLEL
AS
SELECT
e.first_name,e.last_name,d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id AND
d.department_name in
('Marketing', 'Purchasing');
使用ORACLE_DATAPUMP填充外部表
示例显示外部表填充操作如何有选择地导出由联接EMPLOYEES和DEPARTMENTS两个
表生成的一组记录。
由于外部表可能非常大,因此可使用并行填充操作将数据卸载到外部表。与外部表并行查
询相反,并行填充操作的并行度受到访问驱动程序可写入的并行文件数目的限制。在特定
时间点,决不能有多个并行执行服务器写入同一个文件。
LOCATION子句中的文件数必须与指定的并行度匹配,因为每个输入/输出(I/O) 服务器进
程都需要使用自己的文件。此时,会忽略指定的任何多余文件。如果指定的并行度没有足
够的文件数,则会降低并行度来匹配LOCATION子句中的文件数。
填充后的外部表为只读表。SELECT命令可以很复杂,通过该命令可将特定信息填充到外
部表中。然后就可以将与二进制数据泵文件具有相同文件结构的外部表移植到另一系统,
并使用impdp实用程序来实施导入或以外部表的方式进行读取。
- 使用外部表
• 查询外部表
SQL> SELECT * FROM extab_employees;
• 查询外部表并将其与内部表进行联接
SQL> SELECT e.employee_id, e.first_name, e.last_name,
d.department_name FROM departments d, extab_employees e
WHERE d.department_id= e.department_id;
• 将数据从外部表附加到内部表
SQL> INSERT /*+ APPEND */ INTO hr.employees SELECT * FROM
extab_employees;
使用外部表
可以像查询内部数据库表一样查询外部表。第一个示例说明的是查询外部表
EXTAB_EMPLOYEES,并仅显示结果。结果未存储在数据库中。
第二个示例说明的是联接内部表DEPARTMENTS与外部表EXTAB_EMPLOYEES,并仅显示
结果。
第三个示例说明的是查询和加载外部表中的数据,然后直接将数据附加到
内部表的数据之后。
- 数据字典
可在以下位置查看关于外部表的信息:
• [DBA| ALL| USER]_EXTERNAL_TABLES
• [DBA| ALL| USER]_EXTERNAL_LOCATIONS
• [DBA| ALL| USER]_TABLES
• [DBA| ALL| USER]_TAB_COLUMNS
• [DBA| ALL]_DIRECTORIES
数据字典
以上数据字典视图列出了以下表信息:
[DBA| ALL| USER]_EXTERNAL_TABLES:数据库中外部表的特定属性。
[DBA| ALL| USER]_EXTERNAL_LOCATIONS:外部表的数据源。
[DBA| ALL| USER]_TABLES:数据库中关系表的说明。
[DBA| ALL| USER]_TAB_COLUMNS:数据库中表、视图和聚簇表的列的说明。
[DBA| ALL]_DIRECTORIES:描述数据库中的目录对象。