内容匹配广告投放技术4:网盟CTR预估(百度文库课程)
该文是百度文库课程
《计算广告学之内容匹配广告&展示广告原理、技术和实践》的课程笔记,感谢百度!
课程地址 http://wenku.baidu.com/course/view/1488bfd5b9f3f90f76c61b8d
第三章:网盟CTR预估
第三章主要包括三小节:CTR预估背景,CTR预估特点,CTR预估模型
CTR即广告点击率
第一节:CTR预估背景
在点击计费时,用得最多的是广义二阶价格拍卖体系。
b是广告主愿意出价的价格,p是预估CTR概率(即点击的可能性有多少)。那么b*p表示展现一次广告最有可能获得的收益是多少。
最后实际收费是按照折算后的计费方式,广告主自己的广告支出费为后一名的收益比上自己的CTR,意思是价格不能再比这个值低了,再低就不能获得这样的排名了。比如 b1<b2p2/p1 的话,那么则左右同乘以p1,得 b1p1<p2p2,那么1就不是winner了。这样的话,可以鼓励广告主,如果你想每点一次少付钱,那么可以优化分母CTR,p,将CTR,p优化成最大。

第二节:CTR预估特点
本节主要讲述CTR预估在机器学习中有什么特点。
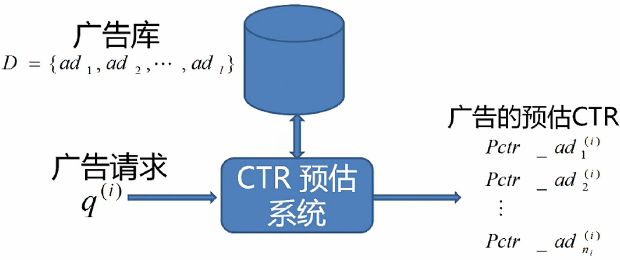
广告请求query(i)表示用户访问某个网站时,网站会对网盟发出一个广告请求,同时这个请求还会传送一些该用户特征,该网站特征等,然后网盟(CTR预估系统)会在很短时间内选出一个广告来填充这个网站的广告位。从这个过程中可以看到CTR预估系统的特点:1)响应快;2)库量大;3)持续学习能力(即如果之前出了一些不好的广告,预估系统能否学习,为后面作出更好的选择)
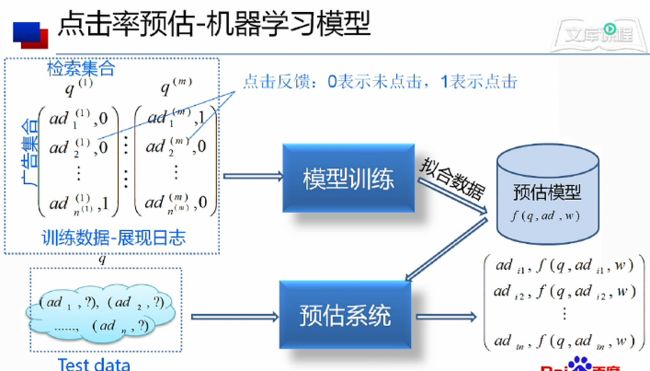
以下是整个点击率预估-机器学习模型的概要。训练数据就是通过展现日志得到了,一个网站的请求q(i)下展示ad1,ad2...adn个广告,后面的0,1表示是否点击了。得到庞大的广告-检索对集合训练数据后,就可以进行模型训练得到预估模型f(q,ad,w),然后测试数据(adi,?)表示该广告adi在q,w的条件(参数)下的预估模型是多少。
************************************************************************************

Online在线算法:每一个新广告到来的时候模型都更新一次。Batch算法:每一批新广告到来的时候模型都更新一次。一般Batch算法的数据量大较稳定,在线算法的时效性更强,但数据较少稳定性较差。

如果老投放精准的老广告,这些老广告能拿到的收益最大,但新广告也要需要投放,也需要投放后进行精准投放的学习,这就涉及到短期收益和长期收益的问题。

第三节:CTR预估模型
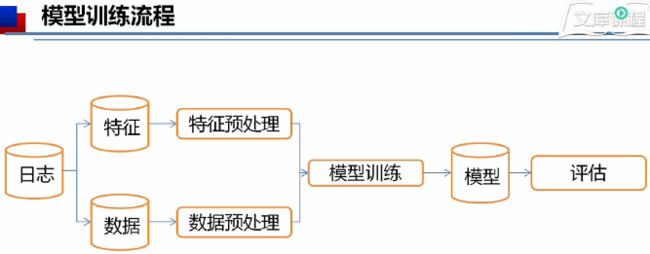
流程概要,然后分细讲解
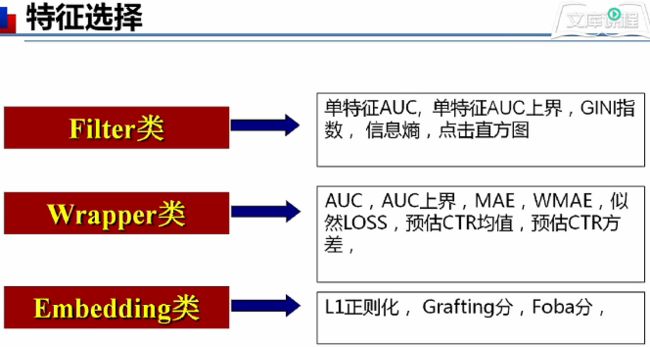
特征进行数值化表示。
one-host编码:比如站点表示,10w个站点用长度为10w的01串表示,表示某站点时某位为1。

由于特征数巨大,数据稀疏,因此要进行特征选择。
Filter类:只考虑单个特征;
Wrapper类:克服单特征缺点,考虑特征之间的交叉组合关系。缺点是计算量大;
Embedding类:综合Filter类和Wrapper类。
AUC的英文全称为 Area Under Curve,AUC的意思是曲线下面积,AUC经常用于统计ROC曲线的面积,用来量化评估广告的CTR质量。
**************************************************************************************************************

回归模型和参数(β)学习方法。

MPI模型训练的特点是内存都很大,数据和计算是分离的。MPI主要是在计算的角度进行设计,Hadoop主要是在可扩展性的角度进行设计。

线上评估一般会将流量平均分到线上系统和线上评估系统,然后进行比较各个指标。

*************************************************************************************************************
