Hadoop中的RPC实现——服务器端通信组件
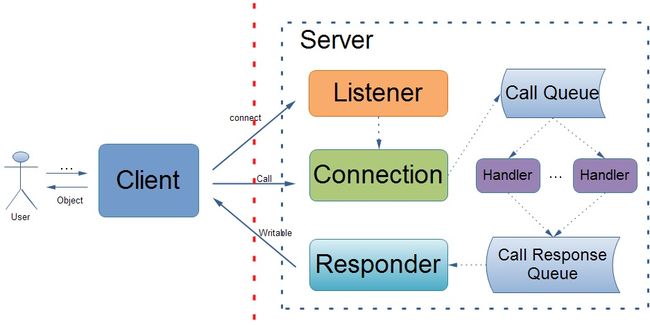
在前一篇博文中,我已经详细的讲解了Hadoop RPC中客户端通信组件的实现,与之对应的就会有一套服务器端通信组件的实现。Hadoop RPC的服务器端采用了多线程的设计,即服务器会开启多个处理器(后天线程)来处理所有客户端发送过来的RPC调用请求,所以在服务器端主要包括三个组件:监听器(Listener)、处理器(多个Handler)、响应发送器(Responder)。接下来我将主要围绕这三大组件来介绍服务器端的工作原理。
还是先来看看与服务器端相关的实现类吧!

1.Server类
从上面的类图中,我们可以看出 Server类的核心是服务器端的三大组件,因此Server类的本质工作就是对这三大组件进行管理,如启动/停止组件等。
- private String bindAddress; //服务端绑定的地址
- private int port; //服务端监听端口
- private int handlerCount; //处理器的数量
- private Class<? extends Writable> paramClass; //调用参数的解析器类
- private int maxIdleTime; //一个客户端连接后的最大空闲时间
- private int thresholdIdleConnections; // 可维护的最大连接数量
- int maxConnectionsToNuke;
- private int maxQueueSize; //处理器Handler实例队列大小
- private int socketSendBufferSize; //Socket Buffer大小
- private final boolean tcpNoDelay; //TCP连接是否不延迟
- volatile private boolean running = true; //Server是否运行
- private BlockingQueue<Call> callQueue; //待处理的rpc调用队列
- //维护客户端连接的列表
- private List<Connection> connectionList
- //监听Server Socket的线程,为处理器Handler线程创建任务
- private Listener listener = null;
- private Responder responder = null;//响应客户端RPC调用的线程,向客户端调用发送响应信息
- private int numConnections = 0; //连接数量
- private Handler[] handlers = null;//处理器Handler线程数组
maxQueueSize=handlerCount*Max_QUEUE_SIZE_PER_HANDLER
目前Max_QUEUE_SIZE_PER_HANDLER的值为100。
2.Listener类
- private long lastCleanupRunTime; //上一次清理客户端连接的时间
- private long cleanupInterval; //清理客户端端连接的时间间隔
- private int backlogLength; //允许客户端等待连接的队列长度
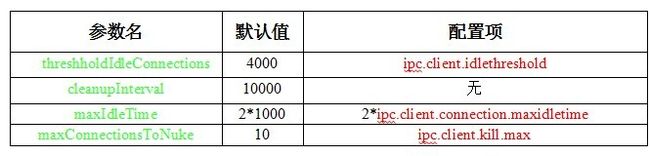
监听器Listener被用来侦听服务器的服务地址,处理客户端的连接请求。当发现客户端发起连接请求时,监听器会创建一个对应的Connection对象,当发现客户端发送来RPC调用请求时,就调用对应的Connection来处理。这里需要注意的是客户端在连接成功之后并不会马上向其发送RPC调用,而是首先发送验证信息(这一点在上一篇博文中谈到过),而服务器端也会先验证这些信息(协议版本号、用户权限等),当然这个验证在Connection的整个生命周期中只有一次,就是刚开始的时候。同时,Listener还要完成的一个工作就是对客户端连接Connection进行管理。首先,Listener限制了客户端等待连接的数量,也就说同时不能超过backlogLength个客户端等待和服务器建立连接,这个值的默认大小为128,但也可以通过配置文件来设置,对应的配置项为:ipc.server.listen.queue.size。当服务器端连接的客户端数量超过threshholdIdleConnections时就会对客户端连接进行每 cleanupInterval ms一次的清理,清理的对象主要是那些空闲时间超过 maxIdleTime ms的客户端连接,即关闭掉这些客户端连接Connection,同时每一次清理(关闭)Connection的数量又不能超过maxConnectionsToNuke。这些参数对应的值如下:
3.Connection类
Connection类主要用来接受客户端发送过来的RPC调用,即把网络网络二进制数据进行解析,最后封装成一个Call对象,这个对象实际上就是表示一次RPC调用所需要的所有相关参数。之后把这个Call添加到待处理的队列callQueue中。当然,Connection每一次在接收到一个Call之后就会更新它的lastContact值,Listener主要根据该值来计算当前Connection的空闲时间。
4.Handler类
每一个处理器总是不停的从待处理的Call队列callQueue中获取一个Call来处理,处理完之后就会把该Call交给响应发送器Responder来处理,对于已经处理过的Call,无论是成功还是失败,其处理结果都存放在Call的response属性中了。
5.Responder类
对于处理器已经处理过的Call,Responder不会马上将该Call的处理结果发送回客户端除非该客户端只有这一个call调用,否则Responder会把这个已经处理好的Call加入到其客户端连接Connection的内部队列responseQueue中,也就是说Responder是以Connection为调度单位来处理的。另外,还有一个检查机制就是对于某一个客户端的一次批量的RPC调用,如果在 PURGE_INTERVAL ms之后不能全部处理完的话,服务器就会放弃为该客户端提供服务,断开与它之前的网络连接。目前,PURGE_INTERVAL的值为900000。
服务器端的工作流程如图所示: