mips64高精度时钟引起ktime_get时间不准,导致饿狗故障原因分析
重点关注关中断的情况。临时做了一个版本,在CPU 0上监控所有非0 CPU的时钟中断计数,检查他们在100ms内是否增加。如果否,则认为此
CPU关中断。另外,在高精度时钟中断处理函数hrtimer_interrupt以及时钟中断总入口打点,记录最长耗时。
关中断检测代码如下:
void check_timer_start(void)
{
int i = 1;
for(;i<32;++i)
cpu_timer_tick[i]=kstat_irqs_cpu(7, i);
}
void check_timer_end(void)
{
int i = 1;
int save_console_level = console_loglevel;
for(;i<32;++i){
/*should I dump only once?*/
if(cpu_flag_dump[i]==1)
continue;
if((kstat_irqs_cpu(7, i)>MIN_TICK_START)&&
(cpu_timer_tick[i]==kstat_irqs_cpu(7, i))){
console_loglevel = 4;
mips_send_nmi_single(i);
printk("send nmi to cpu[%d]\n",i);
cpu_flag_dump[i] = 1;
system_is_down = 1;
dump_max_data();
}
}
console_loglevel = save_console_level;
}
void check_dead_cpu(void)
{
if(system_is_down)
return;
if(time_after64(jiffies_64, last_tick_cpu0+sysctl_dead_time)){
last_tick_cpu0=jiffies_64;
if(cpu0_checking){
cpu0_checking = 0;
check_timer_end();
}else{
cpu0_checking = 1;
check_timer_start();
}
}
}
通常情况下,上述代码正常运行的前提是,CPU 0的时钟中断运作正常。实际上,如果CPU 0关中断超过一定时间,这种检测是否还可靠?首先
,CPU 0负责更新jiffies。根据关中断检测代码的逻辑,每隔100ms为一个周期,如果这段时间某非0的CPU的时钟中断计数不变,则认为此CPU
关中断。假设CPU 0的时钟中断关闭了一段时间,则这段时间内jiffies可能未更新,在下一次CPU 0的时钟中断到来时,会进行jiffies补偿。
那么是否可能存在时钟只过去了一个tick,而jiffies却跳变了100 tick的情况?也就是说,jiffies一次补偿达到了100 ticks?根据
tick_do_update_jiffies64的实现,jiffies进行补偿的本次中断距离上次中断之间,一定是发生了问题,不可能发生时间只经历了1个tick,
而却补偿超过1个tick。(注意32bit中需要用get_jiffies64()获取jiffies64)
当检测到有CPU关中断后,则往此CPU发送nmi中断,打印其回溯。
通过上述检测方式,抓到的典型现场如下:
一个core内的4个子线程全部挂死。其中一个死在中断入口,另外三个在用户态。
CPU 20:
errepc:0x806011a0
epc:0x773160
eirr:0x88
status:6000fff7 KX SX UX USER ERL EXL IE
CPU 21:
errepc:0x7719e4
epc:0x7585b4
eirr:0x0
status:6000fff5 KX SX UX USER ERL IE
CPU 22:
errepc:0xf64f6cc
epc:0x7585b4
eirr:0x0
status:6000fff5 KX SX UX USER ERL IE
CPU 23:
errepc:0x4cb474
epc:0x7585b4
eirr:0x0
status:6000fff5 KX SX UX USER ERL IE
CPU 20被nmi中断打断的地方,位于外部中断入口handle_int。
虽然跟故障无关,这里也顺带讲一下,xlp的handle_int是经过rollback_handle_int包装的。
这个是什么意思? xlp的idle是这么设计的:
LEAF(r4k_wait)
/* start of rollback region */
LONG_L t0, TI_FLAGS($28)
nop
andi t0, _TIF_NEED_RESCHED
bnez t0, 1f
nop
wait
/* end of rollback region (the region size must be power of two) */
.set pop
1:
jr ra
END(r4k_wait)
考虑这种情况,如果cpu在wait前被中断,返回现场后,将继续在wait处等待下一个时钟周期到来,才可能再次有调度点检查。为了增强实时性
,在handle_int前包装一个rollback的检测:
rollback_handle_int
MFC0 k0, CP0_EPC
PTR_LA k1, r4k_wait
ori k0, 0x1f /* 32 byte rollback region */
xori k0, 0x1f
bne k0, k1, 9f
MTC0 k0, CP0_EPC
9:
NESTED(handle_int, PT_SIZE, sp)
这段代码检查如果cpu是在idle里被中断,则恢复现场时直接将pc指向r4k_wait的入口,进行调度点检测,这样可以避免之前说的wait延时。
再回到故障信息,status显示在用户态。这就有点说不过去了。按道理,既然是在外部中断被nmi打断的,那么status自然应该是在内核态而不
是用户态。打印出USER的条件是status的KSU为10,至于KSU是硬件还是内核代码我们这里暂且不管,继续往下分析。根据内核的中断流程:
a) SAVE_ALL保存现场
b) 置status寄存器的CU0位表示可以访问协处理器0。
在出问题时的status现场,CU0还是0,说明可能在SAVE_ALL过程中或者之前就被nmi打断了。
于是做了一个实验,写了一个用户态死循环程序,不断的给此进程发nmi ipi中断。回溯发现,系统有一定几率会出现被在handle_int里被nmi
打断的情况,并且此时status显示KSU为10,即用户态。由此推测,可能出现这种情况:
程序在用户态死循环
来了一个中断,刚进入口,系统来不及更新status的KSU为内核态
被nmi打断,显示此时在用户态
当然,上述的分析只是推测,对故障定位本身没有影响,只是提出在此以备将来参考。
其实抓到的现场,除了在handle_int入口外,还有在tlb refill入口处的现场。
因此问题就变成了,为什么会在handle_int停住,或者是否发生了中断嵌套?
于是在handle_int以及tlb refill添加统计计数,看cpu此时到底在做什么。
CPU关中断。另外,在高精度时钟中断处理函数hrtimer_interrupt以及时钟中断总入口打点,记录最长耗时。
关中断检测代码如下:
void check_timer_start(void)
{
int i = 1;
for(;i<32;++i)
cpu_timer_tick[i]=kstat_irqs_cpu(7, i);
}
void check_timer_end(void)
{
int i = 1;
int save_console_level = console_loglevel;
for(;i<32;++i){
/*should I dump only once?*/
if(cpu_flag_dump[i]==1)
continue;
if((kstat_irqs_cpu(7, i)>MIN_TICK_START)&&
(cpu_timer_tick[i]==kstat_irqs_cpu(7, i))){
console_loglevel = 4;
mips_send_nmi_single(i);
printk("send nmi to cpu[%d]\n",i);
cpu_flag_dump[i] = 1;
system_is_down = 1;
dump_max_data();
}
}
console_loglevel = save_console_level;
}
void check_dead_cpu(void)
{
if(system_is_down)
return;
if(time_after64(jiffies_64, last_tick_cpu0+sysctl_dead_time)){
last_tick_cpu0=jiffies_64;
if(cpu0_checking){
cpu0_checking = 0;
check_timer_end();
}else{
cpu0_checking = 1;
check_timer_start();
}
}
}
通常情况下,上述代码正常运行的前提是,CPU 0的时钟中断运作正常。实际上,如果CPU 0关中断超过一定时间,这种检测是否还可靠?首先
,CPU 0负责更新jiffies。根据关中断检测代码的逻辑,每隔100ms为一个周期,如果这段时间某非0的CPU的时钟中断计数不变,则认为此CPU
关中断。假设CPU 0的时钟中断关闭了一段时间,则这段时间内jiffies可能未更新,在下一次CPU 0的时钟中断到来时,会进行jiffies补偿。
那么是否可能存在时钟只过去了一个tick,而jiffies却跳变了100 tick的情况?也就是说,jiffies一次补偿达到了100 ticks?根据
tick_do_update_jiffies64的实现,jiffies进行补偿的本次中断距离上次中断之间,一定是发生了问题,不可能发生时间只经历了1个tick,
而却补偿超过1个tick。(注意32bit中需要用get_jiffies64()获取jiffies64)
当检测到有CPU关中断后,则往此CPU发送nmi中断,打印其回溯。
通过上述检测方式,抓到的典型现场如下:
一个core内的4个子线程全部挂死。其中一个死在中断入口,另外三个在用户态。
CPU 20:
errepc:0x806011a0
epc:0x773160
eirr:0x88
status:6000fff7 KX SX UX USER ERL EXL IE
CPU 21:
errepc:0x7719e4
epc:0x7585b4
eirr:0x0
status:6000fff5 KX SX UX USER ERL IE
CPU 22:
errepc:0xf64f6cc
epc:0x7585b4
eirr:0x0
status:6000fff5 KX SX UX USER ERL IE
CPU 23:
errepc:0x4cb474
epc:0x7585b4
eirr:0x0
status:6000fff5 KX SX UX USER ERL IE
CPU 20被nmi中断打断的地方,位于外部中断入口handle_int。
虽然跟故障无关,这里也顺带讲一下,xlp的handle_int是经过rollback_handle_int包装的。
这个是什么意思? xlp的idle是这么设计的:
LEAF(r4k_wait)
/* start of rollback region */
LONG_L t0, TI_FLAGS($28)
nop
andi t0, _TIF_NEED_RESCHED
bnez t0, 1f
nop
wait
/* end of rollback region (the region size must be power of two) */
.set pop
1:
jr ra
END(r4k_wait)
考虑这种情况,如果cpu在wait前被中断,返回现场后,将继续在wait处等待下一个时钟周期到来,才可能再次有调度点检查。为了增强实时性
,在handle_int前包装一个rollback的检测:
rollback_handle_int
MFC0 k0, CP0_EPC
PTR_LA k1, r4k_wait
ori k0, 0x1f /* 32 byte rollback region */
xori k0, 0x1f
bne k0, k1, 9f
MTC0 k0, CP0_EPC
9:
NESTED(handle_int, PT_SIZE, sp)
这段代码检查如果cpu是在idle里被中断,则恢复现场时直接将pc指向r4k_wait的入口,进行调度点检测,这样可以避免之前说的wait延时。
再回到故障信息,status显示在用户态。这就有点说不过去了。按道理,既然是在外部中断被nmi打断的,那么status自然应该是在内核态而不
是用户态。打印出USER的条件是status的KSU为10,至于KSU是硬件还是内核代码我们这里暂且不管,继续往下分析。根据内核的中断流程:
a) SAVE_ALL保存现场
b) 置status寄存器的CU0位表示可以访问协处理器0。
在出问题时的status现场,CU0还是0,说明可能在SAVE_ALL过程中或者之前就被nmi打断了。
于是做了一个实验,写了一个用户态死循环程序,不断的给此进程发nmi ipi中断。回溯发现,系统有一定几率会出现被在handle_int里被nmi
打断的情况,并且此时status显示KSU为10,即用户态。由此推测,可能出现这种情况:
程序在用户态死循环
来了一个中断,刚进入口,系统来不及更新status的KSU为内核态
被nmi打断,显示此时在用户态
当然,上述的分析只是推测,对故障定位本身没有影响,只是提出在此以备将来参考。
其实抓到的现场,除了在handle_int入口外,还有在tlb refill入口处的现场。
因此问题就变成了,为什么会在handle_int停住,或者是否发生了中断嵌套?
于是在handle_int以及tlb refill添加统计计数,看cpu此时到底在做什么。
4.4 在中断入口打点
用一个每cpu变量来记录各个cpu的handle_int计数。
uasm_i_dmfc0(p, K0 C0_CONTEXT);
uasm_i_dsrl(p, K0, K0, 23);
UASM_i_LA(p, K1, cpu_int_count);
uasm_i_daddu(p, K1, K0, K1);
uasm_i_ld(p, K0, 0, K1);
uasm_i_daddiu(p, K0, K0, 1);
uasm_i_sd(p, K0, 0, K1);
实际上xlp有一个scratch寄存器可以保存每个cpu的tlb miss次数。
当故障复现时,发现handle_int次数没有变化。说明不是外部中断嵌套。
说明一下xlp的寻址流程。
在开启pagewalker和extent tlb时,不考虑cache,当给定一个虚拟地址vaddr,cpu首先会同时检查所有的tlb,如果没有匹配的条目,则引发
一个tlb miss,pagewalker将对应页表项填入random的一个tlb条目。通常情况下,在linux设计框架里,这个过程是不会发生二次异常的。如
果填入的是一个无效的条目,再次访址引发tlb load/modify/store异常,走page fault执行写时复制,按需分配等。
根据故障现场时的epc,显示是在用户态,那么有怀疑是用户态正在执行指令,发生tlb miss进入了pagewalker流程,但在pagewalker重填过程
中流水线halt住,导致不响应中断。从我们实验的结果来看,当系统出问题时,我们给此cpu发送一个nmi,此cpu的handle_int计数就开始增加
。因此pagewalker的硬件设计值得怀疑,与boardcom交流后,fae承认工程部已发现pagewalker的问题,并正在调试。
由于pagewalker对我们来说是一个黑盒,因此下面我们关闭pagewalker进行测试。
4.5 关中断超过100ms
继续用之前的检测代码,在关闭pagewalker的情况下测试。大约拷机进行了3天左右,系统检测到有个CPU关中断超过100ms。往此CPU发nmi时,
发现挂死的位置不定,有可能在update_process_times,double_rq_lock,hrtimer_interrupts里的红黑树操作等。
这几个现场基本都和hrtimer_interrupts相关,而且表象是hrtimer_interrupt耗时,因此我们在hrtimer_interrupts,7号中断里,添加计时
代码。
下面是抓到的现场:
NMI triggered on CPU 6
errepc : 0xffffffffc0699cfc
epc : ffffffffc0699cfc rcu_check_callbacks+0x4/0x190
ra : ffffffffc066b320 update_process_times+0x68/0x140
[<ffffffffc0699cfc>] rcu_check_callbacks+0x4/0x190
[<ffffffffc066b320>] update_process_times+0x68/0x140
[<ffffffffc0684a84>] tick_sched_timer+0x6c/0x198
[<ffffffffc067bd1c>] __run_hrtimer.clone.33+0x7c/0x220
[<ffffffffc067c648>] hrtimer_interrupt+0xf8/0x248
[<ffffffffc06310f0>] c0_compare_interrupt+0x60/0xa8
[<ffffffffc069475c>] handle_IRQ_event+0x94/0x238
[<ffffffffc06949a8>] __do_IRQ+0xa8/0x230
[<ffffffffc0629c10>] do_IRQ+0x48/0x50
[<ffffffffc06197ac>] nlm_common_timer_interrupt+0x44/0xb8
[<ffffffffc0600f00>] ret_from_irq+0x0/0x4
[<ffffffffc060ea0c>] _spin_unlock_irq+0x24/0x58
[<ffffffffc066f1a8>] SyS_rt_sigtimedwait+0x190/0x280
[<ffffffffc06035a4>] handle_sys64+0x44/0x60
cpu[2]'s irq7 max time:8ms
cpu[2]'s hrtimer_func callback max time:3413ms
cpu[2]'s callback func:0xffffffffc067b8b8
cpu[7]'s irq7 max time:8ms
cpu[7]'s hrtimer_func callback max time:3413ms
cpu[7]'s callback func:0xffffffffc067b8b8
cpu[9]'s irq7 max time:17592186041002ms
cpu[9]'s hrtimer_func callback max time:0ms
cpu[9]'s callback func:0xffffffffc06771e0
cpu[10]'s irq7 max time:7ms
cpu[10]'s hrtimer_func callback max time:3413ms
cpu[10]'s callback func:0xffffffffc067b8b8
cpu[11]'s irq7 max time:3412ms
cpu[11]'s hrtimer_func callback max time:0ms
cpu[11]'s callback func:0xffffffffc06771e0
cpu[12]'s irq7 max time:6ms
cpu[12]'s hrtimer_func callback max time:17592186041002ms
cpu[12]'s callback func:0xffffffffc067b8b8
上面的irq7代表的是7号中断耗时,hrtimer_func callback代表的是单次hrtimer回调的执行耗时,callback func即此回调的函数地址。
打点记录耗时的函数用的是ktime_get,为什么会出现3413ms和17592186041002ms?我们在第4.7节分析。
在继续之前,先简单介绍一下高精度时钟的计时原理。
4.6 高精度时钟回顾
既然说到高精度时钟,就顺便整理一下高精度时钟从初始化到正常运行的流程,熟悉的同学可以跳过这一节。首先,在2.6.32内核里,高精度
时钟是放在硬中断里做的,这就带来一个问题,提高实时性的同时也导致中断时间过长,一把双刃剑。
先说明两个概念,clock event 和 clock source。前者用来触发下一次中断,不管是否配置CONFIG_HIGH_RES_TIMERS此框架都会在代码里存在
,一般是用cpu自带的counter和compare实现;后者是要求系统提供一个64位累加计数,具体的实现可能有多种,对于mips64而言,要么用
jiffies,要么用32位的counter,要么用64位的pic timer。
4.6.1 高精度模式的切换
系统刚初始化时,clock_device dev的 event_handler是一个空函数,后面被替换成tick_handle_periodic,接着主动触发一个时钟中断,在
tick_handle_periodic里临时完成一次时钟中断的工作,当运行到时钟软中断时,尝试进行真正的高精度模式切换。不管切换是否成功,都会
走原来的wheel定时器处理流程。作者注释说这种方法不好,每次都会在软中断里尝试切换到高精度时钟。要改进的话也有方案,例如
那么就可能有以下疑问:
1)满足什么条件时,系统会尝试切换到高精度模式?
2)为什么要在软中断里不停的尝试切换?
当clock source或者clock event变化(注册)时,将会给系统置位,并尝试在下一个时钟软中断里切换至高精度时钟,如果切换失败,则置位
等待下一次clock source或者clock event的变化。需要说明的是,clock event的变化是针对某个cpu的,clock source的变化则是针对所有
cpu。也就是说,如果某个cpu的clock event发生了变化,则只在此cpu的软中断里切换到高精度模式,反之clock source发生改变后,所有的
cpu都必须切换到高精度模式。如果确实有clock event或者clock source发生了变化(很有可能是模块注册了新的clock source),则进行下
一步检查,要求系统未使能no_hz模式,也就是说,不允许从no_hz模式切换到高精度模式。接下来是核心的判断,如果目前使用的clock
source支持高精度模式,则可以切换到高精度模式。
关于高精度模式的切换我们就说到这里,现在假设系统已运行在高精度模式下。
4.6.2 ktime_get和hrtimer_interrupt
有两点需要注意:
A)时间获取用的是ktime_get,这是高精度定时器超时比较的基准;
B)判断红黑树上高精度timer是否超时的基准时间,是第一次进入到hrtimer_interrupt时,取的当前时刻。
先看ktime_get。 ktime_get设计的目的是获取是系统从启动到现在的时间。大体实现原理是根据墙上时钟xtime,根据wall_to_mono转换成单
调递增时间。
ktime_get在mips64 xlp上的实现,靠的是每cpu的32位counter寄存器。实现的原理是,每个cpu上counter寄存器,与打点时间做差算出偏移,
然后根据cpu频率换算出具体的纳秒值。
static inline s64 timekeeping_get_ns(void)
{
cycle_t cycle_now, cycle_delta;
struct clocksource *clock;
/* read clocksource: */
clock = timekeeper.clock;
cycle_now = clock->read(clock);
/* calculate the delta since the last update_wall_time: */
cycle_delta = (cycle_now - clock->cycle_last) & clock->mask;
/* return delta convert to nanoseconds using ntp adjusted mult. */
return clocksource_cyc2ns(cycle_delta, timekeeper.mult,
timekeeper.shift);
}
核心代码即上面的红字部分。cycle_now是调用ktime_get的cpu的counter值,clock->cycle_last是cpu 0负责每个tick更新。通过这个差值,
可以算出每个cpu上的当前时刻。这里存在的问题是什么?(分析在4.7)
再分析hrtimer_interrupt函数的实现,这里参考的内核版本是2.6.32.41。hrtimer_interrupt在某些时候,会打印hrtimer: interrupt took
3456 ns的告警,我们来看看这是为什么。
在每次进入hrtimer_interrupt时,用ktime_get获取当前时间,摘下当前红黑树的最左节点,判断该节点的到期时间是否小于当前时刻,如果
是,则认为需要执行定时器回调,并取下一个最左节点进行超时比较;如果否,则退出遍历流程。要强调的是,刚进入hrtimer_interrupt时取
得的时间点,是判断所有timer是否超时的基准。假设有如下场景:
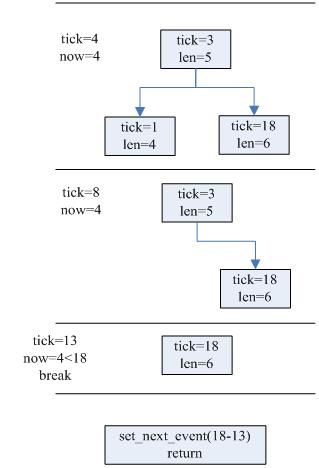
1)tick 4来了一个时钟中断,红黑树上最早到期的timer 1超时时间为tick 1,于是执行此timer的回调函数,执行长度为4个tick。
2)timer 1的回调结束后取下timer 2,发现超时时间为tick 3,小于tick 4,于是继续执行timer 2的回调,timer 2耗时5个tick。
3)timer 3的回调结束后取下timer 3,发现超时时间为tick 18,大于tick 4,因此退出循环。
4)取当前时间,得到tick 13,则设置下一次超时时间为距离当前(18-13)=5 tick后触发。示意图如下:
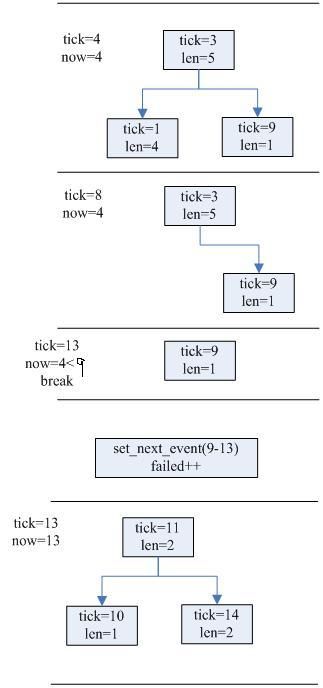
5)如果第3步的timer 3,超时时间为tick 9,则设置超时时间时会出错,如果连续出现这种状况3次,则打印告警。之所以会出现这种现象,
是因为timer过多,并且每个回调比较耗时。hrtimer_interrupt告警示意图如下:
4.7 超时数据分析与复现
有了4.6节的基础,再来看故障现场。
故障发生时,有两个现象值得注意:
A)系统曾经打印过hrtimer: interrupt took 3456 ns之类的告警;
B)4.5节的数据,关中断时间出现了3413ms和17592186041002ms。
A现象,说明应该出现过高精度时钟比较频繁,并且单个耗时的现象,观察跑流的单板现场,/proc/timer_list,控制面很多posix timer和
nanosleep timer。写了一个小程序,尽量模拟出高负载的高精度定时器同时处理的场景,即开启poxis timer,以及调用nanosleep。目的是让
其模拟出hrtimer_interrupt耗时过长的告警。最终的测试程序,启动了5000个线程,每个线程启动一个posix timer(RESTART性质,可以加重
hrtimer_interrupt单次处理的负担),以及nanosleep调用,大约3分钟左右就会复现一次故障。
关于B现象的这两个数据,一个是7号时钟中断的最大耗时,一个是高精度时钟的回调函数最大耗时。其中,17592186041002大的有点离谱,怀
疑是溢出。
尝试加一下他们的和:3413+17592186041002 = 0xFFFFFFFFFFF
感觉互相有关联,分析一个就够了。
我们先来分析3413的来历。
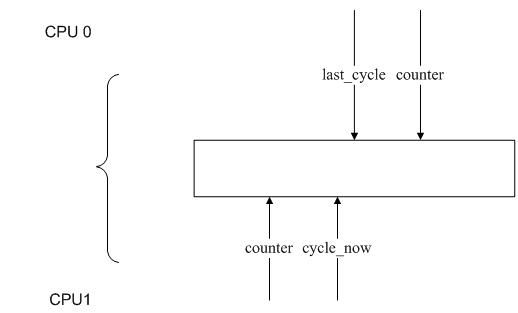
4.6.2的我们曾提到,ktime_get的实现最核心的一句为:
cycle_delta = (cycle_now - clock->cycle_last) & clock->mask;
由于cycle_now取得是本地cpu的32 位counter值, clock->cycle_last是CPU 0负责更新,因此就带来同步的风险。
考虑如下状况:
如果CPU 1的counter比CPU 0的counter稍滞后一点。CPU 0的tick来临,并更新cycle_last,此时在CPU 1上调用了ktime_get,由于CPU 1的
counter滞后于CPU 0,此时cycle_now正好小于cycle_last,相减得到一个接近2^32的数值,从而得到的ktime_get值极大。一旦发生这种跳变
,则引起的关中断超时的现象都不足为奇了,因为高精度定时器处理的基准是ktime_get,如果取的时间过大,可能导致处理较多的timer,引
起耗时。另外,counter寄存器的频率大约是1.3G,32bits能表示的最大数为4*10^9,
约为4*10^9/1.3*10^9 = 3.3s,与报错的数据也大体吻合。
下图说明了窗口造成ktime_get异常的原因:
5 总结
按照4.7分析的结果,在hrtimer_interrupt添加验证代码,进一步说明是因为counter的窗口问题导致ktime_get跳变,引起高精度时钟处理时
间过长,再加上之前说的高精度时钟都在硬中断下完成,导致这个关中断时间过长的问题。
最初想到有如下解决方案:
1) 采用counter 64位寄存器作为时钟源;
1.1) __asm__ __volatile__("DMFUR $16, %0" :"=r"(tmp));
2) 去掉高精度时钟,采用jiffies做时钟源;
2.1) 去除CONFIG_HIGH_RES_TIMERS(会自动去除CONFIG_TICK_ONESHOT);
2.2) 去除CONFIG_CSRC_R4K时钟源,这样会自动选中jiffies时钟源。
3) 去掉高精度时钟,采用pic timer做时钟源。
但实际上,除了3,剩下的两种方案都有缺陷。
如果采用counter64做寄存器,虽然避免了32位相减溢出,但由于counter64是每cpu寄存器,仍然存在窗口风险;
如果只是把高精度时钟关掉,以jiffies为时钟源的话,会出现系统时间比实际时间慢的情况。具体原因我们下面讨论。
首先用户态取时间gettimeofday,而内核函数是do_gettimeofday:
void getnstimeofday(struct timespec *ts)
{
*ts = xtime;
nsecs = timekeeping_get_ns();
timespec_add_ns(ts, nsecs);
}
最终的时间是xtime加上当前时刻距离上次中断的偏移。
xtime的更新速度以HZ为基准,若在两个tick之间调用了gettimeofday,则timekeeping_get_ns可以算出当前时刻距上次中断过了多长时间(精
确到时钟源,而不是时钟tick),再加到xtime里去,得到精确的时间。
如果说用getnstimeofday获取的时间比实际的时间慢,根据上面的代码,有两种可能:
a) xtime比实际的小
b) timekeeping_get_ns比实际的小
a.1) xtime在update_wall_time里更新,
offset = (clock->read(clock) - clock->cycle_last) & clock->mask;
while (offset >= timekeeper.cycle_interval) {
u64 nsecps = (u64)NSEC_PER_SEC << timekeeper.shift;
offset -= timekeeper.cycle_interval;
clock->cycle_last += timekeeper.cycle_interval;
timekeeper.xtime_nsec += timekeeper.xtime_interval;
if (timekeeper.xtime_nsec >= nsecps) {
timekeeper.xtime_nsec -= nsecps;
xtime.tv_sec++;
second_overflow();
}
}
xtime.tv_nsec = ((s64) timekeeper.xtime_nsec >> timekeeper.shift) + 1;
原理是根据当前时钟源的计数,减去上次时钟tick到来时的时钟源计数,根据这个差值,
换算成纳秒,然后依次进位累加到xtime的秒,以及剩下的加到纳秒单位上。
场景:
1)如果中断被关了一会,则带来的影响是,jiffies没有及时更新。
由于以jiffies为时钟源,linux不会对jiffies进行补偿,所以关中断对时钟系统来说是透明的。如果jiffies没有及时更新,此时又调用了
getnstimeofday,则xtime滞后了,得到的时间自然要少。
2)以jiffies为时钟源,就算没有关中断,但是每次时钟中断都有一定的耗时,由于tick_handle_periodic设置下一次时钟中断的时间,为相
对当前时刻加上tick_period
所以如果每次时钟中断耗时x, 则n次时钟中断后,将会落后标准时间n*x。
根源还是jiffies不准确,在GSU上应该也有这个问题(GSU是jiffies),但由于GSU会从主控来同步时间,所以这个问题没有表现出来。
所以,最终的解决方案是,暂时关闭高精度时钟,并采用pic timer做时钟源,具体的修改即关闭CONFIG_HIGH_RES_TIMERS,并注册一个rating
高于r4k时钟源的pic timer时钟源即可。