easyhadoop完全配置实战
版本:easyhadoop 1.2.1,操作系统:Centos 6.4;
经过上次的初始easyhadoop,本次终于配置好了一个集群,这个集群是有两个节点组成(master:jobtracker、namenode、secondarynamenode,node1:datanode、tasktracker)。
本篇就从开始到结束,来一个全面的介绍:
1.首先安装centos6.4的虚拟机,centos6.4的安装是有一个默认用户的,这里不使用那个账户,直接使用root即可。安装完成后,需要改变下面的内容(首先配置master,然后再配置node1):
1.1 /etc/sysconfig/network-scripts/ifconfig-eth0 ,这里配置GATEWAY是192.168.128.2,是因为Vmware的nat网络连接方式,其gateway是这个而已;
DEVICE=eth0 BOOTPROTO=static ONBOOT=yes IPADDR=192.168.128.160 NETMASK=255.255.255.0 GATEWAY=192.168.128.2 DNS1=192.168.128.21.2 /etcc/sysconfig/network 这里主要是配置机器名
NETWORKING=yes NETWORKING_IPV6=no HOSTNAME=master1.3 /etc/hosts ,配置ip映射(注意,这一步不是必须,因为在后面的配置easyhadoop的时候会复写这个文件)
192.168.128.160 master同样的在另外一台虚拟机里面做相应的配置,这里配置的ip是192.168.128.161,机器名是node1。
1.4 因为centos6.4虚拟机安装好默认是没有ssh-server的,所以这里使用下面的命令进行安装:
yum install ssh-server然后使用下面的命令设置sshd开机启动:
chkconfig sshd on
2.1下载easyhadoop安装包,解压后,上传到master机器中的目录(这里上传的是/easyhadoop安装目录)
2.2 进入easyhadoop目录,使用命令 :
chmod +x setup_centos_6.py增加setup_centos_6.py文件的执行权限,然后使用命令 ./setup_centos_6.py 进行安装;
2.3 安装完成后在浏览器中输入http://master,(如果在win7中没有配置master和ip的映射的话,是出不来结果的,那么就直接输入http:192.168.128.160)即可看到登录的界面,登录用户名和密码是:admin/123456,然后就可以进行配置了。
3. 配置hadoop:
3.1 点击导航栏Nodes--》Create Node 选项,按照下面两个图进行配置:
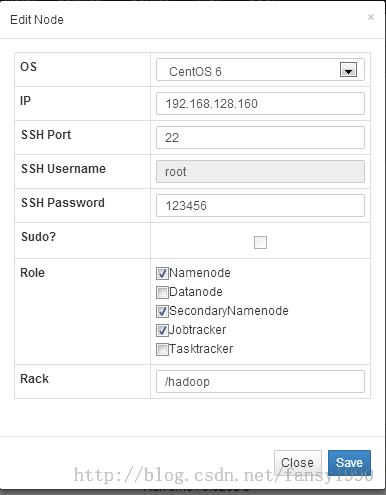
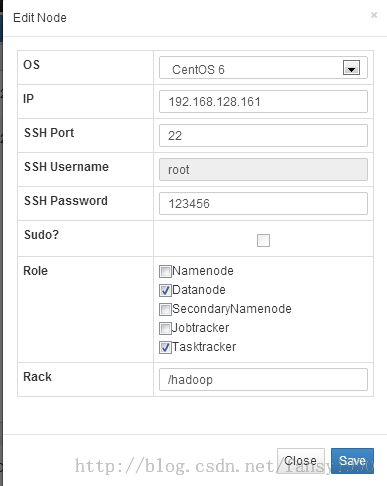
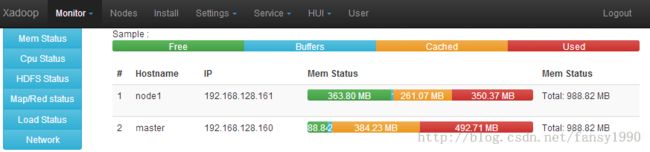
分别点击save,然后在Monitor--》Memory中可以看到下面的界面(做了一个配置后,最好在Monitor中查看有哪些东西做了改变):
然后在Nodes中选择Storage,选择相应的文件系统:
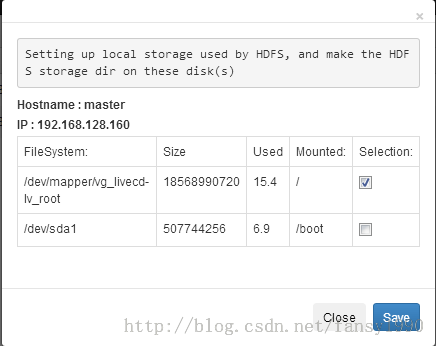
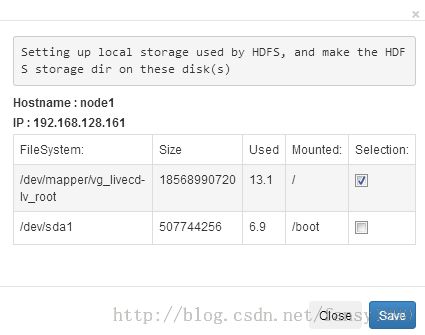
点击save保存。
3.2 install: 点击Install,依次选择节点中的install进行hadoop的安装,安装完成后会跳出来一个界面告诉你安装了哪些东西,最后会说hadoop installed。说明hadoop安装完成。额,别急,还有配置,个人感觉配置才是最麻烦的。
3.3 选择Settings--》Hadoop:
选择/etc/hosts选项,View Hosts,然后如果看到下面的界面:
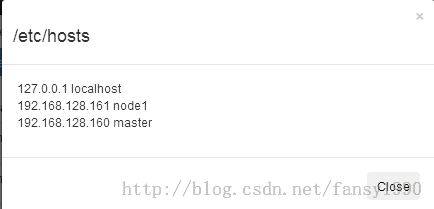
那么就说明这个配置是ok的,然后使用push Hosts选项进行/etc/hosts文件的分发,点击运行后,可以在master和node1机器中cat /etc/hosts查看这个文件是否和上图一样,如果一样就说明这个操作运行正常。
然后是RackAware选项,点击View RackAware,可以看到下图:

那么就说明这个是对的了,点击push RackAware即可。
最后是Global Settings选项了,首先按照图的操作把四个配置文件提交上来:
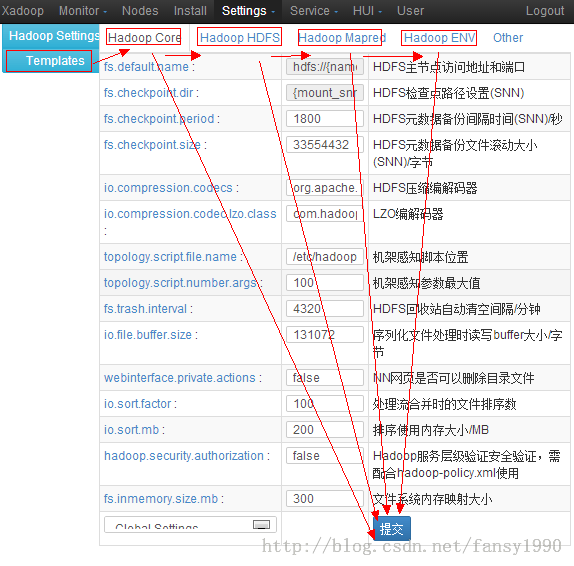
提交完成后,可以在HadoopSetings中看到下面的界面:
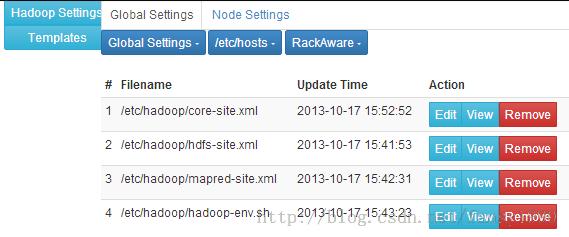
然后分别点击Edit,进行文件的配置,配置分别如下:
/core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<description>HDFS主节点访问地址和端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/dfs/snn</value>
<description>HDFS检查点路径设置(SNN)</description>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>1800</value>
<description>HDFS元数据备份间隔时间(SNN)/秒</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>33554432</value>
<description>HDFS元数据备份文件滚动大小(SNN)/字节</description>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
<description>HDFS压缩编解码器</description>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
<description>LZO编解码器</description>
</property>
<property>
<name>topology.script.file.name</name>
<value>/etc/hadoop/RackAware.py</value>
<description>机架感知脚本位置</description>
</property>
<property>
<name>topology.script.number.args</name>
<value>100</value>
<description>机架感知参数最大值</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
<description>HDFS回收站自动清空间隔/分钟</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>序列化文件处理时读写buffer大小/字节</description>
</property>
<property>
<name>webinterface.private.actions</name>
<value>false</value>
<description>NN网页是否可以删除目录文件</description>
</property>
<property>
<name>io.sort.factor</name>
<value>100</value>
<description>处理流合并时的文件排序数</description>
</property>
<property>
<name>io.sort.mb</name>
<value>200</value>
<description>排序使用内存大小/MB</description>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>false</value>
<description>Hadoop服务层级验证安全验证,需配合hadoop-policy.xml使用</description>
</property>
<property>
<name>fs.inmemory.size.mb</name>
<value>300</value>
<description>文件系统内存映射大小</description>
</property>
</configuration>
/hdfs-site.xml:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/dfs/name</value>
<description>Namenode元数据存储位置</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/dfs/data</value>
<description>HDFS数据存储路径</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>文件块复制份数</description>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>1073741824</value>
<description>每硬盘保留空间/字节</description>
</property>
<property>
<name>dfs.block.size</name>
<value>67108864</value>
<description>文件块大小/字节</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>是否启用Hadoop文件系统 true/false</description>
</property>
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>10485760</value>
<description>Balancer使用最大带宽/字节</description>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
<description>是否允许对文件APPEND</description>
</property>
<property>
<name>dfs.datanode.failed.volumes.tolerated</name>
<value>0</value>
<description>硬盘故障数量异常阀值</description>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>8192</value>
<description>Datanode打开文件句柄数</description>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>20</value>
<description>Datanode处理RPC线程数</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>60</value>
<description>Namenode处理RPC线程数</description>
</property>
<property>
<name>dfs.safemode.extension</name>
<value>5</value>
<description>Namenode退出Safemode的延迟时间</description>
</property>
</configuration>
/mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
<description>Jobtracker地址</description>
</property>
<property>
<name>mapred.local.dir</name>
<value>/mapred/local</value>
<description>MR本地使用路径</description>
</property>
<property>
<name>mapred.system.dir</name>
<value>/mapred/system</value>
<description>MR系统使用路径</description>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>2</value>
<description>服务器最大map数</description>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>1</value>
<description>服务器最大reduce数</description>
</property>
<property>
<name>mapred.map.child.java.opts</name>
<value>-Xmx256M</value>
<description>每map线程使用内存大小</description>
</property>
<property>
<name>mapred.reduce.child.java.opts</name>
<value>-Xmx256M</value>
<description>每reduce线程使用内存大小</description>
</property>
<property>
<name>mapred.reduce.parallel.copies</name>
<value>6</value>
<description>reduce阶段并行复制线程数</description>
</property>
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
<description>是否对map进行压缩输出</description>
</property>
<property>
<name>mapred.map.output.compression.code</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>map压缩输出使用的编码器</description>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024M -Xms1024M</value>
<description>map/red虚拟机子进程设置</description>
</property>
<property>
<name>mapred.jobtracker.taskScheduler</name>
<value>org.apache.hadoop.mapred.JobQueueTaskScheduler</value>
<description>hadoop使用队列</description>
</property>
<property>
<name>mapred.output.compress</name>
<value>false</value>
<description>是否开启任务结果压缩输出</description>
</property>
<property>
<name>mapred.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
<description>任务结果压缩输出编解码器</description>
</property>
<property>
<name>map.sort.class</name>
<value>org.apache.hadoop.util.QuickSort</value>
<description>map排序算法</description>
</property>
<property>
<name>mapred.tasktracker.expiry.interval</name>
<value>60000</value>
<description>TaskTracker存活检测时间,超出该时间则认为tasktracker死亡/毫秒</description>
</property>
<property>
<name>mapred.local.dir.minspacestart</name>
<value>1073741824</value>
<description>硬盘空间小于该大小则不在本地做计算/字节</description>
</property>
<property>
<name>mapred.local.dir.minspacekill</name>
<value>1073741824</value>
<description>硬盘空间小于该大小则不再申请新任务/字节</description>
</property>
<property>
<name>mapred.reduce.slowstart.completed.maps</name>
<value>0.05</value>
<description>Reduce启动所需map进度。</description>
</property>
<property>
<name>mapred.jobtracker.restart.recover</name>
<value>true</value>
<description>Jobtracker重启后恢复任务</description>
</property>
<property>
<name>mapred.job.reuse.jvm.num.tasks</name>
<value>-1</value>
<description>Map/Reduce进程使用JVM重用</description>
</property>
<property>
<name>mapred.local.dir.minspacekill</name>
<value>1073741824</value>
<description>磁盘小于该空间则不申请新任务</description>
</property>
</configuration>
/hadoop-end.sh:
# Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # The java implementation to use. export JAVA_HOME=/usr/java/default export HADOOP_C # The maximum amount of heap to use, in MB. Default is 1000. #export HADOOP_HEAPSIZE= #export HADOOP_NAMENODE_INIT_HEAPSIZE="" # Extra Java runtime options. Empty by default. export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true $HADOOP_CLIENT_OPTS" # Command specific options appended to HADOOP_OPTS when specified export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,DRFAS -Dhdfs.audit.logger=INFO,DRFAAUDIT $HADOOP_NAMENODE_OPTS" HADOOP_JOBTRACKER_OPTS="-Dhadoop.security.logger=INFO,DRFAS -Dmapred.audit.logger=INFO,MRAUDIT -Dhadoop.mapreduce.jobsummary.logger=INFO,JSA $HADOOP_JOBTRACKER_OPTS" HADOOP_TASKTRACKER_OPTS="-Dhadoop.security.logger=ERROR,console -Dmapred.audit.logger=ERROR,console $HADOOP_TASKTRACKER_OPTS" HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,DRFAS $HADOOP_DATANODE_OPTS" export HADOOP_SEC # The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx128m $HADOOP_CLIENT_OPTS" #HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS" # On secure datanodes, user to run the datanode as after dropping privileges export HADOOP_SECURE_DN_USER= # Where log files are stored. $HADOOP_HOME/logs by default. export HADOOP_LOG_DIR=/var/log/hadoop/$USER # Where log files are stored in the secure data environment. export HADOOP_SECURE_DN_LOG_DIR=/var/log/hadoop/ # The directory where pid files are stored. /tmp by default. export HADOOP_PID_DIR=/var/run/hadoop export HADOOP_SECURE_DN_PID_DIR=/var/run/hadoop # A string representing this instance of hadoop. $USER by default. export HADOOP_IDENT_STRING=$USER其实上面四个文件的配置和模板是差不多的,只是其中有一点点改变而已。其中hadoop-env.sh文件中的JAVA_HOME=/usr/java/default是进行easyhadoop安装的时候安装的java的默认路径。上面四个文件配置完成后,点击Push Global Settings即可推送这四个文件到集群的各个机器,可以在集群中的/etc/hadoop/中查看相应 的文件,看是否和配置的一样,如果不一样,那么就说明有错误。
3.4 格式化namenode,在master中运行:
sudo -u hdfs hadoop namenode -format进行namenode的格式化;
3.5 启动集群:
点击导航栏的Service --》Hadoop,依次点击Namenode-----》datanode1-----》datanode2-----》secondarynamenode-----》jobtracker------》tasktracker1------》tasktracker2中的Start-*选项,进行进程的启动。启动完成后,可以在Monitor中进行HDFS和Mapreduce的查看:
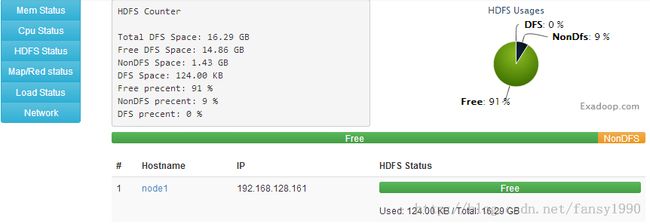
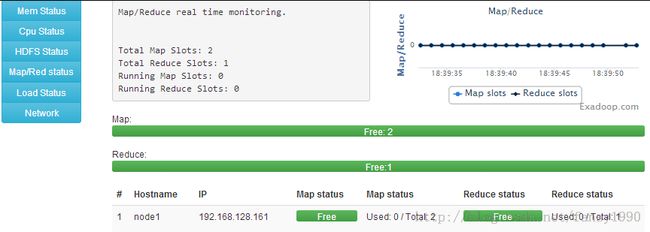
最后,为了验证集群的配置是正确的,运行一个程序,在主节点运行(上传文件到HDFS中):
hadoop fs -copyFromLocal /etc/hadoop/hadoop-env.sh input/test1接着运行wordcount程序:
hadoop jar /usr/share/hadoop/hadoop-examples-1.2.1.jar wordcount input/ output下图是在上面程序运行时,Monitor中的截图:
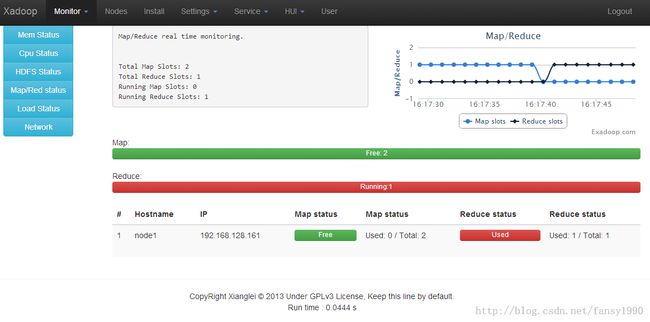
这样全部配置就全部ok了。
说明:
- java默认目录/usr/java/default
- hadoop配置文件默认目录:/etc/hadoop/
- hadoop jar文件默认目录/usr/share/hadoop
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990