Design Pattern
很多程序员用面向对象语言写了多年的代码, 仍然不知道设计模式为何物, 这不奇怪, 设计模式并不是非有不可,可是它能让代码变的更美好。
程序员大可闷头堆代码, 复制粘贴, 然后不断的感慨代码难以维护, 难以复用, 难以扩展, 而继续不思进取。
当然也可以选折不断去追求更美好, 更合理的代码, 把自己从bug调试, 需求变动等噩梦中拯救出来, 进而真正体会到编码的乐趣。
你如果选折后者那么设计模式对于你而言, 是真正必不可少的, 只有当你真正认真考虑过代码的复用性,扩展性,和合理性时, 你才能真正体会到设计模式的好处。
想知道一样东西的价值, 最好的方法就是想想, 如果没有它, 你会怎么样.
对于学习模式, 也是一样, 不要拘泥于其中, 要多想想为什么需要它. 如果没有这种模式, 一样是很好的code, 那就说明这个模式在这种情况下没有价值, 那就不要去用他.
如果使用了一种模式, 能使你的code从可扩展性, 可维护性和可复用性上有些提高, 那么这个就是他的价值所在.
下面是面向对象设计的6大原则,是学习编程和模式的基础
单一职责原则 (SRP)
一个类,只有一个引起它变化的原因。应该只有一个职责。如果一个类有一个以上的职责,这些职责就耦合在了一起。这会导致脆弱的设计。当一个职责发生变化时,可能会影响其它的职责. 这严重影响了代码的可维护性, 可复用性.
开闭原则(OCP)
开闭原则是面向对象设计中“可复用设计”的基石,是面向对象设计中最重要的原则之一,其它很多的设计原则都是实现开闭原则的一种手段。1988 年,Bertrand Meyer在他的著作《Object Oriented Software Construction》中提出了开闭原则,它的原文是这样:“Software entities should be open for extension,but closed for modification”。翻译过来就是:“软件实体应当对扩展开放,对修改关闭”。一句好说不好做的话......
依赖倒置原则(DIP)
依赖倒置原则(Dependence Inversion Principle)就是要依赖于抽象,不要依赖于具体。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。
A.高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。
B.抽象不应该依赖于具体,具体应该依赖于抽象。
依赖倒置原则的本质就是通过抽象(接口或者抽象类)使各个类或模型的实现彼此独立,不互相影响,实现模块间的松耦合。
接口隔离原则(ISP)
接口是我们设计时对外提供的契约,通过分散定义多个接口,可以预防未来变更的扩散,提高系统的灵活性和可维护性。
要求在接口中尽量少公布public方法,而不是建立一个庞大的臃肿的接口,容纳所有的客户端访问。
接口是对外的承诺,承诺地越少对系统开发越有利,变更的风险也就越少,同时也有利于降低成本。
迪米特法则(LoD,LKP)
迪米特法则(Law of Demeter,LoD)也称为最少知识原则(Least Knowledge Principle,LKP), 迪米特法则的核心观念就是类间解耦,弱耦合. 一个类应该对自己需要耦合或调用的类知道得最少,你(被耦合或调用的类)的内部是如何复杂都和我没关系,那是你的事情,我就知道你提供的public方法,我就调用这么多,其他的一概不关心。
设计模式的门面模式(Facade)和中介模式(Mediator),都是迪米特法则应用的例子。
里氏替换原则 (LSP)
Liskov 于1987年提出了一个关于继承的原则“Inheritance should ensure that any property proved about supertype objects also holds for subtype objects.”——“继承必须确保超类所拥有的性质在子类中仍然成立。”也就是说,当一个子类的实例应该能够替换任何其超类的实例时,它们之间才具有 is-A关系。 该原则称为Liskov Substitution Principle——里氏替换原则。
继承是个耦合性很强的关系, 所以不能随便轻率的使用继承关系, 如果子类并不能完全替换父类的话, 应该使用聚集, 组合来代替继承.
举个例子, 鸟-->企鹅, 可是企鹅不会飞, 无法实现fly函数, 这样的继承关系就违反了里氏替换原则.
工厂模式概述
工厂模式, 包括简单工厂, 工厂方法, 抽象工厂, 为什么叫工厂, 因为工厂生产出来的产品是规格一致的(即接口一致的, 具有统一基类的), 否则叫作坊.
规格一致的好处是代码复用, 基于多态和里氏替换原则, 所有的代码都可以基于基类去编写. 当在不同的子类间切换时, 不需要更改任何代码, 因为根据里氏替换原则, 子类是可以完全替换父类的.
简单工厂模式
简单工厂模式是属于创建型模式,又叫做静态工厂方法(StaticFactory Method)模式,但不属于23种GOF设计模式之一。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。
场景, 在客户代码中, 需要根据不同的情况创建不同的对象.
那么直接的做法, 用大量的if... else...来判断, 条件不同创建不同的对象.
这样好不好? 明显不好, 如果需要选择的对象很多, 那在客户代码中需要加上大段的条件判断, 严重影响可读性, 使代码重点不突出. 而且也严重影响维护和扩展性, 每次对象增加都要来修改这段代码.
怎么办? 最简单的办法就是, 把这段代码挪到其他地方去, 这样客户端代码就清晰了, 可读性就强了, 这个就是简单工厂模式.
该模式其实只是对象创建代码做了简单的封装, 把对象创建的职责(大段的if...else...)放到一个简单工厂中, 而在客户代码只需提供简单参数, 就可以得到相应的对象, 而不需要关心对象创建过程.
这个模式的好处就是做到职责单一原则, 把复杂的对象创建代码放到专门的工厂类中去, 这样客户代码的可读性, 可维护性都大大增强.
缺点就是, 当需创建的对象很多, 逻辑复杂时, 工厂类本身的可读性和可维护性仍然比较差.
public class SimpleFactory{
public static Mobile createMobile(String mobileName){
if(mobileName.equals("NOKIA")){
new Nokia();
}else if(mobileName.equals("MOTOROLA")){
new Motorola();
}else{
throw new Exception("还不支持该种类型的手机生产!");
} } }
客户代码,
object = SimpleFactory.createMobile('NOKIA')
客户这样就可以简单的获取对象, 而不关心具体的对象场景过程, 而且通过简单的修改参数就可以得到不同的对象.
工厂方法模式
简单工厂模式其实是把问题转移了, 并没有真正去解决. 把创建对象的逻辑从客户代码移到工厂类后, 工厂类仍然违反开闭原则, 每次增加新的对象都要修改代码, 而且当需要创建的对象很多时, 条件判断会很长很混乱, 严重影响可读性和维护性. 那怎么样才能真正解决这个问题? 思路是把一个工厂类化为许许多多的工厂类, 既然当一长串条件创建语句都放在一个工厂类中时显的混乱,难维护. 那么就把他打散, 将各个对象的创建过程分别抽象为多个具体的工厂类(如下图). 这样就符合开闭原则了,当增加对象时, 我们只需要加上一个具体的工厂类即可, 不需要修改本来的工厂类的代码.
客户代码就由,
object = SimpleFactory.createMobile('NOKIA' )
换成,
Ifactory factory= new NokiaFactory ()
object = factory.createMobile()
可见对于客户代码而言, 简单工厂和工厂实际没有区别的. 当用户需要切换对象时, 只需要修改一处代码就可以实现, 其他地方都可以利用多态来避免代码的修改.
工厂方法的好处就是让工厂类具有可扩展性, 符合开闭原则.
坏处是, 当要创建的对象很多时, 需要创建大量的具体工厂类.

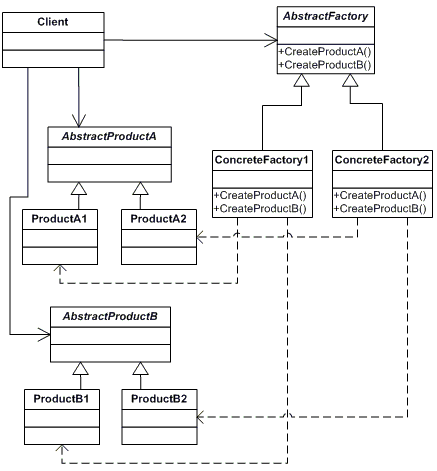
抽象工厂模式
抽象工厂模式就是工厂方法模式的扩展. 建立一个工厂时, 不仅仅可以创建一个对象, 而是可以创建一系列的对象.
工厂方法的例子,
Ifactory factory= new NokiaFactory ()
object = factory.createMobile()
现在Nokia不光有Mobile, 也生产TV, 那就要提供
factory.createTV()
这就是抽象工厂, 如下图, 和工厂方法唯一的区别就是工厂中可以同时生产多个产品.
抽象工厂模式的缺点很明显, 当你要增加一个产品时, 相当麻烦. 其他不谈, 要在抽象工厂类和所有派生类里面增加create接口就相当的烦人.
简单工厂模式改进
前面介绍了简单工厂-->工厂方法-->抽象工厂模式这样的改进思路, 但是好像这样是越改越复杂, 虽然增加了可扩展性, 但是付出的代价似乎大了点, 有没有捷径?|
通常而言, 捷径是没有的, 但是这里的情况是有时会有, 因为对于某些语言支持....(不知怎么描述这种特性, 语句动态执行?), 如.Net里面的反射, 或python里面的eval
有了这样的特性, 我们就有一种新的去除大量条件语句的思路,
如下面的例子, .Net我不熟, 就以Python为例子,
class NokiaMobile: def __init__(self): self.name = 'nokia5500' class MotoMobile: def __init__(self): self.name = 'moto1000' class SimpleFactory: def __init__(self): self.name = 'Mot' def createMobile(self): if self.name =='Nokia': return NokiaMobile() if self.name =='Moto': return MotoMobile() else: print 'No this name' return None def createMobileEval(self): class_name = self.name + 'Mobile()' try: object = eval(class_name) except Exception, e: print 'No this class'+ str(e) object = None return object
很清楚可以看到, 在createMobile函数中, 我们需要使用大量的条件语句, 随着品牌的变多, 这个函数会越来越长, 越来越复杂.
而对于createMobileEval, 无论你增加多少品牌, 现在的代码都已经足够, 有了这种语言特性, 非常简单的就解决了问题.
如果你需要增加产品, 只需要在加个函数就可以, 如createTVEval
为了自由切换品牌或品牌系列而不用改变任何客户代码, 我们还可以把切换开关(需要的品牌名)放到全局变量里, 或配置文件里. 这样就perfect了......
有了这种方法根本就不需要使用工厂方法和抽象工厂, 模式是死的, 技术是活的......
策略模式
策略模式定义了一系列的算法,并将每一个算法封装起来,而且使它们还可以相互替换。策略模式让算法独立于使用它的客户而独立变化。
场景, 对于输入, 在不同的情况下有不同的处理逻辑, 即有不用的算法
那么c的做法, 把各个算法封装成函数,仍然用大量的if... else...来判断, 条件不同使用不同的算法函数来处理.
面向对象的做法, 上面提到了工厂模式, 建个抽象算法基类, 然后把每个算法抽象为具体的算法类. 然后用户代码根据不同的情况, 利用工厂类创建不同的算法类来处理, 如下,
Strategy s = StrategyFactory.CreateStrategy(type)
s.AlgorithmInterface()
这样做其实没有问题, 我觉得挺好, 但如果进一步提高封装性, 不想让用户知道有具体的Strategy, StrategyFactory存在, 那就要用到策略模式
使用Context类来替换Factory类, 好处是Context类不直接把Strategy对象返回给用户, 而仅仅提供统一的算法接口给用户, 做法如下,
Context c = new Context(type) //Context的构造函数中会根据type创建相应的Strategy 类
c.ContextInterface() //ContextInterface封装并调用s.AlgorithmInterface()
其实就是增加了一层封装, 这样用户代码只需要知道Context类, 而不需要关心其他细节. 这应该是迪米特法则的应用, 不该知道的就别知道, 解耦合.
个人认为策略模式的意义并不大, 只是提高些封装性.
装饰模式
动态 地给一个对象 添加一些额外的职责 。就增加功能来说,Decorator模式相比生成子类更为灵活。
对于对象功能的扩展, 面向对象一般通过继承来解决, 但这种方式缺乏灵活性, 而且随意定义子类容易导致类层次结构过快膨胀.
场景, 当类的核心职责和主要行为没有发生变化, 仅仅需要动态对类对象添加一些装饰性的功能, 比如给人穿衣服......
如下图所示, 只是为图画换换边框, 这种改动只需要使用下面介绍的装饰模式.

装饰模式实现, 如下代码,
class Component //核心类
{
void Operation();
}
class Decorator: Component //装饰类, 必须继承自核心类, 第一是要保持接口一致, 更重要的是, 这样可以嵌套装饰
{
protected Component com; //核心类对象(引用, 需多态)
void setComponent (Component com) {this.com = com}
void Operation()
{
com.Operation() //这儿除了调用核心类的功能, 可以任意添加装饰性功能
}
}
客户代码使用,
com = new Component()
dec = new Decorator()
dec.setComponent(com)
dec.Operation() //这个Operation就是经过装饰的
装饰模式如下图, 我们可以创建一个抽象Decorator类, 然后根据需要创建许多的ConcreteDecroator类. 而Decorator类可以装饰任意Component类.
而且Decorator类只是对核心类对象进行动态装饰, 不会影响到核心类本身, 所以可以任意装饰, 加成员变量, 调用其他函数, 如ConcreteDecroatorA, ConcreteDecroatorB.
且Decorator类本身也是Component类, 所以可以嵌套装饰, 非常的强大,
com = new Component()
dec_a = new ConcreteDecroatorA()
dec_b = new ConcreteDecroatorB()
dec_c = new ConcreteDecroatorC()
dec_a.setComponent(com)
dec_b.setComponent(dec_a)
dec_c.setComponent(dec_b)
dec_c.Operation() //这个Operation就是经过多次装饰的
装饰模式的好处,
首先, 有效的将类的核心职能和装饰功能区分开了, 动态装饰完全不会影响核心类 便于维护, 可复用性强.
其次, 有效的解决了子类的快速膨胀的问题, 如果单纯用继承来解决问题, 不但对于装饰A,B,......各需要子类, 而且对于各种装饰的组合也需要创建子类. 当装饰种类很多时, 可想而知那会创建非常多的子类. 而使用装饰模式, 只需要对每个装饰生成子类, 而装饰的组合和搭配只需要嵌套使用装饰模式就可以达成.
这个模式还是很实用, 很强大的, 可以用于很多场景......
代理模式
代理(Proxy)模式给某一个对象提供一个代理,并由代理对象控制对原对象的引用。
场景, 在软件系统中,有些对象有时候由于跨越网络或者其他的障碍,而不能够或者不想直接访问另一个对象.
这个模式很容易理解, 而且实际应用很多, 如
远程(Remote)代理, 典型的例子, webservice远程调用
保护(Protect or Access)代理, 控制访问权限
虚拟(Virtual)代理, 当创建消耗资源很大的对象时使用, 如打开很多图片的Html, 会先显示文字, 而图片会下载结束后才显示, 那些未打开的图片框就是用虚拟代理来替代真实图片.
智能引用(Smart Reference)代理:代理需要处理一些额外的事, 如引用计数, 计数为0时释放引用等.
可见这个模式虽然简单, 但是还是很有用的, 代理提供了一层封装, 使客户在访问到真正对象前, 可以做预先的处理, 灵活性很大.
如下图, Subject类定义了RealSubject和Proxy公共的接口, 这样在任何使用RealSubject的地方都可以使用Proxy
Class RealSubject : Subject
{
void Request() { print("Real request");}
}
Class Proxy : Subject
{
RealSubject realSub; //真实对象
void request() { realSub.Request(); } //可以在访问真实对象时, 添加任何逻辑
}
用户使用直接访问代理
Proxy p = new Proxy()
p.Request()
原型模式
原型模式(Prototype Pattern), 用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象.
原型模式其实就是从一个对象再创建另外一个可定制的对象, 而且不需知道任何对象创建的细节, 因为就是完全拷贝原型对象, 所以原型对象是怎么创建的不用管.
Class ConcretePrototype : Prototype
{
Prototype Clone() //提供Clone函数
{
return this.MemberwiseClone() //memberwise是属于浅拷贝, 此处clone的逻辑按需更改, 这儿只是个例子
}
}
用户使用时,
ConcretePrototype p1 = new ConcretePrototype ()
ConcretePrototype p2 = p1.Clone() //不用重新构建ConcretePrototype对象, 通过clone就可以得到新的对象
原型模式的好处,
当对象构造函数执行时间较长时, 只用调用构造函数一次, 通过Clone就可以创建多个对象, 大大提高效率,
可以隐藏对象创建细节,
可以动态获得对象运行时状态.
模板方法模式
模板方法(Template Method)模式定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
这是一个很简单, 却被非常广泛使用的模式, 只要使用过继承和多态, 或多或少都会使用到模板方法, 只是你不一定意识到.
场景, 需要设计一系列的算法或功能, 他们在主体框架上是相同的, 但是算法细节却不同
在基类的TemplateMethod中定义该系列算法的通用主体框架, 在涉及到易变化的细节时, 把细节抽象成虚函数并调用, 如PrimitiveOperation.
这样在基类中, 这些细节都是没有定义的, 你必须在子类中来override这些虚函数来改变算法细节.
这就是上面定义说的, 在基类中定义算法骨架, 而将一些易变的步骤延迟到子类中override.
模板方法模式的好处,
通过把通用的不变的行为放在基类, 从而去除子类中的重复代码, 以利于代码复用.
其实这个是个普遍的想法, 你不知道这个模式, 在写代码的时候也会这么写的.
门面模式
门面模式( facade )又称外观模式, 为子系统中的一组接口提供一个一致的界面, Facade 模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
这个模式很简单, 当子系统接口比较复杂时, 如果让客户直接使用子系统接口, 有如下问题,
系统难于使用, 客户需要先熟悉复杂的子系统接口
耦合度过高, 当子系统改变时, 会影响到客户类
这样明显违反了迪米特法则和依赖倒转法则, 所以我们的做法就是提供一个相对简单的高层抽象接口来屏蔽底层子系统的细节,从而解决了上面两个问题.
这个模式很简单, 也很常用, 无论你是否知道这个模式

建造者模式
建造者模式(Builder Pattern), 将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。
场景, 需要通过若干步骤创建一组复杂对象, 并且对于不同类型对象, 各个步骤中的细节会不相同.
例子, 肯德基做汉堡, 比较复杂, 有一个固定流程, 比如准备原料, 放调味, 加热, 包装. 但是不同的汉堡, 各个制作步骤的细节是不一样的. 比如调味换一下就有不同风味的汉堡.
普通的做法, 对每一种复杂对象单独写一个创建函数, 这样也可以, 但是有些问题
制作方法的主要步骤是一致的, 只是各个步骤细节不同, 所以会有大量的代码重复
因为创建步骤比较复杂, 写某个创建函数时会由于疏忽, 遗漏步骤或写错步骤顺序
对于这种问题, 明显是模板方法模式的思路...
把通用的流程步骤抽象到基类中, 在派生类中重写具体步骤函数
如果基于模板方法模式, 就直接把Construct()放在Builder类, 不需要多出一个Director类
个人觉得这样也挺好, 如果Construct()逻辑是固定的话
建造者模式抽象出Director, 会更加灵活, 如果可以通过Builder中不同的步骤组合产生出不同的产品, 即如果construct的逻辑可以变化
个人觉得建造者模式就是模板方法模式的一种简单的变化, 多出的那个Director, 个人觉得可有可无......也许是我不能理会建造者的精髓.......
Class Product
{
List parts = new List();
void add(part) {parts.add(part)}
}
Abstract Class Builder
{
void BuildPartA();
void BuildPartB();
}
Class ConcreteBuilder : Builder
{
Produce p = new Product();
void BuildPartA() {p.add('a')}
void BuildPartB() {p.add('b')}
}
Class Director
{
void Constract (Builder builder)
{
builder.BuildPartA();
builder.BuildPartB();
}
}
客户代码, 不需要知道具体的建造过程, 只要将相应的builder传给director就可以得到相应的对象.
Director d = new Director ()
Builder b = new ConcreteBuilder ()
d.Construct(b)
观察者模式
观察者模式(Observer), 定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象. 这个主题对象在状态发生变化时,会通知所有观察者对象,使它们能够自动更新自己。