Graph Databases—Chapter 5 Graph Databases 阅读笔记
转载请注明:http://blog.csdn.net/ict2014/article/details/17530215
本章内容概括:
首先讲述Graph Database的含义,论述了两个图模型的优缺点。其次,讲解了Neo4j的框架结构,接下来详细讲解了各个模块的设计。讲解的顺序是自下而上,从结点的设计、关系的设计到缓存结构,进而到上层接口。最后讲解了处理图数据库的框架结构Pregel。
---------------------------------------------------------------------------------------------------------------------------------------------------------
下面将对本章重点知识进行总结:
1、A graph database is a storage engine which supports a graph data model backed by native graph persistence, with access and query methods for the graph primitives to make querying the stored data pleasant and performant.
图数据库的具体定义的说明。 是一个存储引擎,支持图数据模型,并且能够提供访问、查询等方法。
2、Hypergraphs are a generalized graph model where a relationship (called a hyper-edge) can connect any number of nodes.
一种图模型结构,超图。一种关系可以连接很多结点。具体的可参照如下图1所示:
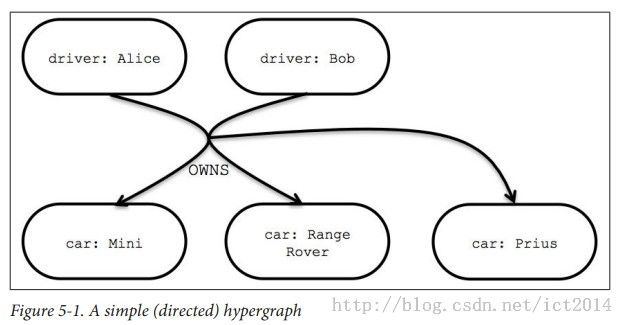
图1:超图的示例示意图
3、However triple stores are not graph databases, though they ostensibly deal in data which — once processed — tends to be logically linked.
triple store是一种图模型,是一种三元关系组。一般是主体-谓元-客体。看似像一种图关系在里面,其实并不是图数据库。
4、Neo4j的框架结构图
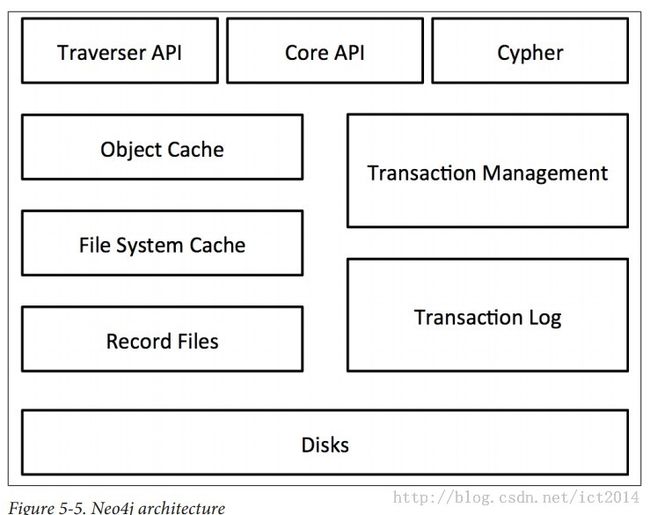
图2:Neo4j的框架结构图
===============我们将从下到上进行讲解这个架构===========================
5、结点的数据结构
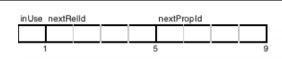
the node store is a fixed-size record store where each record is 9 bytes in length. Fixed record sizes enable fast
lookups for nodes within the store file. Inside a node record, the first byte is the in-use flag which tells the database whether the record is currently used or can be reclaimed to store new records (with Neo4j’s .id files being used to keep track of unused records). The next four bytes are the of the first relationship connected to the node. The last four nodes bytes are the id of the first property for the node.
结点数据结构,是固定长度的,总共9个字节。固定字长可以支持快速查询。第一个字段是“in Use”,代表数据库目前是否正在使用这个结点或者可以重新存储新纪录。接下来4个字节存储的是一个关系(关系是一个双向链表,因此存储第一个即可),后面4个字节存储的是这个结点的第一个性质的id。
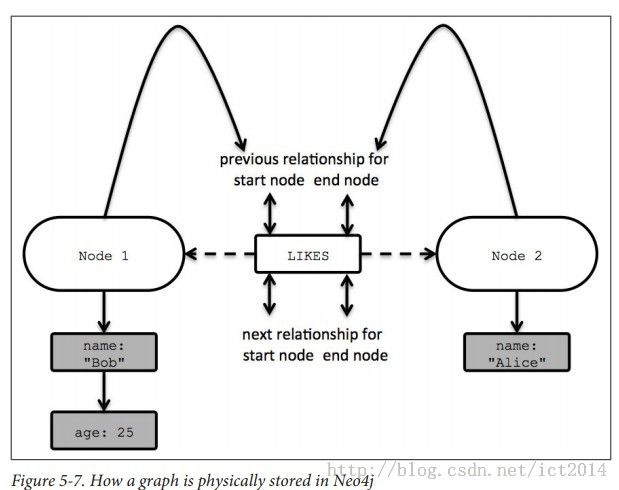
6、关系的数据结构

关系是固定的33个字节存储,1-5是第一个节点,5-9是第二个结点,9-13是关系的类型。后面是双向链表的存储。
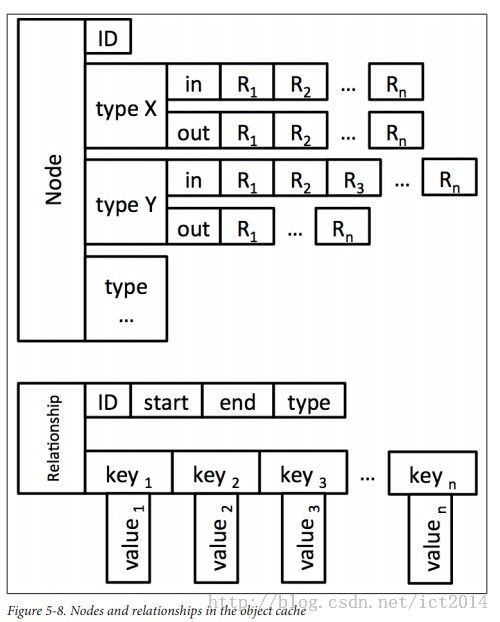
7、结点和关系的具体存储的图:
8、In Neo4j there is a two-tiered caching architecture which provides this functionality.The lowest tier in the Neo4j cache stack is the filesystem cache. If the filesystem cache reflects the write characteristics of typical usage, then the high level or object cache is all about optimizing for arbitrary read patterns.
在Neo4j中包含两层的缓存架构。最底层缓存是文件系统缓存,主要是操作系统很紧密,上面一层缓存是对象缓存,用于优化任意的读。
9、object cache的架构图
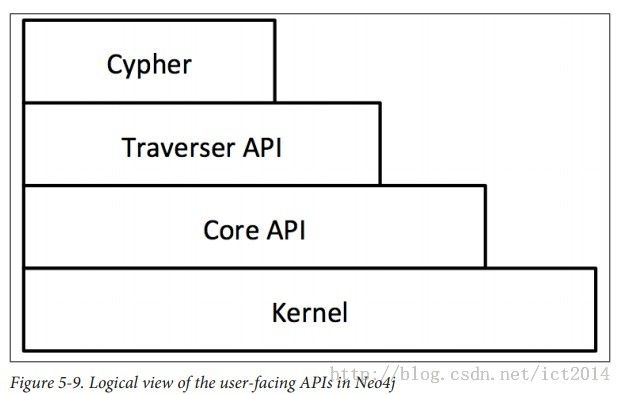
10、Neo4j提供的API结构图:
============================================================================
11、Non-Functional Characteristics
(一)Transactions
(二)Recoverability
(三)Availability
(四)Scale
12、Pregel的高层架构图:
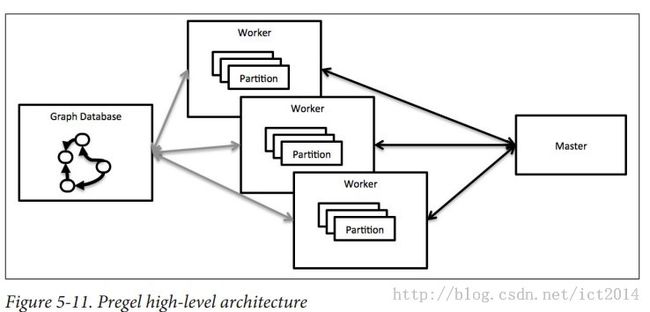
首先将图进行分割成子图,然后每一个worker对子图进行操作。