HDFS之SequenceFile和MapFile
Hadoop的HDFS和MapReduce子框架主要是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗内存资源(每一个小文件占用一个Block,每一个block的元数据都存储在namenode的内存里)。解决办法通常是选择一个容器,将这些小文件组织起来统一存储。HDFS提供了两种类型的容器,分别是SequenceFile和MapFile。
一、SequenceFile
SequenceFile的存储类似于Log文件,所不同的是Log File的每条记录的是纯文本数据,而SequenceFile的每条记录是可序列化的字符数组。
SequenceFile可通过如下API来完成新记录的添加操作:
fileWriter.append(key,value)
可以看到,每条记录以键值对的方式进行组织,但前提是Key和Value需具备序列化和反序列化的功能
Hadoop预定义了一些Key Class和Value Class,他们直接或间接实现了Writable接口,满足了该功能,包括:
Text 等同于Java中的String
IntWritable 等同于Java中的Int
BooleanWritable 等同于Java中的Boolean
.
.
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,如图所示:
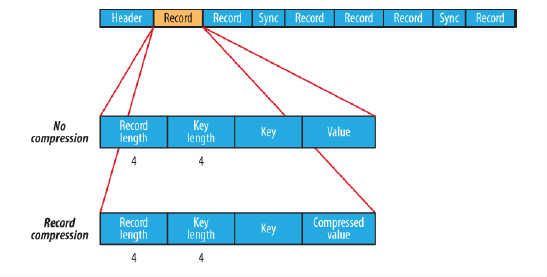
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
block compression是将一连串的record组织到一起,统一压缩成一个block,如图所示:
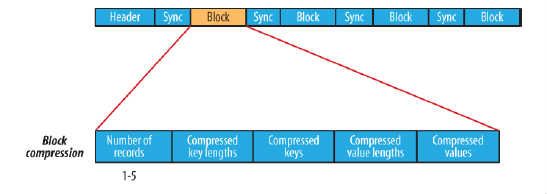
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合
注:每个block的大小是可通过io.seqfile.compress.blocksize属性来指定的
示例:SequenceFile读/写 操作
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path seqFile=new Path("seqFile.seq");
//Reader内部类用于文件的读取操作
SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
//Writer内部类用于文件的写操作,假设Key和Value都为Text类型
SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
//通过writer向文档中写入记录
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//关闭write流
//通过reader从文档中读取记录
Text key=new Text();
Text value=new Text();
while(reader.next(key,value)){
System.out.println(key);
System.out.println(value);
}
IOUtils.closeStream(reader);//关闭read流
二、MapFile
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
示例:MapFile读写操作
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path mapFile=new Path("mapFile.map");
//Reader内部类用于文件的读取操作
MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
//Writer内部类用于文件的写操作,假设Key和Value都为Text类型
MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
//通过writer向文档中写入记录
writer.append(new Text("key"),new Text("value"));
IOUtils.closeStream(writer);//关闭write流
//通过reader从文档中读取记录
Text key=new Text();
Text value=new Text();
while(reader.next(key,value)){
System.out.println(key);
System.out.println(key);
}
IOUtils.closeStream(reader);//关闭read流
注意:使用MapFile或SequenceFile虽然可以解决HDFS中小文件的存储问题,但也有一定局限性,如:
1.文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录
2.当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的