Strom及DRPC性能测试与改进
参考1:storm性能
测试报告
参考2:Storm DRPC 使用
参考3:Storm DRPC 使用及访问C++ Bolt问题的解决方法
参考4:Storm 多语言支持之ShellBolt原理及改进
参考5:Base64编码及编码
性能测试
参考6:Base64编码及编码性能测试 [改进]
参考7:zlib使用与性能测试
参考8:十分简单的redis使用说明及性能测试
[参考1]的结论与局限
参考种对
Storm性能进行测试,得出了以下结论:
storm单条流水线的处理能力大约为20000 tupe/s, (每个tuple大小为1000字节)
storm系统本省的处理延迟为毫秒级
在集群中横向扩展可以增加系统的处理能力,实测结果为1.6倍
Storm中大量的使用了线程,即使单条处理流水线的系统,也有十几个线程在同时运行,所以几乎所有的16个CPU都在运行状态,load average 约为 3.5
Jvm GC一般情况下对系统性能影响有限,但是内存紧张时,GC会成为系统性能的瓶颈
使用外部处理程序性能下降明显,所以在高性能要求下,尽量使用storm内建的处理模式
作者对strom的处理能力和可扩展性进行了测试,给出了很有说服力的数据。但还不能满足我们的需要:
1)由于作者使用的tuple为1000字节,也就是1K,数据量相对较小,而在实际使用过程中,storm作为实时流处理系统,处理的数据可能比较大。比如我们用来进行图像处理,一个图片可能有1M左右。这时候storm的性能如何呢?
2)为了简化storm的集成,我们使用DRPC来访问storm,具体用法可参见[参考2]和[参考3],在DRPC访问时,数据需要从DRPCClient发送至DRPCServer,再由DRPCServer发送给topology中的spout,spoout发送给Bolt........;当数据处理完毕后,还要由Bolt返回给DPRCServer,由DRPCServer返回给DRPCClient。
增加了这些步骤以后,Strom DRPC的性能究竟如何呢?
3)作者在[参考1]中提到,使用外部处理程序时Storm的性能明显下降,大概只有1/10的性能。但是我们在实际使用中,可能经常是在已有的基础上,将功能集成到Storm中运行。通俗点说:实际情况是我们经常使用外部处理程序,这种情况下,怎么能提高Storm的性能呢?关于这点可以查看[参考4]。我们使用JNI来解决。
测试与结论
1)测试环境
测试环境如图所示
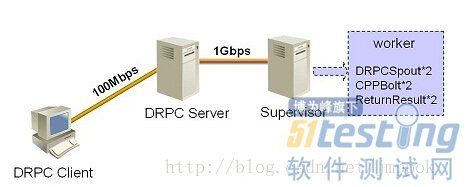
有客户端和两台服务器组成。
客户端为虚拟机,单核3.2GHz 1G 内存,100M带宽。
服务器也是虚拟机,8核2.2GHz,8G内存,1G带宽。
DRPC Topology由一个DRPCSpout,CPPBolt和一个ReturnResult组成。功能是接收一个字符串并返回。
Topology运行在一个work中,Spout,Bolt分别由不同的线程执行。
2)测试方法
在Client启动0-100多个线程,不停的访问Topology,向其发送一个字符串(1K-1M)。Topology会原封不动的返回该字符串。
测试过程就不详细展开了。直接说测试结果。
3)测试结论
该测试中,处理速度主要受限于客户端带宽。也就是说由于数据量大,客户端发的速度慢,低于Storm中topology的处理速度。
因此该测试只能得出DRPC方式中单个请求在不同数据大小时,storm的延迟时间。
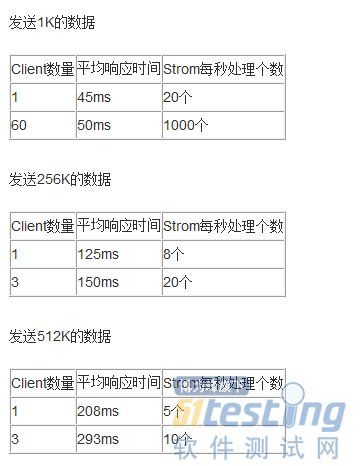
简而言之,StormDRPC方式中,最小延迟为50ms(数据小于1K),当数据量大时,256K数据,延迟为125ms,512K时延迟为208ms。
所以Storm数据量较大的时,处理的延迟还是比较大的。
当然以上仅是在特定环境中的测试,仅供参考。
改进方法
根据个人经验,针对以上Storm延迟可以由以下改进方法:
1)数据可以先压缩后再交给storm处理,在具体的bolt中对其进行解压缩。根据个人测试zlib压缩1M的数据,压缩率为80%,既可以将数据研所为原来的20%。从而可以减小数据量,提高效率。而zlib对1M数据进行压缩、解压缩所用时间在10ms以内。可以使情况选用。见[参考7]
2)storm本身采用字符型传输,对于二进制数据必须进行编码。可采用base64编码。参见[参考5],base64对1M数据的编码,解码时间也分别小于10ms。
3)在DRPC测试中,数据从Clinet到DRPCServer,到DRPC SPOUT,到BOLT,到RETURN Result,在到DRPCSERVER,最后返回Client传输多次,可以考虑使用内存数据库如redis,Client直接将数据放入redis,将其在redis中的路径进行传输,在需要时,由bolt从redis中获取。参见[参考8]。将1M数据在redis中存取,耗时也分别在10-20ms。
4)对于外部处理程序,如C++,可以采用JNI的方式,对ShellBolt进行改进,而不是启动新的进程在通过Json编码,Pipe传输与之通讯,从而也可以提交效率。参见[参考4]。
|
English »
|
AfrikaansAlbanianArabicArmenianAzerbaijaniBasqueBengaliBelarusianBulgarianCatalanChinese (Simp)Chinese (Trad)CroatianCzechDanishDutchEnglishEsperantoEstonianFilipinoFinnishFrenchGalicianGeorgianGermanGreekGujaratiHaitian CreoleHebrewHindiHungarianIcelandicIndonesianIrishItalianJapaneseKannadaKoreanLaoLatinLatvianLithuanianMacedonianMalayMalteseNorwegianPersianPolishPortugueseRomanianRussianSerbianSlovakSlovenianSpanishSwahiliSwedishTamilTeluguThaiTurkishUkrainianUrduVietnameseWelshYiddish |
Options : History : Help : Feedback
Text-to-speech function is limited to 100 characters