IPVS(也叫LVS)的源码分析之persistent参数
最近在用 LVS做 LB,发现一个问题客户端总是出现session丢失问题,采用常用配置,均衡策略使用wlc, 看了一下wlc的策略相同的客户端都有可能轮训到不同的后台机器,在后台服务器上并没有对session进行复制,那样的却会导致客户端访问不同的服务器而导致在session丢失。
本简单的以为通过调整均衡策略就可以确保对同一客户端映射到相同的服务器,均衡策略参考(点击打开链接),而策略里面只有Source Hashing Scheduling 看起来可以达到这个目的,但是这个策略并不是推荐的策略。
在查看ipvsadmin的参数的时候,发现了参数-p,
-p, --persistent [timeout]:设置持久连接,这个模式可以使来自客户的多个请求被送到同一个真实服务器
感觉-p 参数和Source Hashing Scheduling 的策略有点类似,还是看代码来解决问题
IPVS也叫LVS
LVS 是属于内核模块中的,代码直接就可以在内核代码中找到,在内核中的名字是IPVS,我们下面还是以IPVS来称呼
Ipvs 的代码就挂载在/net/netfilter/ipvs中,在这里我们也可以看出IPVS是基于Netfilter框架实现的内核模块,linux 中的netfilter的架构就是在整个网络流程的若干位置放置了一些检测点(HOOK),而在每个检测点上登记了一些处理函数进行处理(如包过滤,NAT等,甚至可以是用户自定义的功能)。
Netfilter实现
Netfilter的状态图:
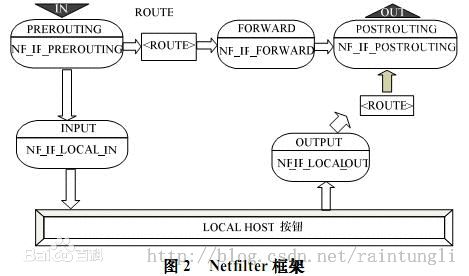
而Ipvs 在Netfilter中的几个状态中注册了钩子函数
static struct nf_hook_ops ip_vs_ops[] __read_mostly = {
/* After packet filtering, forward packet through VS/DR, VS/TUN,
* or VS/NAT(change destination), so that filtering rules can be
* applied to IPVS. */
{
.hook = ip_vs_in,
.owner = THIS_MODULE,
.pf = PF_INET,
.hooknum = NF_INET_LOCAL_IN,
.priority = 100,
},
/* After packet filtering, change source only for VS/NAT */
{
.hook = ip_vs_out,
.owner = THIS_MODULE,
.pf = PF_INET,
.hooknum = NF_INET_FORWARD,
.priority = 100,
},
/* After packet filtering (but before ip_vs_out_icmp), catch icmp
* destined for 0.0.0.0/0, which is for incoming IPVS connections */
{
.hook = ip_vs_forward_icmp,
.owner = THIS_MODULE,
.pf = PF_INET,
.hooknum = NF_INET_FORWARD,
.priority = 99,
},
/* Before the netfilter connection tracking, exit from POST_ROUTING */
{
.hook = ip_vs_post_routing,
.owner = THIS_MODULE,
.pf = PF_INET,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC-1,
},
而均衡策略主要实现在状态NF_INET_LOCAL_IN所对应的钩子函数ip_vs_in
IPVS中的2个结构体
1. ip_vs_conn 里面记录了客户端的地址,IPVS 所建立的虚拟地址,对应到真实的服务器的地址
2. ip_vs_protocol 记录在不同的协议(TCP, UDP)中的不同的钩子函数,比如使用什么类型的调度,什么函数接受数据
struct ip_vs_protocol ip_vs_protocol_tcp = {
.name = "TCP",
.protocol = IPPROTO_TCP,
.num_states = IP_VS_TCP_S_LAST,
.dont_defrag = 0,
.appcnt = ATOMIC_INIT(0),
.init = ip_vs_tcp_init,
.exit = ip_vs_tcp_exit,
.register_app = tcp_register_app,
.unregister_app = tcp_unregister_app,
.conn_schedule = tcp_conn_schedule,
.conn_in_get = tcp_conn_in_get,
.conn_out_get = tcp_conn_out_get,
.snat_handler = tcp_snat_handler,
.dnat_handler = tcp_dnat_handler,
.csum_check = tcp_csum_check,
.state_name = tcp_state_name,
.state_transition = tcp_state_transition,
.app_conn_bind = tcp_app_conn_bind,
.debug_packet = ip_vs_tcpudp_debug_packet,
.timeout_change = tcp_timeout_change,
.set_state_timeout = tcp_set_state_timeout,
};
这是一个TCP下的ip_vs_protocol 的结构体,里面重要的是conn_in_get 函数也是在钩子函数ip_vs_in里调用的
static unsigned int
ip_vs_in(unsigned int hooknum, struct sk_buff *skb,
const struct net_device *in, const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
...
pp = ip_vs_proto_get(iph.protocol);
if (unlikely(!pp))
return NF_ACCEPT;
/*
* Check if the packet belongs to an existing connection entry
*/
cp = pp->conn_in_get(af, skb, pp, &iph, iph.len, 0);
...
}我们已常见的TCP为例,最终调用了函数
tcp_conn_in_get
ip_vs_conn的全局数组ip_vs_conn_tab和链表c_list
这是一张全局的ip_vs_conn数组,保存这所有的以连接。通过客户端ip,port算出的hash,来计算到保存的 ip_vs_conn数组。
ip_vs_conn本身也保存一个链表c_list,这是个链表结构保存ip_vs_conn
初始化
在IPVS初始化的时候,就初始化了数组的大小,大小是不可变的(1<<12 )4096
当客户端hash算出相同的时候,通过遍历ip_vs_conn里面的c_list链表找到匹配的客户端(地址和端口相同)
如果找不到对应的ip_vs_conn, 这时候才调用
if (!pp->conn_schedule(af, skb, pp, &v, &cp)) return v;而对tcp 中的conn_schedule 的钩子函数就是tcp_conn_schedule,也就是我们前面说到的调度算法的核心函数
static int
tcp_conn_schedule(int af, struct sk_buff *skb, struct ip_vs_protocol *pp,
int *verdict, struct ip_vs_conn **cpp)
{
struct ip_vs_service *svc;
struct tcphdr _tcph, *th;
struct ip_vs_iphdr iph;
ip_vs_fill_iphdr(af, skb_network_header(skb), &iph);
th = skb_header_pointer(skb, iph.len, sizeof(_tcph), &_tcph);
if (th == NULL) {
*verdict = NF_DROP;
return 0;
}
if (th->syn &&
(svc = ip_vs_service_get(af, skb->mark, iph.protocol, &iph.daddr,
th->dest))) {
if (ip_vs_todrop()) {
/*
* It seems that we are very loaded.
* We have to drop this packet :(
*/
ip_vs_service_put(svc);
*verdict = NF_DROP;
return 0;
}
/*
* Let the virtual server select a real server for the
* incoming connection, and create a connection entry.
*/
*cpp = ip_vs_schedule(svc, skb); //调用了ip_vs_schedule
if (!*cpp) {
*verdict = ip_vs_leave(svc, skb, pp);
return 0;
}
ip_vs_service_put(svc);
}
return 1;
}
函数ip_vs_schedule
struct ip_vs_conn *
ip_vs_schedule(struct ip_vs_service *svc, const struct sk_buff *skb)
{
...
/*
* Persistent service
*/
if (svc->flags & IP_VS_SVC_F_PERSISTENT)
return ip_vs_sched_persist(svc, skb, pptr);
/*
* Non-persistent service
*/
if (!svc->fwmark && pptr[1] != svc->port) {
if (!svc->port)
pr_err("Schedule: port zero only supported "
"in persistent services, "
"check your ipvs configuration\n");
return NULL;
}
<span style="white-space:pre"> </span>....
return cp;
}我们看到了IP_VS_SVC_F_PERSISTENT, 也就是参数persistent
参数persistent 的实现
创建ip_vs_conn 模版
保证在一定的时间内相同的客户端ip还是连接原来的服务器,那就意味着需要保留原来的客户端ip的上次的连接的真实服务器。
在IPVS里并没有生成另一个数组去保留这个状态,而是引入了一个ip_vs_conn 模版,而这个ip_vs_conn 模版仍旧保存在前面提到的全局表中的ip_vs_conn_tab
既然保存在同一个全局表,那么这个模版和普通的ip_vs_conn有什么区别?很简单,这里只要设置客户端的port 为0,而把连到真实的server的IP 保存到ip_vs_conn中去
具体实现参考函数:ip_vs_sched_persist
什么时候清除ip_vs_conn 模版?
-p 参数有指定时间,ip_vs_conn结构体中存在一个timer和timeout的时间,在函数新建连接的时候,设置了timer的执行函数ip_vs_conn_expire
struct ip_vs_conn *
ip_vs_conn_new(int af, int proto, const union nf_inet_addr *caddr, __be16 cport,
const union nf_inet_addr *vaddr, __be16 vport,
const union nf_inet_addr *daddr, __be16 dport, unsigned flags,
struct ip_vs_dest *dest)
{
<span style="white-space:pre"> </span>......
setup_timer(&cp->timer, ip_vs_conn_expire, (unsigned long)cp);
......
return cp;
}
函数ip_vs_conn_expire里从ip_vs_conn_tab移除了ip_vs_conn超时的模版
而在ip_vs_sched_persist 函数里,当每次创建新的连接的时候,同时也更新了ip_vs_conn模版的timer的触发时间(当前时间+-p 参数的timeout时间),实现在函数ip_vs_conn_put中。
完整流程图
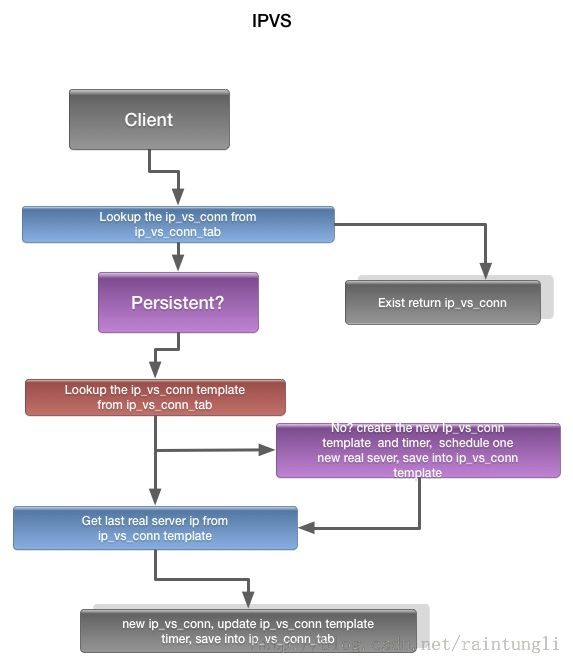
IPVS的debug日志
需要从新编译内核,设置config 里的参数
CONFIG_IP_VS_DEBUG=Y
编译后,还要修改参数
/proc/sys/net/ipv4/vs/debug_level
设置为12 ,日志打印到dmesg中
IPVS ip_vs_conn_tab 里的entry
内容可以通过 /proc/net/ip_vs_conn_entries 访问
IPVS 不设置persistent参数
如果不设置persistent参数,也就是意味着不需要保证同一个客户端在一个固定时间段中连接到同一个真实得服务器,那么ipvs会使用调度算法去调度每一个来自客户端得新连接。
函数ip_vs_conn里面,当没有设置persistent参数得时候,会直接调用dest = svc->scheduler->schedule(svc, skb);来调度新得连接。