Intel Threading Building Blocks 编程指南:简单循环的并行化
可伸缩并行化的最简单的形式就是能够互不干涉地同时运行的迭代的循环。本节将会说明如何将简单的循环并行化。
定义 Intel Threading Building Blocks(Intel TBB) 组件的命名空间是 tbb 。简洁起见,只在第一次提到某个组件时显式展示命名空间。编译 Intel TBB 程序时,记得要链接 Intel TBB 共享库。
库的初始化与终止
从Intel TBB 2.2 开始,任务调度器就是自动初始化的。参考文档描述了如何利用 task_scheduler_init 来显式的初始化任务调度器。这在以下事物中会派上用场:
- 控制任务调度器的构造与析构
- 指定任务调度器使用的线程数量
- 为工作者线程指定栈尺寸
parallel_for
假设你想要对某个数组的所有元素都应用函数 Foo,并且能安全地同时处理。先列出来串行化的代码版本:
void SerialApplyFoo( float a[], size_t n )
{
for( size_t i=0; i!=n; ++i )
Foo(a[i]);
}
迭代空间的类型为 size_t ,范围从0到 n-1 。模板函数 tbb::parallel_for 会将此迭代空间打散为一些块(chunk),在每个块上运行一个独立的线程。将此循环并行化的第一个步骤是将此循环体转变成对块的操作的形式。这种形式是一种STL风格的函数对象,叫做实体对象(body object),其中 operator() 处理一个块。下面的代码声明了这个实体对象。
#include "tbb/tbb.h"
using namespace tbb;
class ApplyFoo
{
float *const my_a;
public:
void operator ()(const blocked_range<size_t>& r) const
{
float *a = my_a;
for (size_t i = r.begin(); i != r.end(); ++i) Foo(a[i]);
}
ApplyFoo(float a[]) :
my_a(a)
{
}
};
例子中的 using 指令可以使你在使用 tbb 中定义的数据时不需要每次都加上 tbb 前缀(就是命名空间的一般用法,但个人认为在头文件中使用using namespace xxx 算不上好习惯)。后面的例子都假定提供了这么个 using 指令。
注意 operator() 的参数。blocked_range<T> 是intel tbb 库提供的一个模板类。它以类型 T 上声明了一个一维迭代空间。parallel_for 也能接受其他类型的迭代空间。Intel TBB 库为二维空间提供了 blocked_range2d。你也可以定义自己的空间(后面的章节会提到)
ApplyFoo 的实例需要成员变量来记住所有在初始循环的外部定义却在内部使用的局部变量。由于parallel_for 并不在意实体对象的创建方式,这些成员变量通常由实体对象的构造函数初始化。模板函数parallel_for 要求实体对象有拷贝构造函数,通过调用它为每个工作者线程创建隔离的拷贝。它也通过调用析构函数来销毁这些拷贝。在大多数情况下,隐式产生的拷贝构造函数与析构函数就够用了。如果不满足需求,那么为了一致性,你就要同时定义两者。
因为实体对象可能被拷贝,它的 operator() 就不能修改实体。否则,这些改动对于调用 parallel_for 的线程可见与否依赖于 operator() 执行是在原始对象还是在拷贝对象上。为了凸显这点小差别, parallel_for 要求实体对象的 operator () 声明为 const.
示例的 operator() 将 my_a 加载到局部变量 a 。虽然不是必须的,还是有两点理由这么做:
- 风格。 这让循环体看起来更像是原始的。
- 性能。有些时候将频繁访问的值放入局部变量中有利于编辑器更好地对此循环优化,因为局部变量通常更易于编译器跟踪。
一旦你将循环体写成了实体对象,使用下面的方式调用模板方法parallel_for:
#include "tbb/tbb.h"
void ParallelApplyFoo(float a[], size_t n)
{
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a));
}
这里构造的 blocked_range 代表了从 0 到 n -1 的整个迭代区域。parallel_for 会将此区域为每个处理器分出子区域。构造函数的一般形式是 blocked_range<T>(begin, end, grainsize) 。 T 指定了值的类型。 参数 begin 和 end 规定半开放区间[begin,end) 作为该迭代区域的STL样式。参数 grainsize 后面会提到。例子使用默认的 grainsize值(1),因为默认情况下, parallel_for的启发式算法能在默认粒度下很好的工作。
Lambda 表达式
关于lambda表达式可以参考我以前的blog。采用lambda表达式,上面的例子可以写为:
#include "tbb/tbb.h"
using namespace tbb;
#pragma warning( disable: 588)
void ParallelApplyFoo(float *a, size_t n)
{
parallel_for(blocked_range<size_t>(0, n),
[=](const blocked_range<size_t>& r)
{
for (size_t i = r.begin(); i != r.end(); ++i)
Foo(a[i]);
});
}
为了更紧凑,对于在一个整形的连续区域执行并行循环,TBB有对应形式的 parallel_for 。表达式 parallel_for(first,last,step,f) 就像 for(auto i = first; i< last; i+= step) f(i) ,只是在资源许可的情况下, 每个 f(i) 可以并行求值。参数 step 是可选的。前面的例子可以重写为如下紧凑形式:
#include "tbb/tbb.h"
using namespace tbb;
#pragma warning(disable: 588)
void ParallelApplyFoo(float a[], size_t n)
{
parallel_for(size_t(0), n, [=](size_t i)
{
Foo(a[i]);
});
}
紧凑形式只能支持整形的线性迭代空间。自动分块特性将在下面介绍。
自动分块
并行循环的构造导致它调度工作的每个分块额外的开销。从2.2 版本开始,Intel TBB 视负载平衡所需自动选择分块尺寸。TBB采用的启发式算法会限制开销,同时为负载均衡提供足够的可选项。
注意:典型地,一个至少需要100万个时钟周期的循环才能使用parallel_for来提高性能。例如,在一个2GHz的处理器上需要500微秒的循环是可以从parallel_for 受益的。
对于大部分应用,推荐使用默认的自动分块。然而,伴随大多数启发式算法,总有一些更精确地控制块的尺寸会产生更好性能的情况。下一节会解释。
控制分块
分块是通过分区(partitioner)和粒度(grainsize)控制的。为了分块时获得最大的控制权,两者都需要指定。
- 指定 simple_partitioner() 作为 parallel_for 的第三个参数。关闭自动分块。
- 指定构造区间时的粒度。这里讨论的构造形式为:blocked_range<T>(begin,end,grainsize) 。 grainsize 的默认值为1,它是每个块的循环迭代的单位。
如果块太小,间接的开销可能更甚于有用的工作。
上节的例子修改为使用显式的粒度 G :
#include "tbb/tbb.h"
void ParallelApplyFoo( float a[], size_t n )
{
parallel_for(blocked_range<size_t>(0,n,G), ApplyFoo(a),
simple_partitioner());
}
粒度为并行设置了最低门槛。例子中的 parallel_for 在块上(大小不见得一样)调用 ApplyFoo::operator() 。让块尺寸作为在块上迭代的数量。使用 simple_partitioner 确保 [G/2] <= chunksize <= G 。
使用auto_partitioner、affinity_partitioner时,可以仅为区间(range)指定粒度,这是一种中等级别的控制。auto_partitioner是默认的分区器。两个分区器都实现了“自动分块”一节中描述的自动粒度启发式算法。affinity_partitioner 实现了额外的窍门(在下面的“带宽与缓存亲缘性”一节中解释)。虽然这些分区器可能导致超出 G 迭代数量的块,但不会产生少于 [G/2] 迭代的块。分区器在启发式算法失败时会产生浪费性的小块,虽然偶然,但显式指定区间粒度会很有用。
由于并行循环中粒度划分的影响,即使你信赖auto_partitioner、affinity_partitioner来自动选择粒度,下面的资料仍然值得一读。

上图以表示损耗的棕色边框内的灰色区域表示有效工作,揭示了粒度划分的影响。两张图包含的有效工作总量是相等的。图A展示了过于细分的粒度是如何导致了相对高昂的损耗比例。图B展示了大粒度以减少可能的并行数为牺牲来减少这个比例。作为有用工作一部分的损耗开销取决于粒的大小(粒度),而不是粒的数量。设置粒度时,考虑这种关系而不是迭代的总数或者处理器的数目。
一个经验法则是 operator() 的 迭代粒度至少需要100,000个时钟周期来执行。例如,如果单个迭代需要100个时钟,那么 grainsize 至少需要 1000 个迭代。如果有疑问,请执行下面的实验:
- 将 grainsize 参数的值设置的高于所需。粒度以循环迭代为单位指定。如果你对每个迭代消耗多少个时钟周期不清楚,就使用 grainsize = 100,000. 基本原理就是每个迭代通常需要至少一个时钟周期。大多数情况下,步骤3会引导你拿到一个小得多的值。
- 运行你的算法
- 迭代将 grainsize 减半,观察每次的算法运行速度随着值得减少产生的快慢变化。
提示:并不需要将粒度设置的非常精确
下图展示了由不同粒度划分的执行时间组成的一种典型的“浴盆曲线”(基于百万计的浮点 运算a[i] = b[i]*c)。每个迭代需要的时间都很少。这些时间是在一个四核八线程的机器上搜集来的:
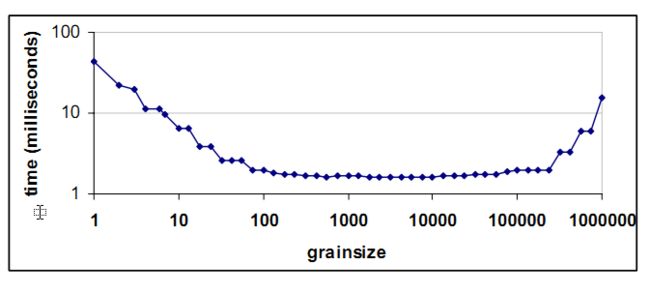
刻度基于对数。左边的倾斜指示,如果粒度很小,大多的消耗是并行调度损耗,而不是有用工作。增加粒度时,并行损耗也会相应的减少。接着曲线就趋于平坦,因为对于足够大的粒度,并行开销变得不明显了。到了右边的末尾,曲线又上扬了。这是因为粒度过大,同时运行的块不足以匹配处理器线程的数量。不过也能看出来,粒度的划分在位于100-100,000这个广域区间内都是合适的。所以划分粒度时不用太紧张。
注意: 嵌套循环并行化的一般性经验法则是尽可能并行化最外层。原因是外层循环的每个迭代通常能比内层的循环提供更大的工作粒度。
带宽与缓存(cache)亲缘性
对于足够简单的函数 Foo, 编写成并行循环的例子也许不能展现出良好的加速效果。原因可能是处理器与内存间的系统带宽不足。这种情况下,你可能要重新考虑算法以便更好地利用缓存(cache)。为更好地利用缓存进行重构通常会使程序(无论并行还是串行)受益。
某些情况下的重构的一种替代方案是 affinity_partitioner. 他不仅自动选择粒度,而且优化缓存的亲缘性。使用它在下列情况下会显著地改进性能:
- 每次数据问题时,计算只有少量操作
- 被循环访问的数据适合留在缓存中
- 循环,或者类似的循环,在同样的数据上重复执行
- 可用硬件线程的数量多于两个。如果只有两个线程可用,intel TBB 的默认调度会提供良好的缓存亲缘性。
下面的代码展示了如何使用 affinity_partitioner:
#include "tbb/tbb.h"
void ParallelApplyFoo(float a[], size_t n)
{
static affinity_partitioner ap;
parallel_for(blocked_range<size_t>(0, n), ApplyFoo(a), ap);
}
void TimeStepFoo(float a[], size_t n, int steps)
{
for (int t = 0; t < steps; ++t)
ParallelApplyFoo(a, n);
}
在这个示例中,affinity_partitioner 的对象 ap 存在于循环迭代中。它记着循环的迭代从哪里执行,这样每个迭代都能被以前执行它的线程处理。示例中将 affinity_partitioner 的对象示例声明为局部静态变量来得到 ap 正确的生存周期。另一种方法是将它定义在 TimeStepFoo 函数中循环体的外面, 传递给 parallel_for 的调用链。
如果数据不适合跨系统的缓存,好处就很小了。下图展示了这些情况:

下图展示了随着数据集的大小不同并行加速的异同。示例中,是对区间 [0,N) 计算 A[i] += B[i]。它是为了突出效果特地挑选的。你应该不希望在自己的代码中看到这么多变体。图表显示,一些极端情况下,得不到什么改善。当 N 很小时,由于并行调度损耗的影响,没什么加速效果。当 N 很大时, 数据集因为太大而不能被装载进循环调用间的缓存。中间的高峰是亲缘性的最佳区域。因此,当由于内存访问导致低效的计算时,affinity_partitioner 应该被作为一个工具,而不是包治百病的灵丹妙药。

分区器总结
| 分区器 |
描述 |
与 blocked_range(i,j,g)共同使用时 |
| simple_partitioner |
以粒度为单位选择块大小 |
[g/2] <= chunksize <= g |
| auto_partitioner (2.2版本之前是simple_partitioner) |
自动选择块大小 |
[g/2] <= chunksize |
| affinity_partitioner |
自动选择块大小以及缓存亲缘性 |
[g/2] <= chunksize |
-
operator() 的子区域(subrange)不能超出某个限度。 这可能是有利的。例如,如果你的operator() 需要一个跟区域大小成正比的临时数组。子区域的大小限定了,你就可以为这个数组使用一个自动变量而不是使用动态内存分配。
-
大尺度的子区域不能有效使用缓存。例如,假定一个子区域的处理流程需要重复清理同一块内存区域。保持子区域在某个限度下可以使重复引用的内存区域适合放入缓存。这个场景的例子请参考 parallel_reduce 在 example/parallel_reduce/primes/primes.cpp 中的使用。
-
你想调整为某个特定的机器。
parallel_reduce
循环可以做减量,像这样:
float SerialSumFoo(float a[], size_t n)
{
float sum = 0;
for (size_t i = 0; i != n; ++i)
sum += Foo(a[i]);
return sum;
}
如果迭代是独立的,你可以使用模板类 parallel_reduce 来并行化这个循环:
float ParallelSumFoo( const float a[], size_t n )
{
SumFoo sf(a);
parallel_reduce( blocked_range<size_t>(0,n), sf );
return sf.my_sum;
}
类 SumFoo 指定了降低的细节,诸如怎么累加子总和并将它们合并。下面是 SumFoo 的定义:
class SumFoo
{
float* my_a;
public:
float my_sum;
void operator()( const blocked_range<size_t>& r )
{
float *a = my_a;
float sum = my_sum;
size_t end = r.end();
for( size_t i=r.begin(); i!=end; ++i )
sum += Foo(a[i]);
my_sum = sum;
}
SumFoo( SumFoo& x, split ) : my_a(x.my_a), my_sum(0) {}
void join( const SumFoo& y ) {my_sum+=y.my_sum;}
SumFoo(float a[] ) :
my_a(a), my_sum(0)
{}
};
注意与 parallel_for 章节中提到的 ApplyFoo 类的区别。第一,operator() 不是 const . 这是因为它必须更新 SumFoo::my_sum. 第二,SumFoo 提供分割构造函数以及一个 join 方法以使 parallel_reduce 工作。分割构造函数需要两个参数,其一,一个指向原始对象的引用,其二,一个类型为 split(TBB库中定义) 的哑元参数。这个哑元参数将分割构造函数与拷贝构造函数区分开。
提示:实例中, operator() 的定义为访问标量值在循环内部使用局部临时变量(a, sum, end)。这种技术通过明白告诉编译器这些值可以放在缓存中而不是内存中来提高性能。如果这些值过大不适合放进寄存器,或者以一种编译器不能追踪的方式获取地址,这项技术就没用了。在一个典型的优化编译器中,为只写变量(如例子中的 sum )使用局部临时变量应该足够了。因为随后编译器就能推断这个循环不会写任何其他的位置,并将其他的读取提升到循环外。
当任务调度器确定工作者线程有效时, parallel_reduce 调用分割构造函数为工作者创建子任务。当子任务完工后, parallel_reduce 使用 join 方法 来累加子任务的结果。下图的顶部展示了当一个工作者有效时发生的分割-合并序列:

图中的步骤,按照时间顺序从上往下。分割构造函数也许在对象 x 被约减操作迭代区域的第一半(就是方框【reduce first half of iteration space】)使用时并行运行。因此,分割构造函数的所有创建对象 y 的行为对于 x 都必须是线程安全的。这样,如果分割构造函数需要增加一个与其他对象共享的引用计数,它就得使用原子操作(atomic increment)。
如果没有工作者线程可用,迭代的第二半约减操作时就使用第一半使用过的同一个实体对象。它开始的地方,就是第一半结束的地方。
小心: 因为分割/合并在没有有效工作者时不能派上用场, parallel_reduce 没有必要做递归分割。
小心:因为同一个实体(body)可能被用来累加多个子区域, operator() 不能丢弃早先的累加值就至关重要了。下面的代码展示了一种错误定义SumFoo::operator()的方式:
class SumFoo
{
....
public:
float my_sum;
void operator()( const blocked_range<size_t>& r )
{
...
float sum = 0; // WRONG – should be "sum = my_sum".
...
for( ... )
sum += Foo(a[i]);
my_sum = sum;
}
...
};
由于错误的函数实现,operator() 只是返回了应用parallel_reduce后最后一个子区域而不是所有子区域的值。parallel_reduce 的分区器与粒度的规则跟 parallel_for 是一样的。
parallel_reduce 归纳了所有相关操作。通常,分割构造函数会做两件事:
- 拷贝必要的只读信息来运行循环体
- 初始化约减操作标识元素的变量
join 方法做相应的合并操作。你可以在同一时间做多个约减操作:可以使用单个parallel_reduce 同时搜集最大、最小
注意:约减(reduction)操作可以是不可交换的。例子中浮点数加法如果替换成了字符串连接,同样可行。
高级示例
一个高级点的联合操作的例子是找到最小 Foo(i) 的索引。串行版本是这样的:
long SerialMinIndexFoo( const float a[], size_t n )
{
float value_of_min = FLT_MAX; // FLT_MAX from <climits>
long index_of_min = -1;
for( size_t i=0; i<n; ++i )
{
float value = Foo(a[i]);
if( value<value_of_min )
{
value_of_min = value;
index_of_min = i;
}
}
return index_of_min;
}
循环的工作方式就是保持最终找到的最小值以及这个值的索引。这是循环迭代间携带的唯一信息。为了将此循环转换成parallel_reduce, 函数对象(operator() )必须保持追踪这个携带信息,并知道如何在这些迭代跨越多个线程时合并这个信息。同样,函数对象必须记录一个指向 a 的指针来提供上下文。
下面的代码展示了完整的函数对象:
class MinIndexFoo
{
const float *const my_a;
public:
float value_of_min;
long index_of_min;
void operator ()(const blocked_range<size_t>& r)
{
const float *a = my_a;
for (size_t i = r.begin(); i != r.end(); ++i)
{
float value = Foo(a[i]);
if (value < value_of_min)
{
value_of_min = value;
index_of_min = i;
}
}
}
MinIndexFoo(MinIndexFoo& x, split) :
my_a(x.my_a),
value_of_min(FLT_MAX), // FLT_MAX from <climits>
index_of_min(-1)
{
}
void join(const SumFoo& y)
{
if (y.value_of_min < value_of_min)
{
value_of_min = y.value_of_min;
index_of_min = y.index_of_min;
}
}
MinIndexFoo(const float a[]) :
my_a(a),
value_of_min(FLT_MAX), // FLT_MAX from <climits>
index_of_min(-1),
{
}
};
现在可以使用parallel_reduce来重写 SerialMinIndex 了:
long ParallelMinIndexFoo(float a[], size_t n)
{
MinIndexFoo mif(a);
parallel_reduce(blocked_range<size_t>(0, n), mif);
return mif.index_of_min;
} examples/parallel_reduce/primes 目录包含了一个基于 parallel_reduce 的质数查找示例
高级主题:其他种类的迭代区域
截至目前,所有的示例都使用 blocked_range<T> 类 来指定区域。这个类可以在很多情况下使用,但并非适用所有的情况。你可以使用Intel Threading Building Blocks 定义自己的迭代空间对象。这个对象必需提供两个方法以及一个“分割构造函数”指定将其自身分割为子空间的方式。如果这个类叫R, 方法以及构造函数会是下面这样:
class R
{
// True if range is empty
bool empty() const;
// True if range can be split into non-empty subranges
bool is_divisible() const;
// Split r into subranges r and *this
R( R& r, split );
...
};
如果区域为空,empty() 返回 true. 如果区域可被分割为两个非空子区域,而且这个分割带来的好处多于带来的损耗,is_divisible 就返回 true. 分割构造函数有两个参数:
- 第一个类型为 R
- 第二个类型为 tbb::split
第二个参数没用;它只是为了将这个构造函数与普通的拷贝构造函数区分开。分割构造函数会试图将 r 大约分成两个等分, 将 r 更新为第一个等分,将构造出来的对象作为第二个等分。这两个等分都应该是非空的。并行算法模板在只有 r.is_divisible 为 true 的情况下才在 r 调用分割构造函数。
迭代空间不用必须是线性的。tbb/blocked_range2d.h 就是个二维区域的示例。它的分割构造函数试图沿着最长的坐标轴分割此区域。当与parallel_for 一起使用时,它以使循环陷入“递归阻塞”的方式来改进缓存使用。这种漂亮的缓存行为意味着在 blocked_ranged2d<T> 上使用 parallel_for 能让循环比对应的串行版本运行的更快,即使是在单个的处理器上。
代码示例
目录examples/parallel_for/seismic 包含了一个基于parallel_for与blocked_range的简单地震波模拟。目录 examples/parallel_for/tachyou 包含了一个复杂点的基于 parallel_for与 blocked_range2d 的射线追踪器。