Eigenfaces is a well studied method of face recognition based on principal component analysis (PCA), popularised by the seminal work of Turk & Pentland. Although the approach has now largely been superseded, it is still often used as a benchmark to compare the performance of other algorithms against, and serves as a good introduction to subspace-based approaches to face recognition. In this post, I’ll provide a very simple implementation of eigenfaces face recognition using MATLAB.
PCA is a method of transforming a number of correlated variables into a smaller number of uncorrelated variables. Similar to how Fourier analysis is used to decompose a signal into a set of additive orthogonal sinusoids of varying frequencies, PCA decomposes a signal (or image) into a set of additive orthogonal basis vectors oreigenvectors. The main difference is that, while Fourier analysis uses a fixed set of basis functions, the PCA basis vectors are learnt from the data set via unsupervised training. PCA can be applied to the task of face recognition by converting the pixels of an image into a number of eigenface feature vectors, which can then be compared to measure the similarity of two face images.
Note: This code requires the Statistics Toolbox. If you don’t have this, you could take a look at this excellent article by Matthew Dailey, which I discovered while writing this post. He implements the PCA functions manually, so his code doesn’t require any toolboxes.
Loading the images
The first step is to load the training images. You can obtain faces from a variety of publicly available face databases. In these examples, I have used a cropped version of the Caltech 1999 face database. The main requirements are that the faces images must be:
- Greyscale images with a consistent resolution. If using colour images, convert them to greyscale first with
rgb2gray. I used a resolution of 64 × 48 pixels.
- Cropped to only show the face. If the images include background, the face recognition will not work properly, as the background will be incorporated into the classifier. I also usually try to avoid hair, since a persons hair style can change significantly (or they could wear a hat).
- Aligned based on facial features. Because PCA is translation variant, the faces must be frontal and well aligned on facial features such as the eyes, nose and mouth. Most face databases have ground truth available so you don’t need to label these features by hand. The Image Processing Toolbox provides somehandy functions for image registration.
Each image is converted into a column vector and then the images are loaded into a matrix of size n × m, where n is the number of pixels in each image and m is the total number of images. The following code reads in all of the PNG images from the directory specified by input_dir and scales all of the images to the size specified by image_dims:
01 |
input_dir = '/path/to/my/images'; |
02 |
image_dims = [48, 64]; |
04 |
filenames = dir(fullfile(input_dir, '*.png')); |
05 |
num_images = numel(filenames); |
08 |
filename = fullfile(input_dir, filenames(n).name); |
09 |
img = imread(filename); |
11 |
images = zeros(prod(image_dims), num_images); |
13 |
images(:, n) = img(:); |
Training
Training the face detector requires the following steps (compare to the steps to perform PCA):
- Calculate the mean of the input face images
- Subtract the mean from the input images to obtain the mean-shifted images
- Calculate the eigenvectors and eigenvalues of the mean-shifted images
- Order the eigenvectors by their corresponding eigenvalues, in decreasing order
- Retain only the eigenvectors with the largest eigenvalues (the principal components)
- Project the mean-shifted images into the eigenspace using the retained eigenvectors
The code is shown below:
02 |
mean_face = mean(images, 2); |
03 |
shifted_images = images - repmat(mean_face, 1, num_images); |
06 |
[evectors, score, evalues] = princomp(images'); |
10 |
evectors = evectors(:, 1:num_eigenfaces); |
13 |
features = evectors' * shifted_images; |
Steps 1 and 2 allow us to obtain zero-mean face images. Calculating the eigenvectors and eigenvalues in steps 3 and 4 can be achieved using the
princomp function. This function also takes care of mean-shifting the input, so you do not need to perform this manually before calling the function. However, I have still performed the mean-shifting in steps 1 and 2 since it is required for step 6, and the eigenvalues are still calculated as they will be used later to investigate the eigenvectors. The output from step 4 is a matrix of eigenvectors. Since the
princomp function already sorts the eigenvectors by their eigenvalues, step 5 is accomplished simply by truncating the number of columns in the eigenvector matrix. Here we will truncate it to 20 principal components, which is set by the variable
num_eigenfaces; this number was selected somewhat arbitrarily, but I will show you later how you can perform some analysis to make a more educated choice for this value. Step 6 is achieved by projecting the mean-shifted input images into the subspace defined by our truncated set of eigenvectors. For each input image, this projection will generate a feature vector of
num_eigenfaces elements.
Classification
Once the face images have been projected into the eigenspace, the similarity between any pair of face images can be calculated by finding the Euclidean distance  between their corresponding feature vectors
between their corresponding feature vectors  and
and 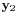 ; the smaller the distance between the feature vectors, the more similar the faces. We can define a simple similarity score
; the smaller the distance between the feature vectors, the more similar the faces. We can define a simple similarity score  based on the inverse Euclidean distance:
based on the inverse Euclidean distance:
=\frac{1}{1+\left\Vert%20\mathbf{y}_{1}-\mathbf{y}_{2}\right\Vert%20}%20\in\left[0,1\right])
To perform face recognition, the similarity score is calculated between an input face image and each of the training images. The matched face is the one with the highest similarity, and the magnitude of the similarity score indicates the confidence of the match (with a unit value indicating an exact match).
Given an input image input_image with the same dimensions image_dims as your training images, the following code will calculate the similarity score to each training image and display the best match:
02 |
feature_vec = evectors' * (input_image(:) - mean_face); |
03 |
similarity_score = arrayfun(@(n) 1 / (1 + norm(features(:,n) - feature_vec)), 1:num_images); |
06 |
[match_score, match_ix] = max(similarity_score); |
09 |
figure, imshow([input_image reshape(images(:,match_ix), image_dims)]); |
10 |
title(sprintf('matches %s, score %f', filenames(match_ix).name, match_score)); |
Below is an example of a true positive match that was found on my training set with a score of 0.4425:
To detect cases where no matching face exists in the training set, you can set a minimum threshold for the similarity score and ignore any matches below this score.
Further analysis
It can be useful to take a look at the eigenvectors or “eigenfaces” that are generated during training:
3 |
for n = 1:num_eigenfaces |
4 |
subplot(2, ceil(num_eigenfaces/2), n); |
5 |
evector = reshape(evectors(:,n), image_dims); |
Above are the 20 eigenfaces that my training set generated. The subspace projection we performed in the final step of training generated a feature vector of 20 coefficients for each image. The feature vectors represent each image as a linear combination of the eigenfaces defined by the coefficients in the feature vector; if we multiply each eigenface by its corresponding coefficient and then sum these weighted eigenfaces together, we can roughly reconstruct the input image. The feature vectors can be thought of as a type of compressed representation of the input images.
Notice that the different eigenfaces shown above seem to accentuate different features of the face. Some focus more on the eyes, others on the nose or mouth, and some a combination of them. If we generated more eigenfaces, they would slowly begin to accentuate noise and high frequency features. I mentioned earlier that our choice of 20 principal components was somewhat arbitrary. Increasing this number would mean that we would retain a larger set of eigenvectors that capture more of the variance within the data set. We can make a more informed choice for this number by examining how much variability each eigenvector accounts for. This variability is given by the eigenvalues. The plot below shows the cumulative eigenvalues for the first 30 principal components:
2 |
normalised_evalues = evalues / sum(evalues); |
3 |
figure, plot(cumsum(normalised_evalues)); |
4 |
xlabel('No. of eigenvectors'), ylabel('Variance accounted for'); |
5 |
xlim([1 30]), ylim([0 1]), grid on; |
We can see that the first eigenvector accounts for 50% of the variance in the data set, while the first 20 eigenvectors together account for just over 85%, and the first 30 eigenvectors for 90%. Increasing the number of eigenvectors generally increases recognition accuracy but also increases computational cost. Note, however, that using too many principal components does not necessarily always lead to higher accuracy, since we eventually reach a point of diminishing returns where the low-eigenvalue components begin to capture unwanted within-class scatter. The ideal number of eigenvectors to retain will depend on the application and the data set, but in general a size that captures around 90% of the variance is usually a reasonable trade-off.