浅谈数组和指针
这应该不是议数据和指针,应该是阅读笔记吧!但是其这个题目更好点。
C专家编程第四章内容:令人震惊的事实:数组和指针并不相同。自己也收获不小,了解很多基础的东西,对那些初入C开发人员有很好的帮助。那废话少说吧。
我们总以为数据和指针是完全等同的,两者是可以互换的,这种说法是片面的。我们在编程中经常使用全局变量,在其他文件中声明中也可以使用这个全局变量。下面就举个例子说明:
文件1:
Int mango[100];
文件2:
Extern int *mango; /*①*/
...
/*一些使用mango的代码*/
这里,文件1定义int 变量mango,但文件2声明它为指针int *型,这里显然是类型不匹配,也说明了数组和指针并不是完全等同的。这样使用肯定是错误的,代码不可能正常运行。那么应该怎么声明呢, 如下:
Extern int mango【】;/*②*/
说明: ①语句声明mango是个int*型;②声明mango为int 型数组,长度尚未确定,其存储在别处定义。
1 那么什么是声明?什么是定义?
在C语言中对象必须有且只有一个定义,但可以有多个声明。定义是一个特殊的声明,它创建一个对象;声明只是说明了在其他地方创建了这个对象,它允许在这里使用:
*******************************************************************************
定义 只能出现在一个地方 确定对象的类型并分配内存,用于创建新的对象
声明 可以多次出现 描述对象的类型,用于指代其他地方定义的对象
*******************************************************************************
只要记住下面的内容可以分清定义和声明:
声明相当于普通的声明:它说明的并非自身,而是描述其他的地方创建的对象。
定义相当于特殊的声明:它为对象分配内存。
Extern 对象声明告诉编译器对象的类型和名字,对象的内存分配在别处进行。由于并未在声明中为数组分配内存,所以并不需要提供关于数组长度的信息。对于多维数组需要提供除最左边一维其他维的长度—这是给编译器足够的信息产生相应的代码。
2 、数组和指针式如何访问的
这里讲述对数组的引用和对指针的引用有何不同之处,首先需要注意的是“地址y“和“地址y的内容”之间的区别。这里一个相当微妙之处,是在大多数编程语音中我们用同一个符号来表示这两个东西,有编译器根据上下文环境来判断他的具体含义。以一个简洁的例子来说明:

出现在赋值符左边的符号有事被称为左值(由于它位于“左手边”或“表示地点”),出现在赋值符右边的符号有时则被称为右值(由于它位于右手边)。编译器为每个变量分配一个地址(左值),这个地址在编译时可知,而且该变量在运行时一直保存于这个地址。相反,存储于变量中的值(右值)只有在运行时才知。如果需要用到变量中存储的数值,编译器就发出质量从指定地址读取变量并将它存储在寄存器中。
这也是为什么在if(-1 == x)判断语句中,如果将“==”误写为“=”编译器会报警的原因(相信很多人只知道这么用,不知道为什么吧?)
这里的关键在于每个符号在编译时可知。所以如果编译器需要一个地址(可能还需要加上偏移量)来执行某种操作。它可以直接进行操作,并不需要增加指令首先取得具体的地址,相反对于指针在运行时首先取得它的当前值,然后才能对它进行接触引用操作。具体看下图:

这也是为什么extern char a[] 与 extern char a[100]等价的原因。这两个都说明a是个数组,也就是个内存地址,数组内的字符可以从这个地址中找到。编译器并不需要知道这个地址有多长,因为它只产生偏离起始地址的偏移地址。从数据中提取一个数值,只需要简单的知道现实a的地址加上下标,需要的字符就位于这个地址中。
相反,如果声明extern char *p,它告诉编译器P是个指针,它指向的是一个字符。为了取得这个字符,必须知道P的内容,把他作为字符的地址取其内容就是这个字符,指针的访问比较灵活,但需要增加一次额外的提取。

定义成指针,但以数组方式引用
现在让我看下定义成指针,当以数组方式引用会发生什么,看下面的例子:

对照图C的访问方式
Char *p = “abcdefgh“; ... p[3]
和图A的访问方式:
Char a[] = “abcdefgh”; .... a[3]
在这两种情况下,都可以取得字符‘d’,但是两者的途径是不一样的。
当书写了 extern char *p,然后用p【3】来引用其中的元素时,其实质是图A和图B的访问方式的组合。首先,进行图B所示的间接引用。然后,如图A所示用下标作为偏移量进行直接访问。更为正式的说明是,编译器将会:
1. 取得符号P的地址,提取存储于此处的指针。
2. 把下标所表示的偏移量与指针的值相加,产生一个地址。
3. 访问上面的地址,取得数值。
到这也许已经知道为什么文章开头举得例子中文件2中声明Extern int *mango; /*①*/
为什么会出现编译失败的问题?既然把P声明成指针,那么不管P原先定义为指针还是数组,都会按照上面所示的三个步骤进行操作,但是只有当P原来定义成指针时,上面这个方法才是正确的。考虑上面那个问题。当用mango【i】这种形式提取这个声明的内容时,实际上得到是一个字符,按照上面的方法,编译器却把它当成一个指针,把ACSII字符当作成地址显然是错误的。
数组和指针的区别:
NO |
指针 |
数组 |
1 |
保存数据的地址 |
保存数据 |
2 |
简洁访问数据。首先取得指针的内容,把它当成地址,然后从这个地址取提取数据。如果指针有一个下标【i】,那么就把指针的内用加上i的地址,从中提取数据 |
直接访问数据。A【i】只是简单地以a+i为地址取得数组。 |
3 |
通常用于动态内存分配 |
通常用于固定数目其数据类型相同的元素 |
4 |
相关函数malloc()和free() |
隐身分配和删除 |
5 |
通常指匿名数据 |
自身即为数据名 |
再议数组:
1、 什么时候数组和指针相同
在实际的运用过程中,数组和指针互换的情景比两者不可互换的情形更为常见,让我们分别来考虑“声明”和“使用”两种情况。
声明本来还可以分为3中情况:
Ø 外部数组的声明;
Ø 数组的定义(记住,定义是声明的一种特殊情况,它分配内存空间,并提供一个初始值);
Ø 函数参数的声明。
所有作为函数参数的数组名总是可以通过编译器转换为指针。在其他情况下,数组的声明就是数组,指针的声明就是指针,两者不能混淆。但是在使用数组时,数组总是可以写成指针的形式,两者可以互换。下面是总结:

为什么会发生混淆
当人们学习编程时,一开始总是把所有的代码都放在一个函数里。随着水平的进步,他们把代码分别放在几个函数中,在水平继续提高后,他们最终学会了如何用几个文件来构造个程序。在这个过程中,他们可以看到大量的作为函数参数的数组和指针,在这种情况下,他们是完全可以互换的,如下所示:
char my_array[10];
char *my_ptr;
...
i = strlen(my_array);
j = strlen(my_ptr);
printf("%s,%s",my_array,my_ptr);
上面清晰地展示了数组和指针的课互换性,人们很容易忽视这只是放生在一种特定的上下文环境中,也就是说作为一个函数调用的参数使用。更糟的是它可以如下编写:
printf("array at location %x holds string %s",a,a);
在同一个语句中,即把数组名作为一个地址(指针),有把他作为一个字符数组。
在C标准中对“什么时候数组和指针时相同的”作了如下的声明:
规则1:表达式中的数组名(与声明不同)被编译器当做一个指向该数组第一个元素的指针。
规则2:下标总是与指针的偏移量相同。
规则3:在函数参数声明中,数组名悲编译器当做指向该数组第一个元素的指针
下面详细介绍这3个规则的含义:
规则1:“表达式数组名”就是指针
上面的规则1,2一起理解,就是对数组下标的引用总是可以写成“一个指向数组的起始地址的指针加上偏移量”。例如,假如我们声明:
int a[10],
*p,
i = 2;
/*我们可以通过下面集中方法访问a[i]*/
p = a;
p[i];
/*****************/
p = a;
*(p + i);
/******************/
p = a + i;
*p;
应该还有很多方法。对数组的引用如a[i]在编译时总是被编译器改写成*(a+i)的形式,C语言要求编译器必须具备这个概念性的行为。取指针或者数组名+方括号【】中的下标 就是访问元素的地址,再取其值。所以,你也记住,在表达式中,指针和数组时可以互换的,因为他们在编译器的最终都是以指针的形式。因此我们也可以理解下面的取值的表示方法为什么相同了并都是正确的。
a[6] = ......; 6[a] = .....;
规则2:C语言把数组下标作为指针的偏移量
我们通常认为:在编写数组算法时,使用指针比数组 更效率 。这种说法在通常情况下是错误的。在一维数组和指针引用所产生的代码并不具有显著的差别。这里可以参考前面的内容,自己在研究下。
规则3:作为函数参数的数组名等同于指针
| 术语 | 定义 | 例子 |
| 形参(parameter) | 他是一个变量,在函数定义或声明的原型 中定义。又称形式参数 |
int power(int base;int n); base,n都是形参 |
| 实参(argument) | 在函数实际调用过程中传递给函数的值。 | I = power(10,2); 10和2是实参, |
在标准中规定,类型的数组 的形参的声明应该调整为 类型的指针。下面三种写法都是一样的
my_function (int *a); my_function (int a[]); my_function (int a[200]);
数组形参是如何被引用的?
下图展示了对一个下标形式的数组形参进行访问所需要的几个步骤:

注意:有一种操作只能在指针里进行而无法在数组中进行,那就是修改它的值。数组名是不可修改的左值,它的值是不能改变的。
***********************************************************************************************************************************************************************
错误1 :定义数组,声明指针
文件 1 中定义如下:
chara[100];
文件 2 中声明如下:
externchar*a;
这里,文件 1 中定义了数组 a,文件 2 中声明它为指针。这有什么问题吗?平时不是总说数组与指针相似,甚至可以通用吗?但是,很不幸,这是错误的。通过上面的分析我们也能明白一些,但是“革命尚未成功,同志仍需努力” 。你或许还记得我上面说过的话:数组就是数组,指针就是指针,它们是完全不同的两码事!他们之间没有任何关系,只是经常穿着相似的衣服来迷惑你罢了。
下面就来分析分析这个问题:
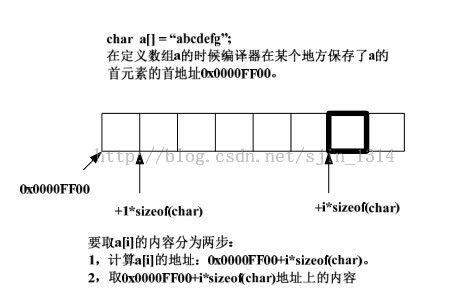
extern char * a;

错误2:定义指针,声明数组:
显然, 按照上面的分析, 我们把文件 1 中定义的数组在文件 2 中声明为指针会发生错误。同样的,如果在文件 1 中定义为指针,而在文件中声明为数组也会发生错误:
文件 1
char*p = “abcdefg”;
文件 2
extern charp[];
在文件 1 中, 编译器分配 4 个 byte 空间, 并命名为 p。 同时 p 里保存了字符串常量 “abcdefg”的首字符的首地址。这个字符串常量本身保存在内存的静态区,其内容不可更改。在文件 2中,编译器认为 p 是一个数组,其大小为 4 个 byte,数组内保存的是 char 类型的数据。在文件 2 中使用 p 的过程如下图:
