参考网站:http://www.cnblogs.com/morewindows/category/314533.html
什么情况下需要排序?其实很多的情况下,是否使用排序是一个重要的策略问题。很早以前人们使用排序,多数情况下是希望能够使用二分查找在logn的时间内取得想要的数据。乱序的情况下,只能使用顺序查找,需要n的时间才能够完成,平均情况下也是n/2,与logn差距太大。于是排序+二分查找成为了早期程序员的数据管理标准配置。但是随着算法理论的推进。现在的情况发生了相当巨大的变化。正如《孙子兵法》中阐述的那样,战争的最高境界是【不战而屈人之兵】,那么排序的最高境界就是【不排】。
1.【如果仅仅是为了取得数据方便】,那么Hash才是最佳的选择,因为如果使用好的解决Hash冲突方法,能够做到1+a/2时间内取得数据,其中a为Hash表的填装因子。这远远好于二分查找带给你的logn时间复杂度。当然,你别想在Hash表找最大值,最小值,或者最大的10个数之类的问题,如果你需要这些操作,Hash不应该是你的选择。但通常情况下,人们存放用户数据的时候,往往关心的是如何取出而已。这种单纯的存取关系下,Hash绝对是最好的选择!
2.【非重复关键字数据】,其实现实生活中这种情况是非常多见的,例如电话号码、身份证数据,他们往往可以成为关键字,而且排序往往是有意义的。如电话号码中0826可能是某个特定的地区,身份证511可能有特定的含义,对这些数据的如果是有序的,往往可以从中取得有用的信息。但是,这些数据真的需要排序吗?在《编程珠玑》中记载了这样一个案例,Boss需要程序员在一台老机子上对1,000,000条电话号码进行排序,要求不超过0.5秒就要完成,可用的内存为1M。问题来了?一来是,那个年代的老机子,1百万条数据,0.5秒排完,即使是快速排序都不可能。二者是,1M内存,就算电话号码是integer都存不下1百万条。面对这样的一个难题,作者是如何解决的呢?答案是根本不排序!首先,使用bit表示电话号码,比如有个电话是 000 000 03 那么就是第3个bit为1,相应的没有电话号码时为0,后面类推。其次,在读取数据放到内存的过程中,电话号码,就能够做到已经有序了,因为 100 100 10 一定是存放在 100 100 11前面的,这样就是天然有序的,所以完全不需要排序了!而我们的程序中,其时有非常多的情况下是非重复关键字的,这种情况下,是可以有更好的解决方案的,不是吗?
3.【大规模频繁变更数据排序】,有时候我们存了相当大规模的数据, 而且随时可能有新的数据插入进来,或者旧的数据需要更新值,而我们又需要这个数据集是有序的,于是我们会经常调用排序算法来排序。这个大规模数据的情况下,性能往往是关键而敏感的,于是我们开始疯狂的优化排序算法。我们开始尝试各种混合优化排序方法,以期能够提升整个程序的性能。但是这样的工作真的是可取的吗?这样的大规模数据情况下,使用树这样的结构其实往往是更加科学的选择。因为诸如红黑树一类的高级树形结构往往能够在插入的过程中保持树本身的性质,而不需要调用排序算法。这种自动排序结构比优化排序算法更能从本质上改成程序的效率。
说了这么多,但很多时候我们还是需要一个高效的排序算法的,至少在我们不明确需求情况下,我们有可用的解决方案,也许以后可用找到更加特定的方案,但我们需要先将一个程序跑起来不是?那么先来看看我们有些什么排序算法:

![]()
上图传说是来自《大话数据结构》一书,但我没看过,这里借来引用特此说明。总体说来,我们有四大类排序算法:插入、选择、交换、合并。这是根据这些算法的基本操作来分类的。其实这上述的算法都是基于“比较”的算法,还有一类特殊的算法是基数排序。基于“比较”的算法,算法理论证明至少需要“log(n!)上取整”次比较,而基数排序可以做到线性时间排序。但是基数排序在实践中并没有很好的表现,而且实现起来比较复杂,所以一直很少应用于实际编程。而我们这里讨论的也主要是“比较”排序。下面先来初看下这些“比较”排序的特征:
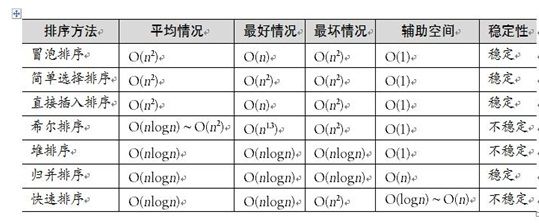
上表同样据说来自《大话数据结构》,特此说明。我们可以看出,最主要的平均时间复杂度上,n² 和 nlogn是两个重要的分水岭。通常n² 复杂度得排序算法被称为简单排序算法,因为通常能够比较简单地编写出来。而nlogn级的排序算法,被称为高级排序算法,因为通常需要一定算法基础的程序员才能够编写。下面我们来一一分析, 前奏:引入一个简单的操作函数,交换swap,功能是交换传入的两个值,这个简单的操作可以方便后面的程序编码:
inline void swap(int &a,int &b)
{
a = a^b;
b = a^b;
a = a^b;
};
上面的
^
是
异或
操作,这个交换实现是一种不使用中间变量进行交换的
hack code
,娱乐性质和实用性质都有一点儿。
1.冒泡排序
void bubblesort(int *arr,int n)
{
for( int i=0; i<n; ++i)
{
for(int j=0; j<n-1-i; ++j)
{
if( arr[j] > arr[j+1] )
swap(arr[j],arr[j+1]);
}
}
}
这个版本的冒泡排序是正统的实现方式,其实可以实现地更加简洁好看一点儿:
void bubblesort(int *arr,int n)
{
for( int i=0; i<n; ++i)
for(int j=0; j<n-1-i; ++j)
if( arr[j] > arr[j+1] )
swap(arr[j],arr[j+1]);
}
是不是很有层次感,是我最喜欢的风格,也许是受python的影响吧,我觉得短代码时,不要括号更加具有可读性。所以在C语言编程时,在短代码情况下,我也会偶尔这样去掉括号来增强可读性和层次感。冒泡排序应该是大家比较熟悉的,其特点如下:
(1)稳定的,即如果有 [...,5,5...]这样的序列,排完序后,这两个5的顺序一定不会改变,这在一般情况下是没有意义的,但当 5这个节点不仅仅是一个数值,是一个结构体或者类实例,而结构体有附带数据的时候,这两个节点的顺序往往是有意义的,如果能够稳定有时候是关键的,因为如果不稳定则可能破坏附带数据的顺序结构。
(2)比较次数恒定,总是比较 n²/2次,哪怕数据已经完全有序了
(3)最好的情况下,一个数据也不用移动,冒泡排序的最好情况是:【数据已经有序】
(4)最坏的情况下,移动 n²/2次数据,冒泡排序的最坏情况是:【数据是逆序的】。
需要说明的是的 n²/2 这个结果是:1+2+3+...+n-1 = n(n-1)/2,等差数列求和得到。
冒泡排序的思想:在冒泡的过程中,关键字较小的记录好比水中的气泡逐趟往上漂浮,而关键字较大的记录好比石块往下沉,每一趟有一块“最大”(而非最小)的石头沉到水底。思考,能否每趟让其最小的往上跑从而达到排序的目的?
for (int i=0;i<len-1;++i)//改动的冒泡排序:每趟排序后将最小的元素挑选出并放到适合的位置
for (int j=len-1;j>i&&j>=1;--j)
if(ia[j]<ia[j-1])
swap(ia[j],ia[j-1]);
2.简单选择排序
// selectSort.cpp : 定义控制台应用程序的入口点。
#include "stdafx.h"
#include<iostream>
using namespace std;
const int SIZE=10;
int _tmain(int argc, _TCHAR* argv[])
{
int temp;
int ia[SIZE]={8,6,1,7,9,2,5,3,4,0};
for (int i=0;i<SIZE;++i)
{
temp=ia[i];
for(int j=i;j<SIZE;++j)
{
if (ia[j]<temp)
{
temp=ia[j];
swap(ia[i],ia[j]);
}
}
}
/*for (int i=0;i<SIZE;++i)
{
temp=ia[i];
for (int j=i+1;j<SIZE;++j)
if (temp>ia[j])
swap(temp,ia[j]);
ia[i]=temp;
}*/
for (int i=0;i<SIZE;++i)
cout<<ia[i]<<" ";
cout<<endl;
system("pause");
return 0;
}
3.直接插入排序
// 直接插入排序需要一个额外的辅助空间,冒泡排序则无需。
#include "stdafx.h"
#include "shellSort.cpp"
#include<iostream>
using namespace std;
const int SIZE=10;
int _tmain(int argc, _TCHAR* argv[])
{
int temp,j;
int ia[SIZE]={8,6,1,7,9,2,5,3,4,0};
/*for (int i=1;i<SIZE;++i)
{
temp=ia[i];
for( j=i-1;j>=0;--j)
{
if (ia[j]>temp)
ia[j+1]=ia[j];
else
break;
}
ia[j+1]=temp;
}*/
/*for (int i=1;i<SIZE;++i)
{
int j=i-1;
for (;j>=0&&ia[i]<ia[j];--j)
ia[j+1]=ia[j];//这一句会将后面的ia[i]给覆盖掉;所以需要额外的一个辅助空间保存原先的值
ia[j+1]=ia[i];
}*/
/*for(int i=1; i<SIZE; ++i)
{
int temp = ia[i];
int j = i-1;
for(; j>=0 && temp<ia[j] ; --j)
ia[j+1] = ia[j];
ia[j+1] = temp;
} */
for (int i=0;i<SIZE;++i)
cout<<ia[i]<<" ";
cout<<endl;
system("pause");
return 0;
}
直接插入排序,是一种十分有用的简单排序算法,由于其一些优秀的特性,在高级排序中往往会混合直接插入排序,那么我们就来详细看看,直接插入排序的特点:
(1)稳定的,这点不多做解释,参见冒泡排序的说明
(2)最好情况下,只做 n-1次比较,不做任何移动,比如 [ 1, 2, 3, 4, 5 ]这个序列,算法a.检查2能否插入1前==>不能;b.检查3能否插入到2前==>不能;...以此类推,只需做完 n-1 次比较就完成排序,0次移动数据操作。直接插入排序的最好情况是【数据完全有序】
(3)最坏情况下,做 n²/2次比较,做 n²/2 次移动数据操作,比如 [ 5, 4, 3, 2, 1 ]这个序列,4需要插入到5前,3需要插入到4,5前,...1需要插入到2,3,4,5前,同样由等差数列求和公式,可得比较次数和移动次数都是n(n-1)/2,简记为n²/2。直接插入排序的最好情况是【数据完全逆序】
(4)有人说直接插入排序是在序列越有序表现越好,数据越逆序表现越差,其实这种说法是错误的。举个例子说明,序列a [ 6,1,2,3,4,0 ],数据其实已经基本有序,只是0,6的位置不对,简单0,6交换即可得到正确序列,但插入排序会把 1,2,3,4以此插入到6前,在把0插入到1,2,3,4,6前,几乎有2n次移动操作。可见直接插入排序要想达到高效率,要求的有序不是基本有序,而前半部分完全有序,只有尾部有部分数据无序,例如 [0,1,2,3,4,5,5,6,7,8,9,........,107,99,96,101] 对这样一个只有尾部有部分数据无序,且尾部数据不会干扰到序列首部的 [0,1,2,3,4....]的位置时,直接插入排序是其他任何算法都无法匹敌的。
注意:在该排序中需要一个额外的辅助空间来预先保存后面的元素,防止在后移动的过程中被前面的给覆盖掉:int temp = arr[i];
以上三种简单排序算法中,时间复杂度均是n² ,但是冒泡排序中不需要额外的空间,其他的两个均需要一个额外的空间来暂存数据,所以我还是更倾向冒泡。
4.希尔排序
这是一个神奇的排序,shell排序起初的设计目的就是改进直接插入排序(另外有一种二分插入排序也是对直接插入排序的改进),因为直接插入排序在诸如 [ 6,1,2,3,4,5,0 ] 这样的基本有序数列上表现不佳,人们设想是不是可以让插入的步长更大一些,比如步长为3,则相当于将序列分组为 [ 6,3 ,0 ] [1,4 ][ 2,5 ]这样三个子序列进行插入排序,这样[ 6,3,0 ] 一组可以很快地变换到 [ 0,3,6 ]于是整个序列都很快有序了。
#include "stdafx.h"
#include<iostream>
using namespace std;
const int SIZE=10;
const int dltalen=9;
void shellSort(int ia[],int size);
int _tmain(int argc, _TCHAR* argv[])
{
int temp,j;
int ia[SIZE]={8,6,1,7,9,2,5,3,4,0};
//int ia[SIZE]={49,38,65,97,76,13,27,49};
shellSort(ia,SIZE);
for (int i=0;i<SIZE;++i)
cout<<ia[i]<<" ";
cout<<endl;
system("pause");
return 0;
}
void shellSort(int ia[],int size)
{
int iNum=size,temp;
while(iNum>1)
{
iNum=(iNum+1)/2;
for(int i=iNum;i<size;++i)
if(ia[i]<ia[i-iNum])
{
temp=ia[i];
int k=i-iNum;
for (;k>=0 && ia[k]>temp;k-=iNum)
ia[k+iNum]=ia[k];
ia[k+iNum]=temp;
}
}
}
//void shellSort(int ia[],int size)
//{
// int temp;
// int dlta[dltalen] = {1750,701,301,132,57,23,10,4,1};
// for (int i = 0; i < dltalen; i++)//排序的趟数
// {
// int dk=dlta[i];
// for (int j = dk; j < size; j++)
// {
// temp=ia[j];
// int k=j-dk;
// for (; k>=0&&ia[k]>temp; k-=dk)//记录后移,查找插入的位置
// ia[k+dk]=ia[k];
// ia[k+dk]=temp;
// }
// }
//}
希尔排序最有趣的地方在于她的步长序列选择上,步长序列选择的好坏直接决定了算法的效率,这也是为什么希尔排序效率是一个n²/2 ~nlog²n的原因,纠正一下传说来自《大话数据结构》的表中将希尔排序记作了n²/2 ~nlogn,这是不对的,目前的理论研究证明的希尔排序最好效率是nlog²n,这个logn上的平方是不能少的,差距很大的。上面的希尔排序中使用一个特殊的序列,是Marcin Ciura发布的研究报告中得到的目前已知最好序列,在使用这个特别的步长序列时,希尔排序的效率是nlog²n。那么希尔排序有哪些特点呢?
(1)希尔排序是不稳定的
(2)希尔排序特别适合于,大部分数据基本有序,只有少量数据无序的情况下,如 [ 6,1,2,3,4,5,0 ]希尔排序能迅速定位到无序数据,从而迅速完成排序
(3)希尔排序的步长序列,无论如何选择最后一个必须是1,因为希尔排序的最后一步本质上就是直接插入排序,只是通过前面的步长排序,将序列尽量调整到直接插入排序的最高效状态;希尔排序可以理解为特殊的直接插入排序,区别在于步长的选择上,一个默认的为1,一个是人为设置的。
(4)研究表明优良的步长序列选择下,在中小规模数据排序时,希尔排序是可以快过快速排序的。因为希尔排序的最佳步长下效率是 n*logn*logn*a(非常小常数因子),而快速排序的效率是 n*logn*b(小常数因子),在 n小于一定规模时,logn*a是可能小于b的,比如 a=0.25,b=4,n = 65535;此时logn*a<4,b=4。
5.堆排序(选择排序)
简单排序中,n个关键字中选出最小值,至少进行n-1次比较,然而,继续在剩余的n-1个关键字中选择次小值就并非一定需要进行n-2次比较,若能利用前n-1次比较所得信息,则可以减少以后各趟选择排序中所用的比较次数。堆排序就是基于这种思路进行排序的。
堆排序是由于其最坏情况下nlogn时间复杂度,以及o(1)的空间复杂度而被人们记住的。在数据量巨大的情况下,堆排序的效率在慢慢接近快速排序。下面先看正统的堆排序实现:
#include "stdafx.h"
#include<iostream>
using namespace std;
const int SIZE=5;
#define Max(a,b) a>b?a:b
void heapAdjust(int a[],int index,int size);
void heapSort(int a[],int size);
int main(int argc, char* argv[])
{
//int ia[SIZE]={8,6,1,7,9,2,5,3,4,0};
int ia[SIZE]={5,2,8,4,1};
heapSort(ia,SIZE);
for (int i=0;i<SIZE;++i)
cout<<ia[i]<<" ";
cout<<endl;
system("pause");
return 0;
}
void heapAdjust(int a[],int index,int size)//调整堆
{
int temp = a[index];
for (int i = 2*index+1;i <size; i = 2*index+1)
{
if ((i < size) && a[i] < a[i+1])
i++;
if ( temp > a[i] )
break;
a[index] = a[i];
index = i;
}
a[index]=temp;
}
void buildHeap(int a[],int size) //建立堆
{
for (int i = size/2 - 1; i >= 0; i--)
heapAdjust(a,i,size);
}
void heapSort(int a[],int size)
{
buildHeap(a,size);
for (int i=size - 1;i > 0; i--)
{
swap(a[0],a[i]);
heapAdjust(a,0,i-1);
}
}
代码由两部分组成,heapAdjust的调整 [ low , high ]区间内的元素满足堆性质,代码正确工作的前提条件是只有heap[low]一个元素是不满足堆性质。heapSort第一个for循环是将 [ 0 ,size-1 ]区间内的元素建成一个“大顶堆”。很多人不明白为什么建堆的时候是从 size/2-1开始,到0结束,而显然这个时候 [ size/2, size ]这接近一半的区间都是不满足堆性质的。这是因为这一半的区间在开始的时候不需要满足堆性质,因为你如果把整个堆看做一颗二叉树,那么这一半的区间就一定是树叶,树叶之间不需要满足特定的性质,而重要的是树叶和上层的树枝之间满足堆性质即可,这就是为什么heapAdjust是在 [ size/2-1, 0 ] 这个区间进行的原因。heapSort的第二个for循环是每次从堆顶取出元素,然后重新调整堆。整个排序就是在不断地从堆顶取元素,不断地重新调整堆。
那么现在我们总的来看一下堆排序的特征:
(1)堆排序是不稳定的
(2)堆排序在最坏的情形下都能保证nlogn的时间复杂度,这是因为对于深度为k的堆,调整算法(heapadjust)至多比较2(k-1)次,建立n个元素,深度为h的堆时,总共比较次数不超过4n;另外,n个结点的完全二叉树深度为 [logn]+1,在抽取堆顶,重新调整过程中调用调整算法n-1次,求和的值小于2n[ logn ];总共的比较次数一定小于4n+2n[logn]
(3)堆排序在任何时候都表现出出色的稳定性,这种稳定大概可以这样解释:当遇到基本有序、基本逆序的序列时,堆排序和插入排序、希尔排序表现得接近;当遇到大规模数据的时候,堆排序表现得和快速排序接近。也就是说:在任何某种情形下,堆排序都基本不是表现最好的,但一定和表现最好的算法差距不大,相应地一定远远好于这种情形下表现较差的算法,没有任何序列能够使堆排序进入所谓特别糟糕的情形。堆排序永远是那么稳定,按照你所期望性能运行,永远不是最好,永远都接近最好的算法;如果非要用句话形容堆排序就是:【万年老二】
(4)堆排序的建堆策略是影响性能的一项重要因素,举例说明:你可以使用建立“小顶堆”来完成“降序”排序,你也可以使用建立“大顶堆”来完成“升序”排序;但这两种策略都是极其低效的;你相当于你建立了一个基本逆序的序列,你最后要得到一个顺序的序列。正确的策略应该是“小顶堆”来完成“升序”,“大顶堆”来完成“降序”,注意这种策略的代码不易编写,我上面给出示范代码是“大顶堆”完成“升序”的排序方式,而大部分的教材也采用的是这种较易实现的方式。后续可能补充"大顶堆"完成“降序”的算法。
6.归并排序
还在优化代码,我想写出尽量简单可读高效的代码给大家分享。分析也相应延后。
7.快速排序
快速排序是实践工作中,最常用的一种排序算法了,被普遍认为是一般情况下的最高效算法。
#include "stdafx.h"
#include<iostream>
using namespace std;
const int SIZE=10;
void quickSort(int a[],int size);
void quickSort_recurrence(int a[],int size);
int _tmain(int argc, _TCHAR* argv[])
{
int temp;
int ia[SIZE]={8,6,1,7,9,2,5,3,4,0};
//quickSort(ia,SIZE);
quickSort_recurrence(ia,SIZE);
for (int i=0;i<SIZE;++i)
cout<<ia[i]<<" ";
cout<<endl;
system("pause");
return 0;
}
void quickSort(int a[],int size)//每一趟确定一个位置a[i],使a[i]之前的都比a[i]小,在a[i]之后的都比a[i]大;
{
int temp;
int low =0,high=size-1;
const int stack_deepth = 65536;
int stack[stack_deepth];
int top = 0;
stack[top++] = low;
stack[top++] = high;
while(top!=0)
{
int end=stack[--top];
int start=stack[--top];
low=start;//low与high用于每一趟比较中的游标
high=end;
if (low<high)
{
temp=a[low];//第一趟开始
while(low<high)
{
while(low<high && a[high]>=temp)
high--;
a[low]=a[high];
while(low<high && a[low]<=temp)
low++;
a[high]=a[low];
}
a[low]=temp;//第一趟结束;接下来以a[low]为分界,前后两部分分别进行快速排序
stack[top++]=start;
stack[top++]=low-1;
stack[top++]=low+1;
stack[top++]=end;
}
}
}
void quickSort_recurrence(int a[],int size)
{
if (size>1)//递归结束的条件
{
int low=0;
int high=size-1;
int temp=a[low];
while(low<high)
{
while(low<high && a[high]>=temp)
high--;
a[low]=a[high];
while(low<high && a[low]<=temp)
low++;
a[high]=a[low];
}
a[low]=temp;
quickSort_recurrence(a,low);
quickSort_recurrence(a+low+1,size-low-1);
}
}
快速排序这么受欢迎的究竟是为什么呢?因为快速排序在通常意义下确实是最快的,请不要带之一。人们总是乐于找到最快的算法,人们也常常好奇于第一名是谁,大多数人都对第二名不感兴趣,冠军总是荣耀的,亚军总是默默无闻的。这也是为什么人们通常喜欢讨论“快速排序vs堆排序vs归并排序vs希尔排序”的原因。而他们间的较量结果大致是这样的:中小规模下,希尔排序可能更快(注意可能),大规模下快速排序最快但可能发生最坏情况n²,归并排序可以多线程而且是唯一稳定的高效排序,堆排序可以保证最坏情况下都是nlogn,对了弱弱地提一句,快速排序的最坏情况可能并不是n²的时间复杂度,而是"error:stackover flow",一个明明应该正常工作的排序,在某个时候就莫名地溢栈了,这让人情何以堪啊!下面具体给出快速排序的特征:
(1)快速排序是不稳定的
(2)快速排序在大多数情况下都是最快的
(3)快速排序的最坏情况是:【数据基本有序】【数据基本逆序】,例如[ 1,2,3,4,5,...............,10000 ]这样一个10000个数的有序数列,如果你让快速排序排序的话,那么明确地说,快速排序的递归深度将达到 10000,你能想象10000层嵌套的递归是什么感觉吗?写 if写10000层嵌套都够人崩溃的,更别说 10000层的递归的,程序空间那点可怜的栈空间就这样被压榨得over flow了,所以你的快速排序如果没有保护措施还是不要随便使用。而诸如 [ 10000,9999,.........,3,2,1 ]这样基本逆序的序列也是一样的。明确地说,快速排序如果没有保护措施,就是一个定时Bug,他会在你的程序中,在你做着好梦的某个晚上突然让程序挂掉!
(4)快速排序的优化措施大概分为三类:一、更好地选择中转轴,让划分更加趋近每次都是二分划分;二、递归过程中每次选择先处理短的区间,这样可以将递归深度限制在logn的级别上;或者使用栈模拟递归,灵活设定可允许的递归深度;三、划分过后的小区间交给诸如插入排序这样的算法处理,因为如果一个区间一共就五六个数,还需要递归调用快速排序,快排也变成慢排了。
综合上述,得到的各种情况下的最优排序分别是:
(1)序列完全有序,或者序列只有尾部部分无序,且无序数据都是比较大的值时,【直接插入排序】最佳(哪怕数据量巨大,这种情形下也比其他任何算法快)
(2)数据基本有序,只有少量的无序数据零散分布在序列中时,【希尔排序】最佳
(3)数据基本逆序,或者完全逆序时,【希尔排序】最佳(哪怕是数据量巨大,希尔排序处理逆序数列,始终是最好的,当然三数取中优化的快速排序也工作良好)
(4)数据包含大量重复值,【希尔排序】最佳(来自实验测试,直接插入排序也表现得很好)
(5)数据量比较大或者巨大,单线程排序,且较小几率出现基本有序和基本逆序时,【快速排序】最佳
(6)数据量巨大,单线程排序,且需要保证最坏情形下也工作良好,【堆排序】最佳
(7)数据量巨大,可多线程排序,不在乎空间复杂度时,【归并排序】最佳
当然这些结论是针对基本版本的排序算法,不包含特殊优化技巧的排序版本。例如采用三数取中方法的快速排序在基本有序和基本逆序时表现出和直插、希尔相似的效率。但是这种版本,仍然有其他无数种可能使算法进入最坏状态的序列,三数取中只是消除了其中基本有序、基本逆序的一小部分。直接插入可以优化到二分插入排序或者多路插入排序。希尔排序,将来继续出现什么神奇的序列也是有可能的,研究远远没有结束。
所以,很早人们就意识到,远远没有哪种排序是完美的,所以混合各种排序才是目前研究水平下的真正高效算法。那么如何混合使用这些排序,使得各种排序尽量发挥各自的特长呢?下面就介绍一种经典的混合排序,程序员经常使用的std::sort:
下面简单介绍一下std::sort的实现,因为最近在做一个排序算法,目的就是想要超越std::sort这座大山(目前还未实现这个目标)。这里要纠正两个极端观点:一、std::sort由于是容器算法,所以是低效的;二、std::sort是大牛写的,无法超越。对于第一点,很多人认为std::sort的效率不高,说随便写个冒泡都比std::sort快,理由貌似是std::sort是容器算法,涉及到容器内部判断和容器操作,所以一般比较慢,而且还拿出了测试数据,说明在简单情况下,std::sort还不如冒泡。但是面对这些同志,windows平台下的VC请开到Release版本,谢谢!Linux版本下C程序员一般都认为gcc的std::sort比较高效,所以基本不会出现这种问题。你会惊讶地发现,在简单情况下,想要快过std::sort都是不容易的。对于第二点,std::sort无敌论者们,你们知道std::sort是怎么工作的吗?就毅然决然地说std::sort是无敌的,这是一种盲目地崇拜,永远这样盲目地仰望大牛们,自己不尝试做到更好,那么自己就永远活着大牛的光辉或者阴影下!
分解std::sort,其内部机制可以简单阐述如下:
(1)主控制流程是一个改进的快速排序,称为内省排序(introsort),中转轴采用“三数取中法”,取的是 arrr[ low] arr[ (low+high)/2 ] arr[ high ] 三者的中值
(2)在快速划分区间后,如果区间比较小,那么交给一个改进的插入排序,称为(final_insert_sort)
(3)在递归过程中,有一个deepth参数控制递归深度,如果递归深度过深,算法中限定为 logn,比如子序列长度为 128,那么最多允许递归深度达到 7,如果递归深度达到上限,算法认为这种情况是恶化的递归,为防止快速排序的最坏情况发生,算法自动转为进行堆排序(heapsort),这也是为什么称为内省排序的原因,内省就是内部自我反省的意思。
(4)算法中包含了一些 hack trick来帮助算法更加高效,例如有专门的三数取中函数,(low+high)/2表示为(low+high)>>1等。在VC++中的release版的std::sort甚至可以找到汇编代码。
下面是二分查找(递归与非递归双版本),二分查找的前提条件是待查找序列已有序。
// Binsearch.cpp : 定义控制台应用程序的入口点。
#include "stdafx.h"
#include <iostream>
using namespace std;
int BinSearch(int ia[],int value,int low,int high);
int _tmain(int argc, _TCHAR* argv[])
{
int arr[7]={1,2,3,4,5,6,7};
cout<<BinSearch(arr,5,0,6)<<endl;
return 0;
}
//int BinSearch(int ia[],int value,int low,int high)
//{
// int left,right,mid;
// left=low;
// right=high;
// mid=(left+right)/2;
// if (left<right && value>ia[mid])
// return BinSearch(ia,value,mid+1,right);
// if(left<right && value<ia[mid])
// return BinSearch(ia,value,left,mid-1);
// if(value==ia[mid])
// return mid;
// return -1;
//}
int BinSearch(int ia[],int value,int low,int high)
{
while (low<=high)
{
int mid=(low+high)/2;
if (value==ia[mid])
return mid;
if (value>ia[mid])
low=mid+1;
else
high=mid-1;
}
return -1;
}
桶排序
从《基于比较的排序结构总结 》中我们知道:全依赖“比较”操作的排序算法时间复杂度的一个下界O(N*logN)。但确实存在更快的算法。这些算法并不是不用“比较”操作,也不是想办法将比较操作的次数减少到 logN。而是利用对待排数据的某些限定性假设 ,来避免绝大多数的“比较”操作。桶排序就是这样的原理。
桶排序的基本思想
假设有一组长度为N的待排关键字序列K[1....n]。首先将这个序列划分成M个的子区间(桶) 。然后基于某种映射函数 ,将待排序列的关键字k映射到第i个桶中(即桶数组B的下标 i) ,那么该关键字k就作为B[i]中的元素(每个桶B[i]都是一组大小为N/M的序列)。接着对每个桶B[i]中的所有元素进行比较排序(可以使用快排)。然后依次枚举输出B[0]....B[M]中的全部内容即是一个有序序列。
[桶—关键字]映射函数
bindex=f(key) 其中,bindex 为桶数组B的下标(即第bindex个桶), k为待排序列的关键字。桶排序之所以能够高效,其关键在于这个映射函数,它必须做到:如果关键字k1<k2,那么f(k1)<=f(k2)。也就是说B(i)中的最小数据都要大于B(i-1)中最大数据。很显然,映射函数的确定与数据本身的特点有很大的关系,我们下面举个例子:
假如待排序列K= {49、 38 、 35、 97 、 76、 73 、 27、 49 }。这些数据全部在1—100之间。因此我们定制10个桶,然后确定映射函数f(k)=k/10。则第一个关键字49将定位到第4个桶中(49/10=4)。依次将所有关键字全部堆入桶中,并在每个非空的桶中进行快速排序后得到如下图所示:
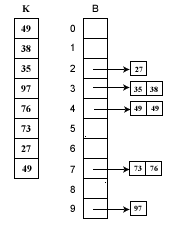
对上图只要顺序输出每个B[i]中的数据就可以得到有序序列了。
桶排序代价分析
桶排序利用函数的映射关系,减少了几乎所有的比较工作。实际上,桶排序的f(k)值的计算,其作用就相当于快排中划分,已经把大量数据分割成了基本有序的数据块(桶)。然后只需要对桶中的少量数据做先进的比较排序即可。
对N个关键字进行桶排序的时间复杂度分为两个部分:
(1) 循环计算每个关键字的桶映射函数,这个时间复杂度是O(N)。
(2) 利用先进的比较排序算法对每个桶内的所有数据进行排序,其时间复杂度为 ∑ O(Ni*logNi) 。其中Ni 为第i个桶的数据量。
很显然,第(2)部分是桶排序性能好坏的决定因素。尽量减少桶内数据的数量是提高效率的唯一办法(因为基于比较排序的最好平均时间复杂度只能达到O(N*logN)了)。因此,我们需要尽量做到下面两点:
(1) 映射函数f(k)能够将N个数据平均的分配到M个桶中,这样每个桶就有[N/M]个数据量。
(2) 尽量的增大桶的数量。极限情况下每个桶只能得到一个数据,这样就完全避开了桶内数据的“比较”排序操作。当然,做到这一点很不容易,数据量巨大的情况下,f(k)函数会使得桶集合的数量巨大,空间浪费严重。这就是一个时间代价和空间代价的权衡问题了。
对于N个待排数据,M个桶,平均每个桶[N/M]个数据的桶排序平均时间复杂度为:
O(N)+O(M*(N/M)*log(N/M))=O(N+N*(logN-logM))=O(N+N*logN-N*logM)
当N=M时,即极限情况下每个桶只有一个数据时。桶排序的最好效率能够达到O(N)。
总结: 桶排序的平均时间复杂度为线性的O(N+C),其中C=N*(logN-logM)。如果相对于同样的N,桶数量M越大,其效率越高,最好的时间复杂度达到O(N)。 当然桶排序的空间复杂度 为O(N+M),如果输入数据非常庞大,而桶的数量也非常多,则空间代价无疑是昂贵的。此外,桶排序是稳定的。
其实我个人还有一个感受:在查找算法中,基于比较的查找算法最好的时间复杂度也是O(logN)。比如折半查找、平衡二叉树、红黑树等。但是Hash表却有O(C)线性级别的查找效率(不冲突情况下查找效率达到O(1))。大家好好体会一下:Hash表的思想和桶排序是不是有一曲同工之妙呢?
桶排序在海量数据中的应用
一年的全国高考考生人数为500 万,分数使用标准分,最低100 ,最高900 ,没有小数,你把这500 万元素的数组排个序。
分析:对500W数据排序,如果基于比较的先进排序,平均比较次数为O(5000000*log5000000)≈1.112亿。但是我们发现,这些数据都有特殊的条件: 100=<score<=900。那么我们就可以考虑桶排序这样一个“投机取巧”的办法、让其在毫秒级别就完成500万排序。
方法:创建801(900-100)个桶。将每个考生的分数丢进f(score)=score-100的桶中。这个过程从头到尾遍历一遍数据只需要500W次。然后根据桶号大小依次将桶中数值输出,即可以得到一个有序的序列。而且可以很容易的得到100分有***人,501分有***人。
实际上,桶排序对数据的条件有特殊要求,如果上面的分数不是从100-900,而是从0-2亿,那么分配2亿个桶显然是不可能的。所以桶排序有其局限性,适合元素值集合并不大的情况。
相关内容参考网络,主要参考:http://blog.csdn.net/theprinceofelf/article/details/6672677
欢迎大家对内容进行修补与批评,谢谢。
桶排序
从《基于比较的排序结构总结 》中我们知道:全依赖“比较”操作的排序算法时间复杂度的一个下界O(N*logN)。但确实存在更快的算法。这些算法并不是不用“比较”操作,也不是想办法将比较操作的次数减少到 logN。而是利用对待排数据的某些限定性假设 ,来避免绝大多数的“比较”操作。桶排序就是这样的原理。
桶排序的基本思想
假设有一组长度为N的待排关键字序列K[1....n]。首先将这个序列划分成M个的子区间(桶) 。然后基于某种映射函数 ,将待排序列的关键字k映射到第i个桶中(即桶数组B的下标 i) ,那么该关键字k就作为B[i]中的元素(每个桶B[i]都是一组大小为N/M的序列)。接着对每个桶B[i]中的所有元素进行比较排序(可以使用快排)。然后依次枚举输出B[0]....B[M]中的全部内容即是一个有序序列。
[桶—关键字]映射函数
bindex=f(key) 其中,bindex 为桶数组B的下标(即第bindex个桶), k为待排序列的关键字。桶排序之所以能够高效,其关键在于这个映射函数,它必须做到:如果关键字k1<k2,那么f(k1)<=f(k2)。也就是说B(i)中的最小数据都要大于B(i-1)中最大数据。很显然,映射函数的确定与数据本身的特点有很大的关系,我们下面举个例子:
假如待排序列K= {49、 38 、 35、 97 、 76、 73 、 27、 49 }。这些数据全部在1—100之间。因此我们定制10个桶,然后确定映射函数f(k)=k/10。则第一个关键字49将定位到第4个桶中(49/10=4)。依次将所有关键字全部堆入桶中,并在每个非空的桶中进行快速排序后得到如下图所示:
对上图只要顺序输出每个B[i]中的数据就可以得到有序序列了。
桶排序代价分析
桶排序利用函数的映射关系,减少了几乎所有的比较工作。实际上,桶排序的f(k)值的计算,其作用就相当于快排中划分,已经把大量数据分割成了基本有序的数据块(桶)。然后只需要对桶中的少量数据做先进的比较排序即可。
对N个关键字进行桶排序的时间复杂度分为两个部分:
(1) 循环计算每个关键字的桶映射函数,这个时间复杂度是O(N)。
(2) 利用先进的比较排序算法对每个桶内的所有数据进行排序,其时间复杂度为 ∑ O(Ni*logNi) 。其中Ni 为第i个桶的数据量。
很显然,第(2)部分是桶排序性能好坏的决定因素。尽量减少桶内数据的数量是提高效率的唯一办法(因为基于比较排序的最好平均时间复杂度只能达到O(N*logN)了)。因此,我们需要尽量做到下面两点:
(1) 映射函数f(k)能够将N个数据平均的分配到M个桶中,这样每个桶就有[N/M]个数据量。
(2) 尽量的增大桶的数量。极限情况下每个桶只能得到一个数据,这样就完全避开了桶内数据的“比较”排序操作。当然,做到这一点很不容易,数据量巨大的情况下,f(k)函数会使得桶集合的数量巨大,空间浪费严重。这就是一个时间代价和空间代价的权衡问题了。
对于N个待排数据,M个桶,平均每个桶[N/M]个数据的桶排序平均时间复杂度为:
O(N)+O(M*(N/M)*log(N/M))=O(N+N*(logN-logM))=O(N+N*logN-N*logM)
当N=M时,即极限情况下每个桶只有一个数据时。桶排序的最好效率能够达到O(N)。
总结: 桶排序的平均时间复杂度为线性的O(N+C),其中C=N*(logN-logM)。如果相对于同样的N,桶数量M越大,其效率越高,最好的时间复杂度达到O(N)。 当然桶排序的空间复杂度 为O(N+M),如果输入数据非常庞大,而桶的数量也非常多,则空间代价无疑是昂贵的。此外,桶排序是稳定的。
其实我个人还有一个感受:在查找算法中,基于比较的查找算法最好的时间复杂度也是O(logN)。比如折半查找、平衡二叉树、红黑树等。但是Hash表却有O(C)线性级别的查找效率(不冲突情况下查找效率达到O(1))。大家好好体会一下:Hash表的思想和桶排序是不是有一曲同工之妙呢?
桶排序在海量数据中的应用
一年的全国高考考生人数为500 万,分数使用标准分,最低100 ,最高900 ,没有小数,你把这500 万元素的数组排个序。
分析:对500W数据排序,如果基于比较的先进排序,平均比较次数为O(5000000*log5000000)≈1.112亿。但是我们发现,这些数据都有特殊的条件: 100=<score<=900。那么我们就可以考虑桶排序这样一个“投机取巧”的办法、让其在毫秒级别就完成500万排序。
方法:创建801(900-100)个桶。将每个考生的分数丢进f(score)=score-100的桶中。这个过程从头到尾遍历一遍数据只需要500W次。然后根据桶号大小依次将桶中数值输出,即可以得到一个有序的序列。而且可以很容易的得到100分有***人,501分有***人。
实际上,桶排序对数据的条件有特殊要求,如果上面的分数不是从100-900,而是从0-2亿,那么分配2亿个桶显然是不可能的。所以桶排序有其局限性,适合元素值集合并不大的情况。
#include<iostream.h>
#include<malloc.h>
typedef struct node{
int key;
struct node * next;
}KeyNode;
void inc_sort(int keys[],int size,int bucket_size){
KeyNode **bucket_table=(KeyNode **)malloc(bucket_size*sizeof(KeyNode *));
for(int i=0;i<bucket_size;i++){
bucket_table[i]=(KeyNode *)malloc(sizeof(KeyNode));
bucket_table[i]->key=0; //记录当前桶中的数据量
bucket_table[i]->next=NULL;
}
for(int j=0;j<size;j++){
KeyNode *node=(KeyNode *)malloc(sizeof(KeyNode));
node->key=keys[j];
node->next=NULL;
//映射函数计算桶号
int index=keys[j]/10;
//初始化P成为桶中数据链表的头指针
KeyNode *p=bucket_table[index];
//该桶中还没有数据
if(p->key==0){
bucket_table[index]->next=node;
(bucket_table[index]->key)++;
}else{
//链表结构的插入排序
while(p->next!=NULL&&p->next->key<=node->key)
p=p->next;
node->next=p->next;
p->next=node;
(bucket_table[index]->key)++;
}
}
//打印结果
for(int b=0;b<bucket_size;b++)
for(KeyNode *k=bucket_table[b]->next; k!=NULL; k=k->next)
cout<<k->key<<" ";
cout<<endl;
}
void main(){
int raw[]={49,38,65,97,76,13,27,49};
int size=sizeof(raw)/sizeof(int);
inc_sort(raw,size,10);
}
上面源代码的桶内数据排序,我们使用了基于单链表的直接插入排序算法。可以使用基于双向链表的快排算法提高效率。
http://hi.baidu.com/zealot886/item/f5f4ccadb57d66a428ce9d76