数据挖掘学习笔记之人工神经网络(二)
多层网络和反向传播算法
我们知道单个感知器仅能表示线性决策面。然而我们可以将许多的类似感知器的模型按照层次结构连接起来,这样就能表现出非线性决策的边界了,这也叫做多层感知器,重要的是怎么样学习多层感知器,这个问题有两个方面:
1、 要学习网络结构;
2、 要学习连接权值
对于一个给定的网络有一个相当简单的算法来决定权值,这个算法叫做反向传播算法。反向传播算法所学习的多层网络能够表示种类繁多的非线性曲面。
可微阈值函数
现在我们来学习一点反向传播算法的基础,这个主要就是sigmoid函数以及可微阈值单元。
应该使用什么类型的单元来作为构建多层网络的基础?起初我们可以尝试选择前面讨论的线性单元,因为我们已经为这种单元导出了一个梯度下降学习法则。然而,多个线性单元的连接仍旧产生线性函数,而我们更希望选择能够表征非线性函数的网络。
感知器单元是另一种选择,但它的不连续阈值使它不可微,所以不适合梯度下降算法。我们所需要的是这样的单元,它的输出是输入的非线性函数,并且输出是输入的可微函数。一种答案是sigmoid单元(sigmoid unit),这是一种非常类似于感知器的单元,但它基于一个平滑的可微阈值函数。
下图是sigmoid单元,与感知器相似,sigmoid单元先计算它的输入的线性组合,然后应用一个阈值到此结果。然而,对于sigmoid单元,阈值输出是输入的连续函数。
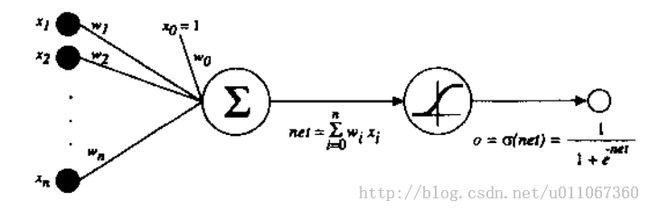
更精确地讲,sigmoid单元这样计算它的输出:
![]()
其中

s经常被称为sigmoid函数或者也可以称为logistic函数(logistic function)。注意它的输出范围为0到1,随输入单调递增(参见图4-6中的阈值函数曲线)。因为这个函数把非常大的输入值域映射到一个小范围的输出,它经常被称为sigmoid单元的挤压函数(squashing function)。sigmoid函数有一个有用的特征,它的导数很容易以它的输出表示,确切地讲就是: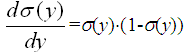
PS:我们再简单的说下这个logistic函数的问题,已知一个固定的网络结构必须要决定何时的网络连接权值,在没有隐藏层的情况下,可以直接用感知器的学习规则来找到合适的值,但是现在假设有隐藏层,但是连接隐藏层的单元的正确输出结果是未知的,因此感知器规则在这里是不适用的。
有一种办法是根据每个单元对最终预测的贡献调整连接隐藏层单元的权值,这个就可以通过梯度下降来解决,但是需要求导数,而简单的感知器使用结束函数来加了全的输入总和转换成了0或者1的预测,阶梯函数不可导,因此必须考虑是否能将及诶函数替换成其他的函数。


从上图可以看出一种阶梯函数可以被s型函数所代替,这个s型函数就是sigmoid单元函数,也就是logistic函数。
反向传播算法
对于由一系列确定的单元互连形成的多层网络,反向传播算法可用来学习这个网络的权值。它采用梯度下降方法试图最小化网络输出值和目标值之间的误差平方。
因为我们要考虑多个输出单元的网络,而不是象以前只考虑单个单元,所以我们先重新定义误差E,以便对所有网络输出的误差求和。
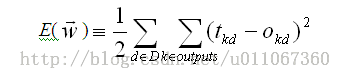
其中outputs是网络输出单元的集合,tkd和okd是与训练样例d和第k个输出单元相关的输出值。
反向传播算法面临的学习问题是搜索一个巨大的假设空间,这个空间由网络中所有单元的所有可能的权值定义。这种情况可以用一个误差曲面来形象表示,与下图1表示的线性单元的误差曲面相似。这幅图中的误差被我们的新的误差定义E所替代,并且空间中的其他维现在对应网络中与所有单元相关的所有权值。和训练单个单元的情况一样,梯度下降可被用来尝试寻找一个假设使E最小化。
多层网络的一个主要不同是它的误差曲面可能有多个局部极小值,而图1表示的抛物曲面仅有一个最小值。不幸的是,这意味着梯度下降仅能保证收敛到局部极小值,而未必得到全局最小的误差。尽管有这个障碍,已经发现对于实践中很多应用反向传播算法都产生了出色的结果。
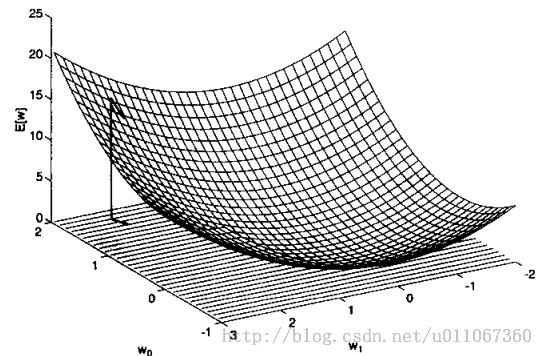
图1
包含两层sigmoid单元的前馈网络的反向传播算法
Backpropagation(training_examples,h, nin,nout, nhidden)
trainning_exaples中每一个训练样例是形式为<,>的序偶,其中是网络输入值向量,是目标输出值。
h是学习速率(例如0.05)。nin是网络输入的数量,nhidden是隐藏层单元数,nout是输出单元数。
从单元i到单元j的输入表示为xji,单元i到单元j的权值表示为wij。
创建具有nin个输入,nhidden个隐藏单元,nout个输出单元的网络
初始化所有的网络权值为小的随机值(例如-0.05和0.05之间的数)
在遇到终止条件前,做
对于训练样例training_examples中的每个<,>,做
把输入沿网络前向传播
1. 把实例输入网络,并计算网络中每个单元u的输出ou。
使误差沿网络反向传播
2. 对于网络的每个输出单元k,计算它的误差项dk
dk <--k(1-ok)(tk-ok)
3. 对于网络的每个隐藏单元h,计算它的误差项dh
dh <--h(1-oh)wkhdk
4. 更新每个网络权值wji
wji<--wji +Dwji
其中
Dwji=hdjxji ( 1)
上面给出了反向传播算法。这里描述的算法适用于包含两层sigmoid单元的分层前馈网络,并且每一层的单元与前一层的所有单元相连。这是反向传播算法的增量梯度下降(或随机梯度下降)版本。这里使用的符号与前一节使用的一样,并进行了如下的扩展:
· 网络中每个结点被赋予一个序号(例如一个整数),这里的结点要么是网络的输入,要么是网络中某个单元的输出。
· xji表示结点i到单元j的输入,并且wji表示对应的权值。
· dn表示与单元n相关联的误差项。它的角色与前面讨论的delta训练法则中的(t-o)相似。后面我们可以看到dn =![]() 。
。
在上面的算法的开始,建立一个具有期望数量的隐单元和输出单元的网络,并初始化所有网络的权值为小的随机数。给定了这个固定的网络结构,算法的主循环就对训练样例进行反复的迭代。对于每一个训练样例,它应用目前的网络到这个样例,计算对于这个样例网络输出的误差,然后更新网络中所有的权值。对这样的梯度下降步骤进行迭代,直到网络的性能达到可接受的精度(经常是上千次,多次使用同样的训练样例)。
和delta法则的比较
这里的梯度下降权更新法则与delta训练法则相似。就象delta法则,它依照以下三者的乘积来更新每一个权:学习速率h、该权值应用的输入值xji、和这个单元输出的误差。惟一的不同是delta法则中的误差项(t-o)被替换成一个更复杂的误差项dj。在4.5.3节的对权更新法则的推导之后我们将给出dj的准确形式。为了直观地理解它,先考虑网络的每一个输出单元k的dk是怎样计算的。很简单,dk与delta法则中的(tk-ok)相似,但乘上了sigmoid挤压函数的导数ok(1-ok)。每个隐藏单元h的dh的值具有相似的形式(算法的公式[T4.4])。然而,因为训练样例仅对网络的输出提供了目标值tk,所以缺少直接的目标值来计算隐藏单元的误差值。因此采取以下间接办法计算隐藏单元的误差项:对受隐藏单元h影响的每一个单元的误差dk进行加权求和,每个误差dk权值为wkh,wkh就是从隐藏单元h到输出单元k的权值。这个权值刻画了隐藏单元h对于输出单元k的误差应“负责”的程度。
增加冲量(Momentum)项
这里我们还讨论一种发现传播算法的变种:增加冲量(Momentum)项
把上面算法的公式(1)换为如下的形式:
Dwji(n)=hdjxji+ aDwji(n – 1)
(主要是为了冲破局部的极小值,可以从一个几步极小值到另外一个局部极小值,有可能找到全部极小值)
这里Dwji(n)是算法主循环中的第n次迭代进行的权值更新,并且0<a<1是一个称为冲量(momentum)的常数。注意这个公式右侧的第一项就是反向传播算法的公式(1)中的权值更新。右边的第二项是新的,被称为冲量项。为了理解这个冲量项的作用,设想梯度下降的搜索轨迹就好像一个(无冲量的)球滚下误差曲面。a的作用是增加冲量使这个球从一次迭代到下一次迭代时以同样的方向滚动。冲量有时会使这个球滚过误差曲面的局部极小值;或使其滚过误差曲面上的平坦区域,如果没有冲量这个球有可能在这个区域停止。它也具有在梯度不变的区域逐渐增大搜索步长的效果,从而可以加快收敛。
ps:概念: 隐藏层表示反向传播算法的一个迷人的特性是,它能够在网络内部的隐藏层发现有用的中间表示。因为训练样例仅包含网络输入和输出,权值调节的过程可以自由地设置权值,来定义在最小化误差平方E中最有效的任何隐藏单元表示。这能够引导反向传播算法定义新的隐藏层特征,这些特征在输入中没有明确表示出来,但却能捕捉输入实例中与学习目标函数最相关的特征。
例如,考虑图4-7所示的网络。这里,8个网络输入与3个隐藏单元相连,3个隐藏单元又依次连接到8个输出单元。由于这样的结构,3个隐藏单元必须重新表示8个输入值,以某种方式捕捉输入的相关特征,以便这个隐藏层的表示可以被输出单元用来计算正确的目标值。
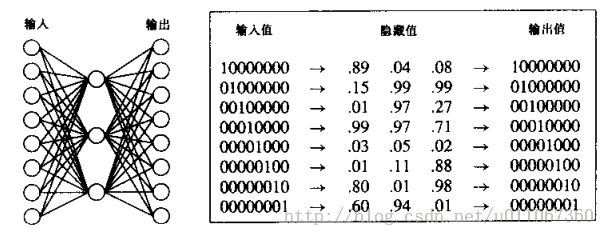
图2
这个8*8*8的网络被训练以学习恒等函数,使用图中所示的8个训练样例。在5000轮(epochs)训练之后,3个隐藏单元使用图右侧的编码方式来编码8个相互不同的输入。注意如果把编码后的值四舍五入为0和1,那么结果是8个不同值的标准二进值编码。
考虑训练图2所示的网络,来学习简单的目标函数f(x)=x,其中是含有七个0和一个1的向量。网络必须学会在8个输出单元重现这8个输入。尽管这是一个简单的函数,但现在限制网络只能使用3个隐单元。所以,学习到的3个隐藏单元必须捕捉住来自8个输入单元的所有关键信息。
当反向传播算法被用来完成这个任务时,使用8个可能向量作为训练样例,它成功地学会了目标函数。梯度下降的反向传播算法产生的隐藏层表示是什么呢?通过分析学习到的网络对于8个可能输入向量产生的隐藏单元的值,可以看出学到的编码和熟知的对8个值使用3位标准二进制编码相同(也就是000,001,010,……,111)。图2显示了反向传播算法的一次运行中计算出的这3个隐藏单元的确切值。
多层网络在隐藏层自动发现有用表示的能力是ANN学习的一个关键特性。与那些仅限于使用人类设计者提供的预定义特征的学习方法相比,它提供了一种相当重要的灵活性——允许学习器创造出设计者没有明确引入的特征。当然这些创造出的特征一定是网络输入的sigmoid单元函数可以计算出的。注意网络中使用的单元层越多,就可以创造出越复杂的特征。