linux内核学习——进程管理
进程就是处于执行期的程序。包括可执行代码和其他资源,如:打开的文件,挂起的信号,内核内部数据,处理器状态,内存映射空间和一个或多个执行线程等。
进程描述符
内核把进程的列表存放在叫做任务队列的双向链表中,链表中的每一项都是类型为task_struct(进程描述符)的结构,该结构定义在<linux/sched.h>文件中。进程描述符包含一个进程的所有信息。其内核定义如下:
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
int lock_depth; /* BKL lock depth */
#ifdef CONFIG_SMP
#ifdef __ARCH_WANT_UNLOCKED_CTXSW
int oncpu;
#endif
#endif
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* list of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
/*
* fpu_counter contains the number of consecutive context switches
* that the FPU is used. If this is over a threshold, the lazy fpu
* saving becomes unlazy to save the trap. This is an unsigned char
* so that after 256 times the counter wraps and the behavior turns
* lazy again; this to deal with bursty apps that only use FPU for
* a short time
*/
unsigned char fpu_counter;
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy;
cpumask_t cpus_allowed;
#ifdef CONFIG_TREE_PREEMPT_RCU
int rcu_read_lock_nesting;
char rcu_read_unlock_special;
struct rcu_node *rcu_blocked_node;
struct list_head rcu_node_entry;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
struct list_head tasks;
struct plist_node pushable_tasks;
struct mm_struct *mm, *active_mm;
/* task state */
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned int personality;
unsigned did_exec:1;
unsigned in_execve:1; /* Tell the LSMs that the process is doing an
* execve */
unsigned in_iowait:1;
/* Revert to default priority/policy when forking */
unsigned sched_reset_on_fork:1;
pid_t pid;
pid_t tgid;
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct *real_parent; /* real parent process */
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
/*
* ptraced is the list of tasks this task is using ptrace on.
* This includes both natural children and PTRACE_ATTACH targets.
* p->ptrace_entry is p's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
/*
* This is the tracer handle for the ptrace BTS extension.
* This field actually belongs to the ptracer task.
*/
struct bts_context *bts;
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
cputime_t prev_utime, prev_stime;
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time; /* monotonic time */
struct timespec real_start_time; /* boot based time */
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
/* process credentials */
const struct cred *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred *cred; /* effective (overridable) subjective task
* credentials (COW) */
struct mutex cred_guard_mutex; /* guard against foreign influences on
* credential calculations
* (notably. ptrace) */
struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock
it with task_lock())
- initialized normally by setup_new_exec */
/* file system info */
int link_count, total_link_count;
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem;
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
/* hung task detection */
unsigned long last_switch_count;
#endif
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespaces */
struct nsproxy *nsproxy;
/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
struct audit_context *audit_context;
#ifdef CONFIG_AUDITSYSCALL
uid_t loginuid;
unsigned int sessionid;
#endif
seccomp_t seccomp;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed,
* mempolicy */
spinlock_t alloc_lock;
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
struct irqaction *irqaction;
#endif
/* Protection of the PI data structures: */
spinlock_t pi_lock;
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task */
struct plist_head pi_waiters;
/* Deadlock detection and priority inheritance handling */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* mutex deadlock detection */
struct mutex_waiter *blocked_on;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsigned int irq_events;
int hardirqs_enabled;
unsigned long hardirq_enable_ip;
unsigned int hardirq_enable_event;
unsigned long hardirq_disable_ip;
unsigned int hardirq_disable_event;
int softirqs_enabled;
unsigned long softirq_disable_ip;
unsigned int softirq_disable_event;
unsigned long softirq_enable_ip;
unsigned int softirq_enable_event;
int hardirq_context;
int softirq_context;
#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
gfp_t lockdep_reclaim_gfp;
#endif
/* journalling filesystem info */
void *journal_info;
/* stacked block device info */
struct bio *bio_list, **bio_tail;
/* VM state */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
unsigned long ptrace_message;
siginfo_t *last_siginfo; /* For ptrace use. */
struct task_io_accounting ioac;
#if defined(CONFIG_TASK_XACCT)
u64 acct_rss_mem1; /* accumulated rss usage */
u64 acct_vm_mem1; /* accumulated virtual memory usage */
cputime_t acct_timexpd; /* stime + utime since last update */
#endif
#ifdef CONFIG_CPUSETS
nodemask_t mems_allowed; /* Protected by alloc_lock */
int cpuset_mem_spread_rotor;
#endif
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock */
struct css_set *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */
struct list_head cg_list;
#endif
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
#endif
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp;
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy; /* Protected by alloc_lock */
short il_next;
#endif
atomic_t fs_excl; /* holding fs exclusive resources */
struct rcu_head rcu;
/*
* cache last used pipe for splice
*/
struct pipe_inode_info *splice_pipe;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
#endif
struct prop_local_single dirties;
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
/*
* time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/
unsigned long timer_slack_ns;
unsigned long default_timer_slack_ns;
struct list_head *scm_work_list;
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored adress in ret_stack */
int curr_ret_stack;
/* Stack of return addresses for return function tracing */
struct ftrace_ret_stack *ret_stack;
/* time stamp for last schedule */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun.
*/
atomic_t trace_overrun;
/* Pause for the tracing */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* state flags for use by tracers */
unsigned long trace;
/* bitmask of trace recursion */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
}
进程状态
linux中的进程状态:
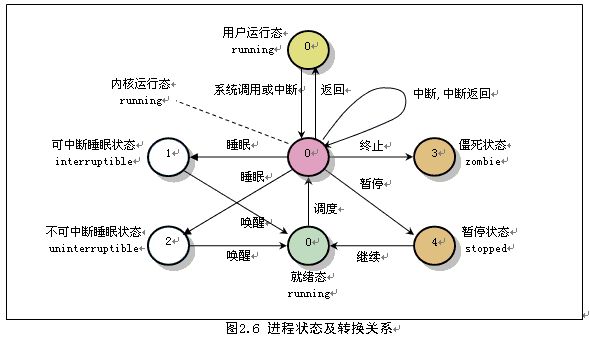
- 运行状态(TASK_RUNNING)
指正在被CPU运行或者就绪的状态。这样的进程被成为runnning进程。运行态的进程可以分为3种情况:内核运行态、用户运行态、就绪态。
- 可中断睡眠状态(TASK_INTERRUPTIBLE)
处于等待状态中的进程,一旦被该进程等待的资源被释放,那么该进程就会进入运行状态。
- 不可中断睡眠状态(TASK_UNINTERRUPTIBLE)
该状态的进程只能用wake_up()函数唤醒。
- 暂停状态(TASK_STOPPED)
当进程收到信号SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU时就会进入暂停状态。可向其发送SIGCONT信号让进程转换到可运行状态。
- 僵死状态(TASK_ZOMBIE)
当进程已经终止运行,但是父进程还没有询问其状态的情况。
注意:
只有当进程从“内核运行态”转移到“睡眠状态”时,内核才会进行进程切换操作。在内核态下运行的进程不能被其它进程抢占,而且一个进程不能改变另一个进程的状态。为了避免进程切换时造成内核数据错误,内核在执行临界区代码时会禁止一切中断。
进程创建
unix进程创建分为两步,由两个不同的函数去完成,fork() 和 exec()。fork()通过拷贝当前进程来创建一个子进程,exec()函数则负责读取可执行文件并将其载入地址空间开始运行。
由于unix强调进程快速执行的能力,所以linux的fork()使用写实拷贝(copy-on-write)页实现。fork()的实际开销就是复制父进程的页表以及给子进程创建唯一的进程描述符,此时内核并不复制整个进程空间,而是让子进程和父进程共享父进程的资源。只有在需要写入的时候,数据才会复制,从而使各个进程拥有各自一份拷贝。这种优化对于fork()之后立即调用exec()的情况来说是很重要的,减少了数据拷贝带来的开销。
linux通过clone()系统调用来实现fork()等进程创建。fork()、vfork()和__clone()库函数都是根据各自需要的标志参数(后面有标志参数表)去调用clone(),clone()调用do_fork()。do_fork()完成了进程创建的大部分工作,它在kernel/fork.c文件中定义。do_fork()调用copy_process()函数(内核2.4.1版本里没有这个函数,直接在do_fork()函数中完成。内核2.6要比2.4复杂很多),然后让进程开始运行。
几种不同方式创建进程中对clone的调用:
fork():
clone(SIGCHLD,0)
vfork():
clone(CLONE_VFORK | CLONE_VM | SIGCHLD,0)
线程创建:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND,0)
linux中线程又称为“轻量级进程”,线程仅仅被视为一个与其他线程共享某些资源的进程。每个线程都有唯一隶属于自己的task_struct,每个线程都被内核视为进程来进行调度。
do_fork()和copy_process()在内核中定义:
/* * Ok, this is the main fork-routine. * * It copies the process, and if successful kick-starts * it and waits for it to finish using the VM if required. */ long do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; /* * Do some preliminary argument and permissions checking before we * actually start allocating stuff */ if (clone_flags & CLONE_NEWUSER) { if (clone_flags & CLONE_THREAD) return -EINVAL; /* hopefully this check will go away when userns support is * complete */ if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID) || !capable(CAP_SETGID)) return -EPERM; } /* * We hope to recycle these flags after 2.6.26 */ if (unlikely(clone_flags & CLONE_STOPPED)) { static int __read_mostly count = 100; if (count > 0 && printk_ratelimit()) { char comm[TASK_COMM_LEN]; count--; printk(KERN_INFO "fork(): process `%s' used deprecated " "clone flags 0x%lx\n", get_task_comm(comm, current), clone_flags & CLONE_STOPPED); } } /* * When called from kernel_thread, don't do user tracing stuff. */ if (likely(user_mode(regs))) trace = tracehook_prepare_clone(clone_flags); p = copy_process(clone_flags, stack_start, regs, stack_size, child_tidptr, NULL, trace); /* * Do this prior waking up the new thread - the thread pointer * might get invalid after that point, if the thread exits quickly. */ if (!IS_ERR(p)) { struct completion vfork; trace_sched_process_fork(current, p); nr = task_pid_vnr(p); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); } audit_finish_fork(p); tracehook_report_clone(regs, clone_flags, nr, p); /* * We set PF_STARTING at creation in case tracing wants to * use this to distinguish a fully live task from one that * hasn't gotten to tracehook_report_clone() yet. Now we * clear it and set the child going. */ p->flags &= ~PF_STARTING; if (unlikely(clone_flags & CLONE_STOPPED)) { /* * We'll start up with an immediate SIGSTOP. */ sigaddset(&p->pending.signal, SIGSTOP); set_tsk_thread_flag(p, TIF_SIGPENDING); __set_task_state(p, TASK_STOPPED); } else { wake_up_new_task(p, clone_flags); } tracehook_report_clone_complete(trace, regs, clone_flags, nr, p); if (clone_flags & CLONE_VFORK) { freezer_do_not_count(); wait_for_completion(&vfork); freezer_count(); tracehook_report_vfork_done(p, nr); } } else { nr = PTR_ERR(p); } return nr; }
/* * This creates a new process as a copy of the old one, * but does not actually start it yet. * * It copies the registers, and all the appropriate * parts of the process environment (as per the clone * flags). The actual kick-off is left to the caller. */ static struct task_struct *copy_process(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *child_tidptr, struct pid *pid, int trace) { int retval; struct task_struct *p; int cgroup_callbacks_done = 0; if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS)) return ERR_PTR(-EINVAL); /* * Thread groups must share signals as well, and detached threads * can only be started up within the thread group. */ if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND)) return ERR_PTR(-EINVAL); /* * Shared signal handlers imply shared VM. By way of the above, * thread groups also imply shared VM. Blocking this case allows * for various simplifications in other code. */ if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM)) return ERR_PTR(-EINVAL); /* * Siblings of global init remain as zombies on exit since they are * not reaped by their parent (swapper). To solve this and to avoid * multi-rooted process trees, prevent global and container-inits * from creating siblings. */ if ((clone_flags & CLONE_PARENT) && current->signal->flags & SIGNAL_UNKILLABLE) return ERR_PTR(-EINVAL); retval = security_task_create(clone_flags); if (retval) goto fork_out; retval = -ENOMEM; p = dup_task_struct(current); if (!p) goto fork_out; ftrace_graph_init_task(p); rt_mutex_init_task(p); #ifdef CONFIG_PROVE_LOCKING DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled); DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled); #endif retval = -EAGAIN; if (atomic_read(&p->real_cred->user->processes) >= p->signal->rlim[RLIMIT_NPROC].rlim_cur) { if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) && p->real_cred->user != INIT_USER) goto bad_fork_free; } retval = copy_creds(p, clone_flags); if (retval < 0) goto bad_fork_free; /* * If multiple threads are within copy_process(), then this check * triggers too late. This doesn't hurt, the check is only there * to stop root fork bombs. */ retval = -EAGAIN; if (nr_threads >= max_threads) goto bad_fork_cleanup_count; if (!try_module_get(task_thread_info(p)->exec_domain->module)) goto bad_fork_cleanup_count; p->did_exec = 0; delayacct_tsk_init(p); /* Must remain after dup_task_struct() */ copy_flags(clone_flags, p); INIT_LIST_HEAD(&p->children); INIT_LIST_HEAD(&p->sibling); rcu_copy_process(p); p->vfork_done = NULL; spin_lock_init(&p->alloc_lock); init_sigpending(&p->pending); p->utime = cputime_zero; p->stime = cputime_zero; p->gtime = cputime_zero; p->utimescaled = cputime_zero; p->stimescaled = cputime_zero; p->prev_utime = cputime_zero; p->prev_stime = cputime_zero; p->default_timer_slack_ns = current->timer_slack_ns; task_io_accounting_init(&p->ioac); acct_clear_integrals(p); posix_cpu_timers_init(p); p->lock_depth = -1; /* -1 = no lock */ do_posix_clock_monotonic_gettime(&p->start_time); p->real_start_time = p->start_time; monotonic_to_bootbased(&p->real_start_time); p->io_context = NULL; p->audit_context = NULL; cgroup_fork(p); #ifdef CONFIG_NUMA p->mempolicy = mpol_dup(p->mempolicy); if (IS_ERR(p->mempolicy)) { retval = PTR_ERR(p->mempolicy); p->mempolicy = NULL; goto bad_fork_cleanup_cgroup; } mpol_fix_fork_child_flag(p); #endif #ifdef CONFIG_TRACE_IRQFLAGS p->irq_events = 0; #ifdef __ARCH_WANT_INTERRUPTS_ON_CTXSW p->hardirqs_enabled = 1; #else p->hardirqs_enabled = 0; #endif p->hardirq_enable_ip = 0; p->hardirq_enable_event = 0; p->hardirq_disable_ip = _THIS_IP_; p->hardirq_disable_event = 0; p->softirqs_enabled = 1; p->softirq_enable_ip = _THIS_IP_; p->softirq_enable_event = 0; p->softirq_disable_ip = 0; p->softirq_disable_event = 0; p->hardirq_context = 0; p->softirq_context = 0; #endif #ifdef CONFIG_LOCKDEP p->lockdep_depth = 0; /* no locks held yet */ p->curr_chain_key = 0; p->lockdep_recursion = 0; #endif #ifdef CONFIG_DEBUG_MUTEXES p->blocked_on = NULL; /* not blocked yet */ #endif p->bts = NULL; /* Perform scheduler related setup. Assign this task to a CPU. */ sched_fork(p, clone_flags); retval = perf_event_init_task(p); if (retval) goto bad_fork_cleanup_policy; if ((retval = audit_alloc(p))) goto bad_fork_cleanup_policy; /* copy all the process information */ if ((retval = copy_semundo(clone_flags, p))) goto bad_fork_cleanup_audit; if ((retval = copy_files(clone_flags, p))) goto bad_fork_cleanup_semundo; if ((retval = copy_fs(clone_flags, p))) goto bad_fork_cleanup_files; if ((retval = copy_sighand(clone_flags, p))) goto bad_fork_cleanup_fs; if ((retval = copy_signal(clone_flags, p))) goto bad_fork_cleanup_sighand; if ((retval = copy_mm(clone_flags, p))) goto bad_fork_cleanup_signal; if ((retval = copy_namespaces(clone_flags, p))) goto bad_fork_cleanup_mm; if ((retval = copy_io(clone_flags, p))) goto bad_fork_cleanup_namespaces; retval = copy_thread(clone_flags, stack_start, stack_size, p, regs); if (retval) goto bad_fork_cleanup_io; if (pid != &init_struct_pid) { retval = -ENOMEM; pid = alloc_pid(p->nsproxy->pid_ns); if (!pid) goto bad_fork_cleanup_io; if (clone_flags & CLONE_NEWPID) { retval = pid_ns_prepare_proc(p->nsproxy->pid_ns); if (retval < 0) goto bad_fork_free_pid; } } p->pid = pid_nr(pid); p->tgid = p->pid; if (clone_flags & CLONE_THREAD) p->tgid = current->tgid; if (current->nsproxy != p->nsproxy) { retval = ns_cgroup_clone(p, pid); if (retval) goto bad_fork_free_pid; } p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL; /* * Clear TID on mm_release()? */ p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr: NULL; #ifdef CONFIG_FUTEX p->robust_list = NULL; #ifdef CONFIG_COMPAT p->compat_robust_list = NULL; #endif INIT_LIST_HEAD(&p->pi_state_list); p->pi_state_cache = NULL; #endif /* * sigaltstack should be cleared when sharing the same VM */ if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM) p->sas_ss_sp = p->sas_ss_size = 0; /* * Syscall tracing should be turned off in the child regardless * of CLONE_PTRACE. */ clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE); #ifdef TIF_SYSCALL_EMU clear_tsk_thread_flag(p, TIF_SYSCALL_EMU); #endif clear_all_latency_tracing(p); /* ok, now we should be set up.. */ p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL); p->pdeath_signal = 0; p->exit_state = 0; /* * Ok, make it visible to the rest of the system. * We dont wake it up yet. */ p->group_leader = p; INIT_LIST_HEAD(&p->thread_group); /* Now that the task is set up, run cgroup callbacks if * necessary. We need to run them before the task is visible * on the tasklist. */ cgroup_fork_callbacks(p); cgroup_callbacks_done = 1; /* Need tasklist lock for parent etc handling! */ write_lock_irq(&tasklist_lock); /* CLONE_PARENT re-uses the old parent */ if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) { p->real_parent = current->real_parent; p->parent_exec_id = current->parent_exec_id; } else { p->real_parent = current; p->parent_exec_id = current->self_exec_id; } spin_lock(¤t->sighand->siglock); /* * Process group and session signals need to be delivered to just the * parent before the fork or both the parent and the child after the * fork. Restart if a signal comes in before we add the new process to * it's process group. * A fatal signal pending means that current will exit, so the new * thread can't slip out of an OOM kill (or normal SIGKILL). */ recalc_sigpending(); if (signal_pending(current)) { spin_unlock(¤t->sighand->siglock); write_unlock_irq(&tasklist_lock); retval = -ERESTARTNOINTR; goto bad_fork_free_pid; } if (clone_flags & CLONE_THREAD) { atomic_inc(¤t->signal->count); atomic_inc(¤t->signal->live); p->group_leader = current->group_leader; list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group); } if (likely(p->pid)) { list_add_tail(&p->sibling, &p->real_parent->children); tracehook_finish_clone(p, clone_flags, trace); if (thread_group_leader(p)) { if (clone_flags & CLONE_NEWPID) p->nsproxy->pid_ns->child_reaper = p; p->signal->leader_pid = pid; tty_kref_put(p->signal->tty); p->signal->tty = tty_kref_get(current->signal->tty); attach_pid(p, PIDTYPE_PGID, task_pgrp(current)); attach_pid(p, PIDTYPE_SID, task_session(current)); list_add_tail_rcu(&p->tasks, &init_task.tasks); __get_cpu_var(process_counts)++; } attach_pid(p, PIDTYPE_PID, pid); nr_threads++; } total_forks++; spin_unlock(¤t->sighand->siglock); write_unlock_irq(&tasklist_lock); proc_fork_connector(p); cgroup_post_fork(p); perf_event_fork(p); return p; bad_fork_free_pid: if (pid != &init_struct_pid) free_pid(pid); bad_fork_cleanup_io: if (p->io_context) exit_io_context(p); bad_fork_cleanup_namespaces: exit_task_namespaces(p); bad_fork_cleanup_mm: if (p->mm) mmput(p->mm); bad_fork_cleanup_signal: if (!(clone_flags & CLONE_THREAD)) __cleanup_signal(p->signal); bad_fork_cleanup_sighand: __cleanup_sighand(p->sighand); bad_fork_cleanup_fs: exit_fs(p); /* blocking */ bad_fork_cleanup_files: exit_files(p); /* blocking */ bad_fork_cleanup_semundo: exit_sem(p); bad_fork_cleanup_audit: audit_free(p); bad_fork_cleanup_policy: perf_event_free_task(p); #ifdef CONFIG_NUMA mpol_put(p->mempolicy); bad_fork_cleanup_cgroup: #endif cgroup_exit(p, cgroup_callbacks_done); delayacct_tsk_free(p); module_put(task_thread_info(p)->exec_domain->module); bad_fork_cleanup_count: atomic_dec(&p->cred->user->processes); exit_creds(p); bad_fork_free: free_task(p); fork_out: return ERR_PTR(retval); }
进程退出
进程退出的方式有很多(UNIX环境高级编程中总结了8种),但最后答案都要靠do_exit()来完成。do_exit()在内核中定义:
void do_exit(long code) { struct task_struct *tsk = current; int group_dead; profile_task_exit(tsk); WARN_ON(atomic_read(&tsk->fs_excl)); if (unlikely(in_interrupt())) panic("Aiee, killing interrupt handler!"); if (unlikely(!tsk->pid)) panic("Attempted to kill the idle task!"); /* * If do_exit is called because this processes oopsed, it's possible * that get_fs() was left as KERNEL_DS, so reset it to USER_DS before * continuing. Amongst other possible reasons, this is to prevent * mm_release()->clear_child_tid() from writing to a user-controlled * kernel address. */ set_fs(USER_DS); tracehook_report_exit(&code); validate_creds_for_do_exit(tsk); /* * We're taking recursive faults here in do_exit. Safest is to just * leave this task alone and wait for reboot. */ if (unlikely(tsk->flags & PF_EXITING)) { printk(KERN_ALERT "Fixing recursive fault but reboot is needed!\n"); /* * We can do this unlocked here. The futex code uses * this flag just to verify whether the pi state * cleanup has been done or not. In the worst case it * loops once more. We pretend that the cleanup was * done as there is no way to return. Either the * OWNER_DIED bit is set by now or we push the blocked * task into the wait for ever nirwana as well. */ tsk->flags |= PF_EXITPIDONE; set_current_state(TASK_UNINTERRUPTIBLE); schedule(); } exit_irq_thread(); exit_signals(tsk); /* sets PF_EXITING */ /* * tsk->flags are checked in the futex code to protect against * an exiting task cleaning up the robust pi futexes. */ smp_mb(); spin_unlock_wait(&tsk->pi_lock); if (unlikely(in_atomic())) printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n", current->comm, task_pid_nr(current), preempt_count()); acct_update_integrals(tsk); group_dead = atomic_dec_and_test(&tsk->signal->live); if (group_dead) { hrtimer_cancel(&tsk->signal->real_timer); exit_itimers(tsk->signal); if (tsk->mm) setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm); } acct_collect(code, group_dead); if (group_dead) tty_audit_exit(); if (unlikely(tsk->audit_context)) audit_free(tsk); tsk->exit_code = code; taskstats_exit(tsk, group_dead); exit_mm(tsk); if (group_dead) acct_process(); trace_sched_process_exit(tsk); exit_sem(tsk); exit_files(tsk); exit_fs(tsk); check_stack_usage(); exit_thread(); cgroup_exit(tsk, 1); if (group_dead && tsk->signal->leader) disassociate_ctty(1); module_put(task_thread_info(tsk)->exec_domain->module); proc_exit_connector(tsk); /* * Flush inherited counters to the parent - before the parent * gets woken up by child-exit notifications. */ perf_event_exit_task(tsk); exit_notify(tsk, group_dead); #ifdef CONFIG_NUMA mpol_put(tsk->mempolicy); tsk->mempolicy = NULL; #endif #ifdef CONFIG_FUTEX if (unlikely(current->pi_state_cache)) kfree(current->pi_state_cache); #endif /* * Make sure we are holding no locks: */ debug_check_no_locks_held(tsk); /* * We can do this unlocked here. The futex code uses this flag * just to verify whether the pi state cleanup has been done * or not. In the worst case it loops once more. */ tsk->flags |= PF_EXITPIDONE; if (tsk->io_context) exit_io_context(tsk); if (tsk->splice_pipe) __free_pipe_info(tsk->splice_pipe); validate_creds_for_do_exit(tsk); preempt_disable(); exit_rcu(); /* causes final put_task_struct in finish_task_switch(). */ tsk->state = TASK_DEAD; schedule(); BUG(); /* Avoid "noreturn function does return". */ for (;;) cpu_relax(); /* For when BUG is null */ }
如果想对进程管理有更深入的了解,请参考《UNIX环境高级编程》中第七章和第八章,当然,要深入的理解进程本质,内核源码是少不了滴!